Машинное обучение агентов в Unity
- Перевод
- Tutorial
Эта статья об агентах машинного обучения в Unity написана Майклом Лэнхемом — техническим новатором, активным разработчиком под Unity, консультантом, менеджером и автором многих игр на движке Unity, графических проектов и книг.
Разработчики Unity внедрили поддержку машинного обучения и в частности глубинного обучения с подкреплением ради создания SDK глубинного обучения с подкреплением (deep reinforcement learning, DRL) для разработчиков игр и симуляций. К счастью, команда Unity под руководством Дэнни Лэнджа успешно реализована надёжный и современный движок DRL, способный показывать впечатляющие результаты. В качестве основы движка DRL Unity использует модель proximal policy optimization (PPO); эта модель значительно сложнее и в некоторых аспектах может отличаться.
В этой статье я познакомлю вас с инструментами и SDK для создания агентов DRL в играх и симуляциях. Несмотря на новизну и мощь этого инструмента, его легко использовать и он имеет вспомогательные инструменты, позволяющие осваивать концепции машинного обучения на ходу. Для работы с туториалом необходимо установить движок Unity.
Для чего можно использовать машинное обучение
Описательное применение относится к записи и анализу статистических данных для расширения возможностей бизнес-аналитики. Руководители получают описание и максимально информативный анализ результатов и последствий прошлых действий и решений. Этот процесс в настоящее время обычен для большинства крупных компаний по всему миру — например, анализ продаж и рекламных проектов для определения их результатов и рентабельности.
Второе применение машинного обучения — прогнозирование. Сбор данных и их использование для прогнозирования конкретного результата позволяет повысить скорость реакции и быстрее принимать верные решения. Например, прогнозирование оттока клиентов может помочь его предотвратить. Сегодня этот процесс применяется в большинстве крупных компаний.
Третье и наиболее продвинутое применение машинного обучения внедряется уже существующими компаниями и совершенствуется усилиями недавно созданных. Простого прогнозирования результатов или поведения уже недостаточно для эффективного ведения бизнеса. Понимание причин, мотивов и окружающей ситуации — вот необходимое условие для принятия оптимального решения. Этот метод наиболее эффективен, если человек и машина объединяют усилия. Машинное обучение используется для поиска значимых зависимостей и прогнозирования результатов, а специалисты по данным интерпретируют результат, чтобы понять, почему такая связь существует. В результате становится возможным принимать более точные и верные решения.
Кроме того, я бы добавил еще одно применение машинного обучения, отличное от прогнозного: автоматизация процессов. Прочесть об этом можно .
Вот несколько примеров задач, которые решает машинное обучение.
Логистика и производство
- В Rethink Robotics используют машинное обучение для обучения манипуляторов и увеличения скорости производства;
- В JaybridgeRobotics автоматизируют промышленные транспортные средства промышленного класса для более эффективной работы;
- В Nanotronics автоматизируют оптические микроскопы для улучшения результатов осмотра;
- Netflix и Amazon оптимизируют распределение ресурсов в соответствии с потребностями пользователей;
- Другие примеры: прогнозирование потребностей ERP/ERM; прогнозирование сбоев и улучшение техобслуживания, улучшение контроля качества и увеличение мощности производственной линии.
Продажи и маркетинг
- 6sense прогнозирует, какой лид и в какое время наиболее склонен к покупке;
- Salesforce Einstein помогает предвидеть возможности для продаж и автоматизировать задачи;
- Fusemachines автоматизирует планы продаж с помощью AI;
- AirPR предлагает пути повышения эффективности PR;
- Retention Science предлагает кросс-канальное вовлечение;
- Другие примеры: прогнозирование стоимости жизненного цикла клиента, повышение точности сегментации клиентов, выявление клиентских моделей покупок, и оптимизация опыта пользователя в приложениях.
Финансы
- Cerebellum Capital and Sentient используют машинное обучение для улучшения процесса принятия инвестиционных решений;
- Dataminr может помочь с текущими финансовыми решениями, заранее оповещая о социальных тенденциях и последних новостях;
- Другие примеры: выявление случаев мошенничества и прогнозирование цен на акции.
Здравоохранение
- Atomwise использует прогнозные модели для уменьшения времени производства лекарств;
- Deep6 Analytics определяет подходящих пациентов для клинических испытаний;
- Другие примеры: более точная диагностика заболеваний, улучшение персонализированного ухода и оценка рисков для здоровья.
Больше примеров использования машинного обучения, искусственного интеллекта и других связанных с ними ресурсов вы найдете в списке, созданном Sam DeBrule.
Читать еще: «10 типов структур данных, которые нужно знать»
Дерево решений и Случайный лес (Decision Trees and Random Forests)
деревья решений Случайный лес
Что такое древовидный метод?
