Исследовательская деятельность по корпоративным приложениям
Первой исследовательской группой, явно сосредоточившейся на корпоративной семантической сети, была группа ACACIA из INRIA-Sophia-Antipolis , основанная в 2002 году. Результаты их работы включают поисковую машину Corese на основе RDF (S) и применение технологии семантической сети в область электронного обучения .
С 2008 года исследовательская группа корпоративной семантической сети, расположенная в Свободном университете Берлина , специализируется на строительных блоках: корпоративном семантическом поиске, корпоративном семантическом сотрудничестве и разработке корпоративных онтологий.
Инженерное исследование онтологий включает в себя вопрос о том, как привлечь неопытных пользователей к созданию онтологий и семантически аннотированного контента, а также для извлечения явных знаний из взаимодействия пользователей внутри предприятий.
Будущее приложений
Тим О’Рейли , придумавший термин Web 2.0, предложил долгосрочное видение семантической сети как сети данных, в которой сложные приложения манипулируют сетью данных. Сеть данных превращает всемирную паутину из распределенной файловой системы в распределенную систему баз данных.
Что такое семантическая сеть
СЕМАНТИЧЕСКАЯ СЕТЬ (Semantic Web) — набор форматов и языков, позволяющих находить во Всемирной паутине и анализировать данные, дающий пользователям возможность понимать все виды сетевой информации.
Семантическая сеть представляет собой не что-то отделенное от Всемирной паутины, а ее дополнение. Она начинает функционировать, когда люди объединенные общим делом, договариваются об общих схемах представления интересующей их информации. С появлением новых групп, разрабатывающих эти таксономии инструментарий семантической сети позволяет им связывать свои схемы и переводить термины, постепенно расширяя круг пользователей, веб-программы которых автоматически понимают друг друга.
Основные положения
· Для семантической сети появляются самые разнообразные приложения от мобильной телефонной службы Vodafone Live! До системы координирования работы поставщиков компании «Боинг».
· Ученые разрабатывают самые передовые приложения, в том числе систему выявляющую генетические причины сердечных заболеваний, а также систему раннего обнаружения эпидемий гриппа.
· Компании и университеты, работающие в рамках Веб-консорциума (World Wide Web Consortium) разрабатывают стандарты, которые должны сделать семантическую сеть более доступной и простой в использовании.
Использование семантических сетей
Семантизация
Семантизация — процесс изменения текстов, в которых выделяются семантические отношения без изменения их содержания. В Википедии существуют проекты по семантизации статей и Дерева категорий.
- Семантизация статей производится, в основном, путём использования шаблонов, при этом некоторые категории создаются автоматически.
- Семантизация Дерева категорий заключается в соблюдении транзитивности, создании метакатегорий и организации структуры подкатегорий, используя значимые критерии.
Семантическая паутина
Основная статья: Семантическая паутина
Концепция организации гипертекста напоминает однородную бинарную семантическую сеть, однако здесь есть существенное отличие:
- Связь, осуществляемая гиперссылкой, не имеет семантики, то есть не описывает смысла этой связи. Назначение семантической сети состоит в том, чтобы описать взаимосвязи объектов, а не дополнительную информацию по предметной области. Человек может разобраться, зачем нужна та или иная гиперссылка, но компьютеру эта связь не понятна.
- Страницы, связываемые гиперссылками, являются документами, описывающими, как правило, проблемную ситуацию в целом. В семантической сети вершины (то, что связывают отношения) представляют собой понятия или объекты реального мира.
Попытка создания семантической сети на основе Всемирной паутины получила название семантической паутины. Эта концепция подразумевает использование языка RDF (языка разметки на основе XML) и призвана придать ссылкам некий смысл, понятный компьютерным системам. Это позволит превратить Интернет в распределённую базу знаний глобального масштаба.