- Узлы (Nodes): места, где дерево разделяется в зависимости от значения определенного параметра
- Грани (Edges): результат разделения, ведущий к следующему узлу
- Корень (Root) — узел, с которого начинается разделение дерева
- Листья (Leaves) — заключительные узлы, которые предсказывают финальный результат
Подведем итог
- Пример задачи, решение которой можно спрогнозировать с помощью дерева решений
- Элементы дерева решений: узлы, грани, корни и листья
- Как использование случайного набора характеристик позволяет нам построить случайный лес
- Почему использование случайного леса для декорреляции переменных может быть полезным для уменьшения дисперсии полученной модели
Как мы отказались от нейросетей, а затем вернули их в прогноз осадков Яндекс.Погоды
Мы уже рассказывали, как Яндекс.Погода делает сверхкраткосрочный прогноз осадков по метеорологическим радарам и спутниковым наблюдениям. Сегодня расскажем, как нам удалось поднять качество такого прогноза за счет внедрения нейросетевых подходов и почему мы уже отказывались от них в прошлом. А ещё вы узнаете, как мы улучшали визуальное восприятие самой карты на границе радарных и спутниковых наблюдений.





И снова про наукастинг
Когда мы говорим о прогнозе погоды, то чаще всего подразумеваем температуру и осадки, например, на завтра или ближайшие выходные. В этом случае хватает традиционных погодных трендов
Но если вы идёте обедать на улицу или на прогулку с ребёнком и при этом не хотите попасть под дождь, то важно знать точный момент начала дождя в течение ближайшего получаса. В таких ситуациях приходит на помощь наша карта осадков aka nowcasting.Рисунок 1
Карта осадков Яндекс.Погоды
Что покупать для глубокого обучения: личный опыт и советы использования GPU
Перевод
Перевод статьи Тима Деттмерса, кандидата наук из Вашингтонского университета, специалиста по глубокому обучению и обработке естественного языка
Глубокое обучение (ГО) – область с повышенными запросами к вычислительным мощностям, поэтому ваш выбор GPU фундаментально определит ваш опыт в этой области
Но какие свойства важно учесть, если вы покупаете новый GPU? Память, ядра, тензорные ядра? Как сделать лучший выбор по соотношению цены и качества? В данной статье я подробно разберу все эти вопросы, распространённые заблуждения, дам вам интуитивное представление о GPU а также несколько советов, которые помогут вам сделать правильный выбор.
Статья написана так, чтобы дать вам несколько разных уровней понимания GPU, в т.ч. новой серии Ampere от NVIDIA
У вас есть выбор:
- Если вам не интересны детали работы GPU, что именно делает GPU быстрым, чего уникального есть в новых GPU серии NVIDIA RTX 30 Ampere – можете пропустить начало статьи, вплоть до графиков по быстродействию и быстродействию на $1 стоимости, а также раздела рекомендаций. Это ядро данной статьи и наиболее ценное содержимое.
- Если вас интересуют конкретные вопросы, то наиболее частые из них я осветил в последней части статьи.
- Если вам нужно глубокое понимание того, как работают GPU и тензорные ядра, лучше всего будет прочесть статью от начала и до конца. В зависимости от ваших знаний по конкретным предметам вы можете пропустить главу-другую.
Каждая секция предваряется небольшим резюме, которое поможет вам решить, читать её целиком или нет.
Пара слов напоследок
Когда новички видят всё разнообразие алгоритмов, они задаются стандартным вопросом: «А какой следует использовать мне?» Ответ на этот вопрос зависит от множества факторов:
- Размер, качество и характер данных;
- Доступное вычислительное время;
- Срочность задачи;
- Что вы хотите делать с данными.
Даже опытный data scientist не скажет, какой алгоритм будет работать лучше, прежде чем попробует несколько вариантов. Существует множество других алгоритмов машинного обучения, но приведённые выше — наиболее популярные. Если вы только знакомитесь с машинным обучением, то они будут хорошей отправной точкой.




Алгоритм тегирования (классификации) менеджеров: как это выведет аналитику на новый уровень
Анализ эффективности рекламных источников – это не единственная задача интернет-аналитики. Сюда входит и оценка работы сотрудников, которые обрабатывают полученные лиды.
Очень часто бывает, когда конверсий много, их цена приемлема, а продажи не растут и даже падают. Здесь аналитики «до прибыли с клика» уже не хватает, чтобы выяснить причину. И тогда на помощь приходит анализ «до прибыли с менеджера». Потому что как бы идеально не была настроена реклама, клиенты сначала взаимодействуют с менеджерами, а уже потом принимают решение. Именно от качества работы сотрудников зависит успешность вашего бизнеса.
Традиционные системы аналитики используют CRM, чтобы зафиксировать факт продажи/обращения с менеджером. Однако такой подход лишь частично решает задачу: оценивает эффективность сотрудника «в сухом остатке». То есть показывает продажи и конверсию, но оставляет «за бортом» само общение с клиентом. А ведь от уровня коммуникаций и зависит результат.
Чтобы заполнить «пробел» мы разработали инструмент, который автоматически свяжет каждый звонок с обработавшим его менеджером. Не придется привлекать CRM и сторонние сервисы. По сути, наша система ставит тег «имя менеджера» на каждый входящий звонок.
Так руководители отдела продаж/клиентского сервиса проконтролируют качество работы, найдут проблемные участки и построят аналитику. В этом поможет быстрое сегментирование звонков на тех менеджеров, которые их принимают.
8 лучших трендов International Conference on Learning Representations (ICLR) 2019
Перевод
Тема анализа данных и Data Science в наши дни развивается с поразительной скоростью. Для того, чтобы понимать актуальность своих методов и подходов, необходимо быть в курсе работ коллег, и именно на конференциях удается получить информацию о трендах современности. К сожалению, не все мероприятия можно посетить, поэтому статьи о прошедших конференциях представляют интерес для специалистов, не нашедших времени и возможности для личного присутствия. Мы рады представить вам перевод статьи Чип Хен (Chip Huyen) о конференции ICLR 2019, посвященной передовым веяниям и подходам в области Data Science.
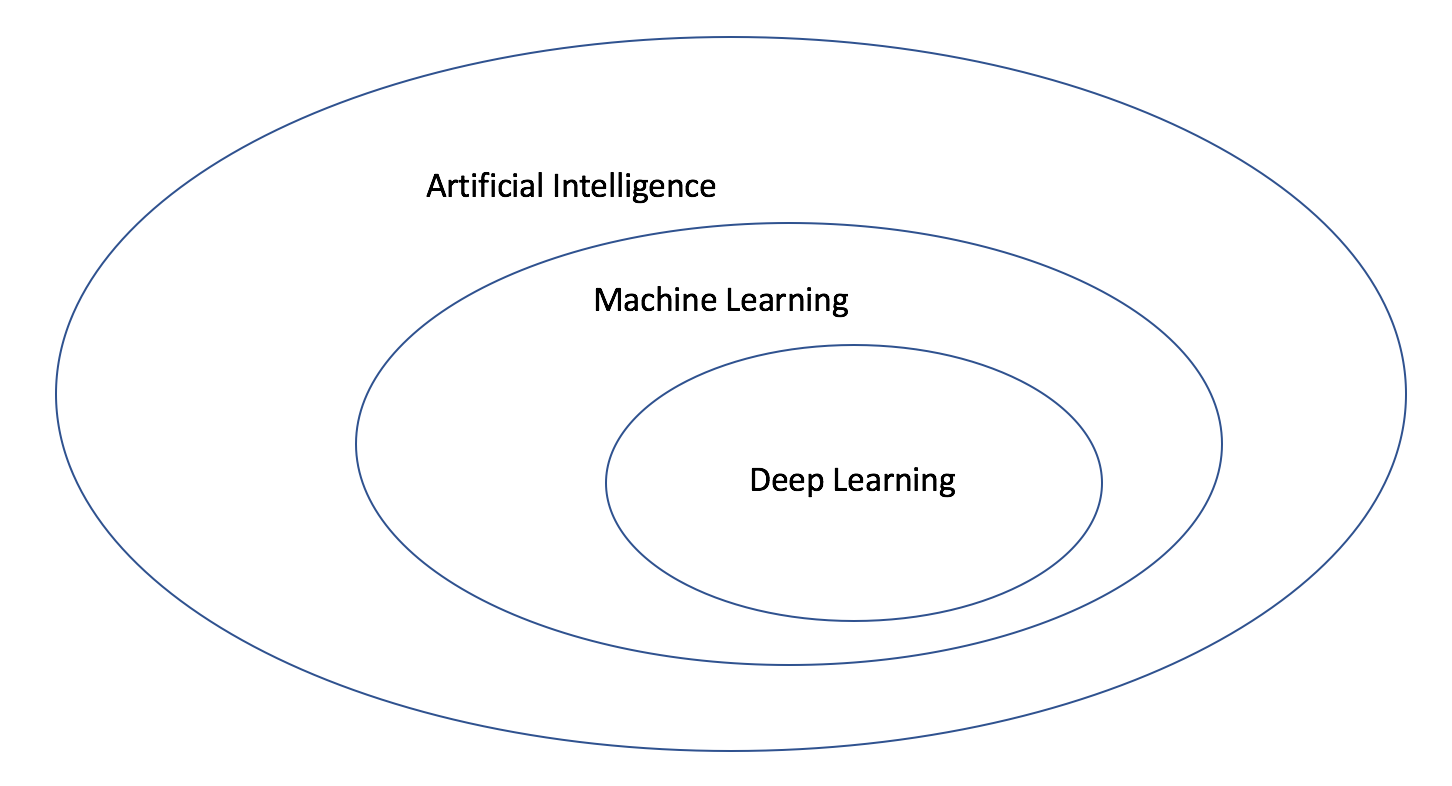
Глубинное обучение
Сейчас алгоритмы машинного обучения можно условно разделить на традиционные и методы глубинного обучения (это общее название для разного вида многослойных нейронных сетей). Для успешной работы традиционных алгоритмов очень важен такой этап предобработки данных, как feature engineering (для этого термина нет конвенционального перевода на русский язык; грубо его можно перевести как конструирование признаков). Это процесс формирования и отбора признаков. Как правило, работа с признаками – это трудоемкий, времязатратный процесс, который требует глубокого погружения в предметную область решаемой задачи.
Джереми Говард, один из авторов известного курса про глубинное обучение fast.ai, приводит следующий пример. Команда специалистов из Стенфорда во главе с ученым Эндрю Бэком занималась исследованием рака молочной железы. Чтобы построить модель, способную предсказывать выживет пациентка с опухолью или нет, им пришлось изучить огромное количество снимков биопсий молочной железы. Таким образом они определили, какие паттерны на снимках могут быть связаны со смертью пациентки и сформировали сотни сложных признаков, таких как связь между соседними эпителиальными клетками. Затем команда программистов разработала алгоритмы для правильного распознавания этих признаков со снимков.
Принципиальное отличие глубинного обучения в том, что оно способно взять большую часть работы по формированию признаков на себя, используя только единообразно представленные входные данные без вручную выделенных сложных признаков. В случае прогнозирования смерти от рака молочной железы медицинские снимки можно представлять просто в виде последовательности яркостей отдельных пикселей. Многослойные нейросети с каждым слоем способны объединять пиксели во все более полезные уровни абстракции. Таким образом они получают представление об изображении в целом, а также о его частях, влияющих на конечное предсказание (например, опухоль и ее размеры).
Как научить нейросеть воспроизводить игровую физику
Перевод
Практически в любой современной компьютерной игре наличие какого-либо физического движка является обязательным условием. Развевающиеся на ветру флаги и кролики, бомбардируемые шарами, ― всё это требует надлежащего исполнения. И, конечно, пусть не все герои носят плащи… но те, кто носят, действительно нуждаются в наличии адекватной симуляции развевающейся ткани.
И всё же полное физическое моделирование таких взаимодействий часто становится невозможным, поскольку оно на порядки медленнее необходимого для игр в реальном времени. Данная статья предлагает новый метод моделирования, который может ускорить физические симуляции, сделать их в 300-5000 раз быстрее. Цель его состоит в том, чтобы попытаться научить имитации физических сил нейронную сеть.
Samsung открывает бесплатный онлайн-курс по нейросетям в задачах компьютерного зрения
Вы пока не разбираетесь, почему ReLU лучше сигмоиды, чем отличается Rprop от RMSprop, зачем нормализировать сигналы и что такое skip connection? Зачем нейронной сети нужен граф, и какую он совершил ошибку, что она распространяется обратно? У вас есть проект с компьютерным зрением или, может быть, делаете межгалактического робота для борьбы с грязными тарелками, и хотите, чтобы он мог сам решать, отмывать или и так сойдет?
Мы запускаем открытый курс «Нейронные сети и компьютерное зрение», который адресован тем, кто в этой области делает первые шаги. Курс разработан экспертами Samsung Research Russia: Исследовательского центра Samsung и Центра искусственного интеллекта Samsung в Москве. Сильные стороны курса:






- авторы курса знают, о чем говорят: это инженеры московского Центра искусственного интеллекта Samsung, Михаил Романов и Игорь Слинько;
- есть как теория с задачками, так и практика на PyTorch
- приступаем к практике сразу после освоения минимальных теоретических знаний.
- лучшие студенты будут приглашены на собеседование в Samsung Research Russia!
Машинное обучение — это…
Вот самое простое определение, которое я нашел:
Машинное обучение — это « класс методов искусственного интеллекта, которые позволяют улучшить результаты работы компьютеров путем обучения на известных данных», — Berkeley.
Теперь давайте разложим все по полочкам, чтобы выстроить основы знаний в области машинного обучения.
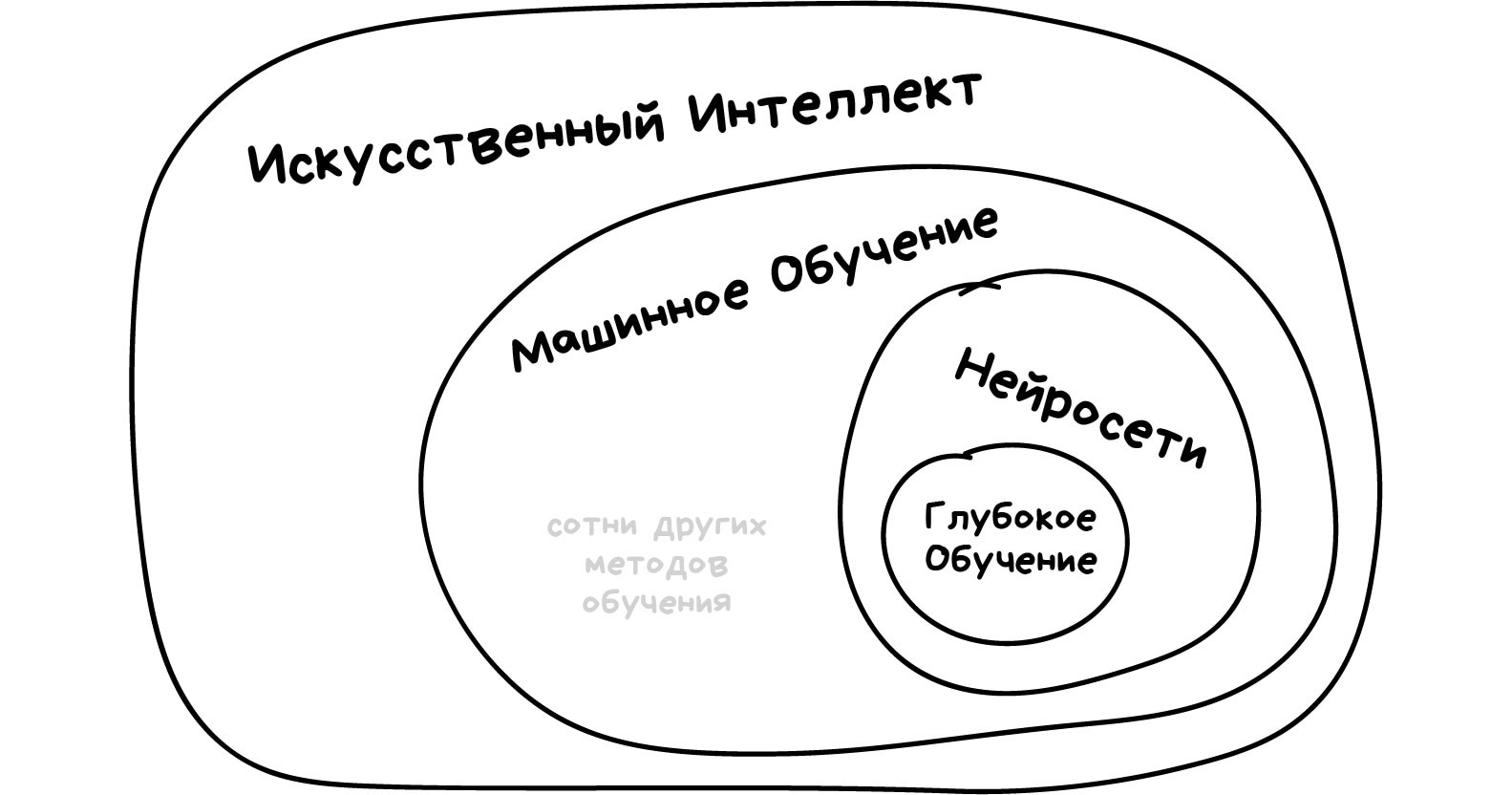
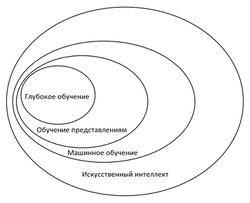
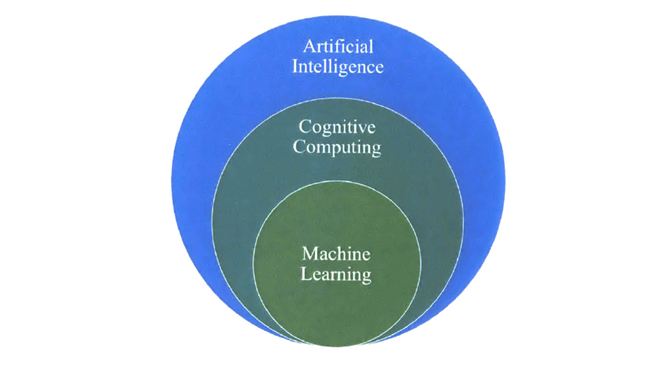
…подраздел искусственного интеллекта (ИИ)
ИИ — это наука и технология по разработке мероприятий и методов, позволяющих компьютерам успешно выполнять задачи, которые обычно требуют интеллектуального осмысления человека. Машинное обучение — часть этого процесса: это методы и технологии, с помощью которых можно обучит компьютер выполнять поставленные задачи.
…способ решения практических задач
Методы машинного обучения все еще в развитии. Некоторые уже изучены и используются (рассмотрим дальше), но ожидается, что со временем их количество будет только расти. Идея в том, что совершенно разные методы используются для совершенно разных компьютеров, а различные бизнес-задачи требуют различных методов машинного обучения.
… способ увеличить эффективность компьютеров
Для решения компьютером задач с применением искусственного интеллекта нужны практика и автоматическая поднастройка. Модель машинного обучения нуждается в тренировке с использованием базы данных и в большинстве ситуаций — в подсказке человека.
…технология, основанная на опыте
ИИ нуждается в предоставлении опыта — иными словами, ему необходимы данные. Чем больше в систему ИИ поступает данных, тем точнее компьютер взаимодействует с ними, а также с теми данными, что получает в дальнейшем. Чем выше точность взаимодействия, тем успешнее будет выполнение поставленной задачи, и выше степень прогностической точности.
Простой пример:
- Выбираются входные данные и задаются условия ввода (например, банковские операции с использованием карт).
- Строится алгоритм машинного обучения и настраивается на конкретную задачу (например, выявлять мошеннические транзакции).
- Используемые в ходе обучения данные дополняются желаемой выходной информацией (например, эти транзакции — мошеннические, а эти нет).
Ограниченность нейронных сетей
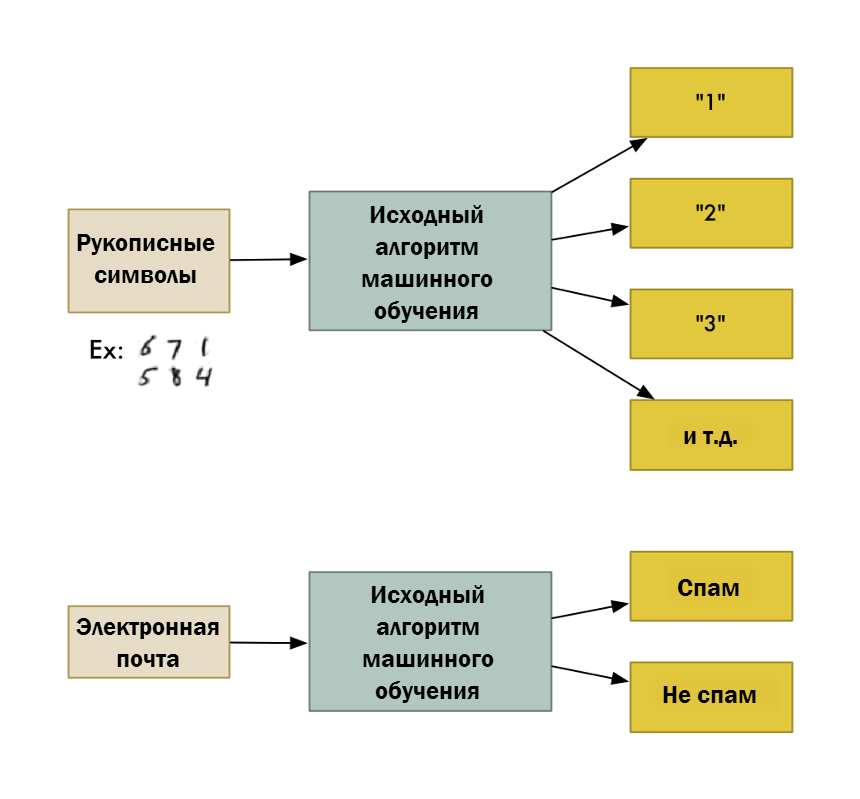
Впрочем, в нейронных сетях нет ничего магического и в большинстве случаев опасения касательно сценария «Терминатора» не имеют под собой оснований. Допустим, учёные натренировали нейронную сеть на распознавание рукописных цифр (такое приложение может использовать, скажем, на почте). Как может работать такое приложение и почему здесь не о чем беспокоиться?







Допустим, мы работаем с изображениями 20×20 пикселей, где каждый пиксель представляется оттенком серого (всего 256 возможных значений). В качестве ответа у нас имеется одна из цифр: от 0 до 9. Структура нейронной сети будет следующая: в первом слое будет 400 нейронов, где значение каждого нейрона будет равно интенсивности соответствующего пикселя. В последнем слое будет 10 нейронов, где в каждом нейроне будет вероятность того, что на изначальном изображении нарисована соответствующая цифра. Между ними будет некоторое число слоев (такие слоя называются скрытыми) с одинаковым количеством нейронов, где каждый нейрон соединён с нейроном из предыдущего слоя и ни с какими более.
Рёбрам нейронной сети (на картинке они показаны как стрелочки) будут соответствовать некоторые числа. Причем значение в нейроне будет считаться как следующая сумма: значение нейрона из предыдущего слоя * значение ребра, соединяющего нейроны. Затем от данной суммы берётся определенная функция (например, сигмоидная функция, о которой мы говорили ранее).
В конечном итоге задача тренировки нейронной сети заключается в том, чтобы подобрать такие значения в ребрах, чтобы отдавая первому слою нейронной сети интенсивности пикселей, на последнем слое мы получали вероятности того, что на изображении нарисована какая-то цифра.
Более простыми словами, в данном случае нейронная сеть представляет собой вычисление математической функции, где аргументы — это другие математические функции, которые зависят от других математических функций и так далее. Разумеется, при подобном вычислении математических функций, где подгоняются некоторые аргументы, ни о каком экзистенциальном риске речи идти не может.
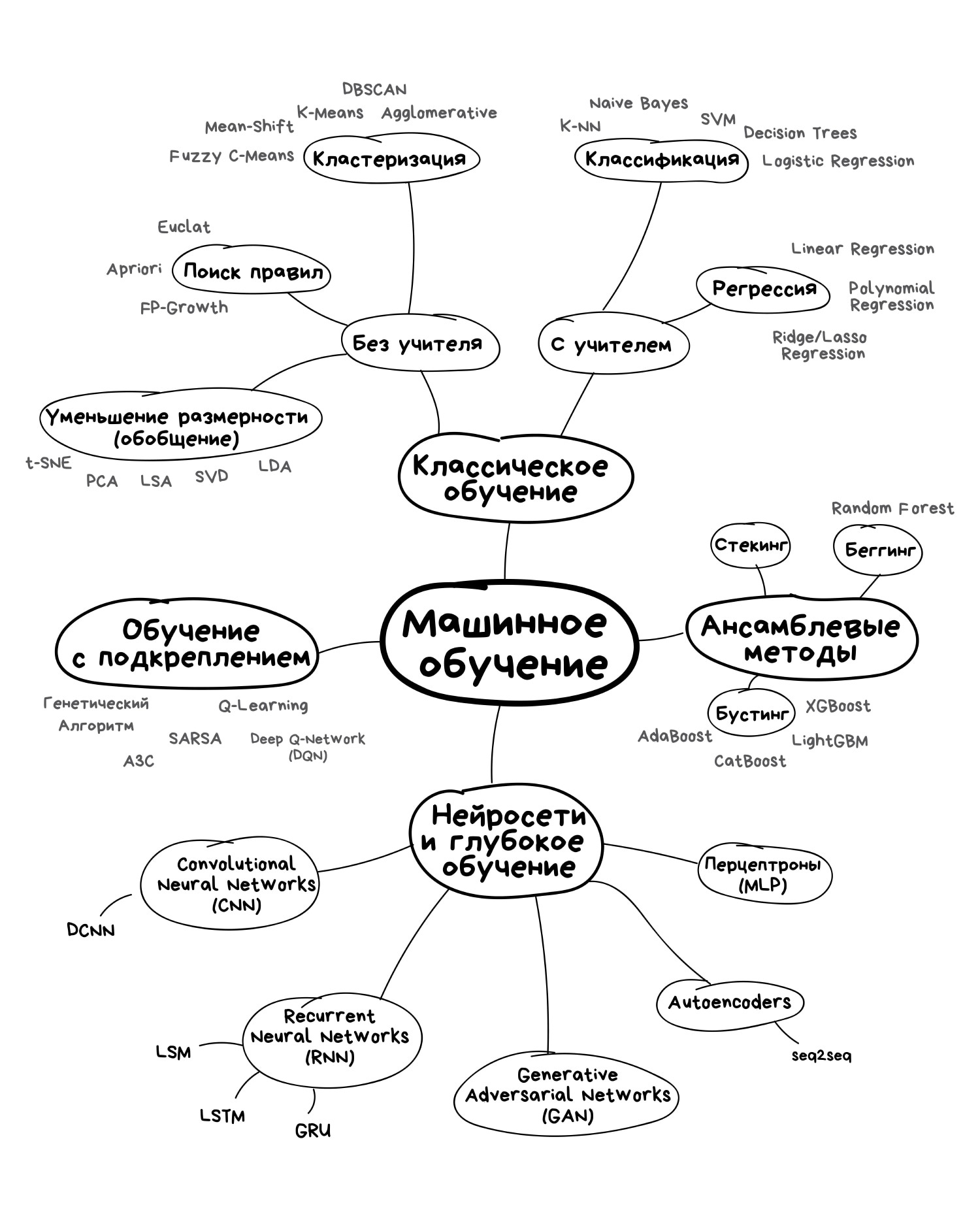
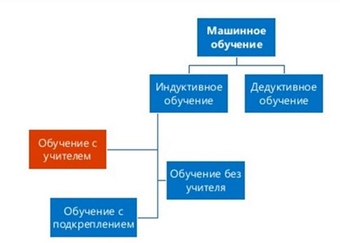
Способы машинного обучения
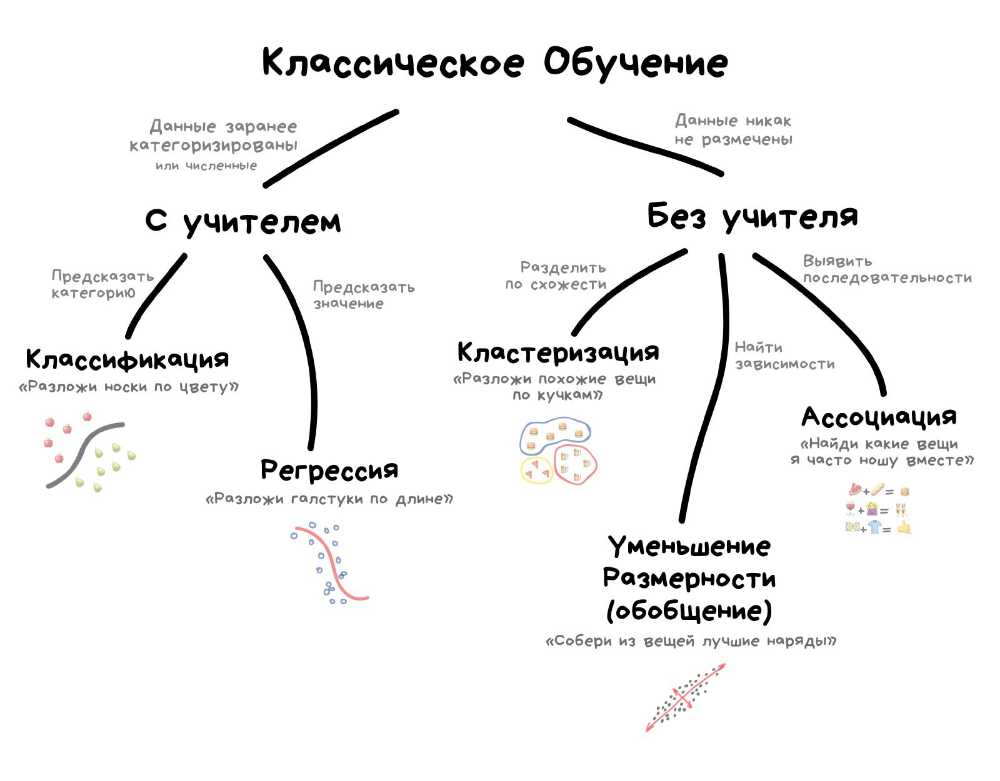
Раздел машинного обучения, с одной стороны, образовался в результате разделения науки о нейросетях на методы обучения сетей и виды топологий их архитектуры, с другой стороны — вобрал в себя методы математической статистики. Указанные ниже способы машинного обучения исходят из случая использования нейросетей, хотя существуют и другие методы, использующие понятие обучающей выборки — например, дискриминантный анализ, оперирующий обобщённой дисперсией и ковариацией наблюдаемой статистики, или байесовские классификаторы. Базовые виды нейросетей, такие как перцептрон и многослойный перцептрон (а также их модификации), могут обучаться как с учителем, так и без учителя, с подкреплением и самоорганизацией. Но некоторые нейросети и большинство статистических методов можно отнести только к одному из способов обучения. Поэтому, если нужно классифицировать методы машинного обучения в зависимости от способа обучения, будет некорректным относить нейросети к определенному виду, правильнее было бы типизировать алгоритмы обучения нейронных сетей.
Обучение с учителем — для каждого прецедента задаётся пара «ситуация, требуемое решение»:
-
Искусственная нейронная сеть
- Глубокое обучение
- Метод коррекции ошибки
- Метод обратного распространения ошибки
- Метод опорных векторов
Обучение без учителя — для каждого прецедента задаётся только «ситуация», требуется сгруппировать объекты в кластеры, используя данные о попарном сходстве объектов, и/или понизить размерность данных:
- Альфа-система подкрепления
- Гамма-система подкрепления
- Метод ближайших соседей
Обучение с подкреплением — для каждого прецедента имеется пара «ситуация, принятое решение»:
- Генетический алгоритм.
- Активное обучение — отличается тем, что обучаемый алгоритм имеет возможность самостоятельно назначать следующую исследуемую ситуацию, на которой станет известен верный ответ:
- Обучение с частичным привлечением учителя (англ. semi-supervised learning) — для части прецедентов задается пара «ситуация, требуемое решение», а для части — только «ситуация»
- Трансдуктивное обучение (англ. transduction (machine learning)) — обучение с частичным привлечением учителя, когда прогноз предполагается делать только для прецедентов из тестовой выборки
- Многозадачное обучение (англ. multi-task learning) — одновременное обучение группе взаимосвязанных задач, для каждой из которых задаются свои пары «ситуация, требуемое решение»
- Многовариантное обучение (англ. multiple-instance learning) — обучение, когда прецеденты могут быть объединены в группы, в каждой из которых для всех прецедентов имеется «ситуация», но только для одного из них (причем, неизвестно какого) имеется пара «ситуация, требуемое решение»
- Бустинг (англ. boosting — улучшение) — это процедура последовательного построения композиции алгоритмов машинного обучения, когда каждый следующий алгоритм стремится компенсировать недостатки композиции всех предыдущих алгоритмов.
- Байесовская сеть
Как я заработал 1 000 000 $ без опыта и связей, а потом потратил их, чтобы сделать свой переводчик
Как все начиналось
Эта история началась 15 лет назад. Работая программистом в столице, я накапливал деньги и увольнялся, чтобы потом создавать собственные проекты. Для экономии средств уезжал домой, в небольшой родной город, где работал над сайтом для студентов, программой для торговли, играми для мобильных телефонов. Но из-за отсутствия опыта ведения бизнеса это не приносило дохода, и вскоре проекты закрывались. Приходилось снова ехать в столицу и устраиваться на работу. Эта история повторилась несколько раз.
Когда у меня в очередной раз закончились деньги, наступил кризис. Я не смог найти работу, ситуация стала критической. Пришло время посмотреть на все вещи трезвым взглядом. Нужно было честно признаться себе, что я не знаю, какие ниши выбрать для бизнеса. Создавать проекты, которые просто нравятся, — путь в никуда.




Аппаратное ускорение глубоких нейросетей: GPU, FPGA, ASIC, TPU, VPU, IPU, DPU, NPU, RPU, NNP и другие буквы
14 мая, когда Трамп готовился спустить всех собак на Huawei, я мирно сидел в Шеньжене на Huawei STW 2019 — большой конференции на 1000 участников — в программе которой были доклады Филипа Вонга, вице-президента по исследованиям TSMC по перспективам не-фон-неймановских вычислительных архитектур, и Хенга Ляо, Huawei Fellow, Chief Scientist Huawei 2012 Lab, на тему разработки новой архитектуры тензорных процессоров и нейропроцессоров. TSMC, если знаете, делает нейроускорители для Apple и Huawei по технологии 7 nm (которой мало кто владеет), а Huawei по нейропроцессорам готова составить серьезную конкуренцию Google и NVIDIA.
Google в Китае забанен, поставить VPN на планшет я не удосужился, поэтому патриотично пользовался Яндексом для того, чтобы смотреть, какая ситуация у других производителей аналогичного железа, и что вообще происходит. В общем-то за ситуацией я следил, но только после этих докладов осознал, насколько масштабна готовящаяся в недрах компаний и тиши научных кабинетов революция.
Только в прошлом году в тему было вложено больше 3 миллиардов долларов. Google уже давно объявил нейросети стратегическим направлением, активно строит их аппаратную и программную поддержку. NVIDIA, почувствовав, что трон зашатался, вкладывает фантастические усилия в библиотеки ускорения нейросетей и новое железо. Intel в 2016 году потратил 0,8 миллиарда на покупку двух компаний, занимающихся аппаратным ускорением нейросетей. И это при том, что основные покупки еще не начались, а количество игроков перевалило за полсотни и быстро растет.
TPU, VPU, IPU, DPU, NPU, RPU, NNP — что все это означает и кто победит? Попробуем разобраться. Кому интересно — велкам под кат!