Приложения
Цель состоит в том, чтобы повысить удобство использования и полезность Интернета и его взаимосвязанных ресурсов путем создания семантических веб-сервисов , таких как:
Такие сервисы могут быть полезны для общедоступных поисковых систем или могут использоваться для управления знаниями внутри организации. Бизнес-приложения включают:
- Содействие интеграции информации из смешанных источников
- Устранение двусмысленности в корпоративной терминологии
- Улучшение поиска информации, тем самым уменьшая информационную перегрузку и повышая качество и точность получаемых данных
- Выявление релевантной информации относительно данного домена
- Поддержка принятия решений
В корпорации существует замкнутая группа пользователей, и руководство может обеспечить выполнение руководящих принципов компании, таких как принятие конкретных онтологий и использование семантической аннотации . По сравнению с общедоступной семантической сетью требования к масштабируемости меньше, а информации, циркулирующей внутри компании, можно доверять в целом; конфиденциальность не является проблемой вне обработки данных клиентов.
Скептические реакции
Практическая осуществимость
Критики ставят под сомнение базовую осуществимость полного или даже частичного выполнения Семантической паутины, указывая как на трудности ее создания, так и на отсутствие универсальной полезности, которая не позволяет вложить необходимые усилия. В статье 2003 года Маршалл и Шипман указывают на когнитивные накладные расходы, связанные с формализацией знаний по сравнению с созданием традиционного веб- гипертекста :
Согласно Маршаллу и Шипману, неявный и изменчивый характер многих знаний усугубляет проблему инженерии знаний и ограничивает применимость семантической паутины к определенным областям. Еще одна проблема, на которую они указывают, — это специфические для домена или организации способы выражения знаний, которые должны быть решены посредством соглашения сообщества, а не только техническими средствами. Как оказалось, специализированные сообщества и организации для внутрикорпоративных проектов имели тенденцию принимать технологии семантической паутины в большей степени, чем периферийные и менее специализированные сообщества. Практические ограничения для принятия оказались менее сложными там, где область и сфера применения более ограничены, чем у широкой публики и всемирной паутины.
Наконец, Маршалл и Шипман видят прагматические проблемы в идее интеллектуальных агентов (в стиле « Навигатор знаний» ), работающих в Семантической паутине, управляемой в основном вручную:
Критика Кори Доктороу (« метакрап ») исходит с точки зрения человеческого поведения и личных предпочтений. Например, люди могут включать в веб-страницы ложные метаданные, пытаясь ввести в заблуждение механизмы семантической паутины, которые наивно предполагают достоверность метаданных. Этот феномен был хорошо известен благодаря метатегам, которые обманом заставляли алгоритм ранжирования Altavista повышать рейтинг определенных веб-страниц: механизм индексации Google специально ищет такие попытки манипуляции. Питер Гарденфорс и Тимо Хонкела отмечают, что технологии семантической паутины, основанные на логике, охватывают лишь часть соответствующих явлений, связанных с семантикой.
Цензура и конфиденциальность
Энтузиазм по поводу семантической сети может быть смягчен опасениями относительно цензуры и конфиденциальности . Например, теперь можно легко обойти методы анализа текста , используя другие слова, например, метафоры, или изображения вместо слов. Усовершенствованная реализация семантической сети упростит для правительств контроль над просмотром и созданием онлайн-информации, поскольку эту информацию будет намного легче понять автоматизированной машине блокировки контента. Кроме того, поднимался вопрос о том, что при использовании файлов FOAF и метаданных геолокации будет очень мало анонимности, связанной с авторством статей о таких вещах, как личный блог. Некоторые из этих проблем были рассмотрены в проекте «Policy Aware Web», который является активной темой исследований и разработок.
Удвоение выходных форматов
Еще одна критика семантической паутины заключается в том, что создание и публикация контента займет гораздо больше времени, поскольку для одного фрагмента данных потребуется два формата: один для просмотра человеком, а другой — для машин. Однако многие разрабатываемые веб-приложения решают эту проблему, создавая машиночитаемый формат после публикации данных или запроса таких данных машиной. Разработка микроформатов была одной из реакций на такого рода критику. Еще один аргумент в защиту возможности семантической сети является вероятно падение цен задач человеческого интеллекта в цифровых рынков труда, таких как Amazon «s Mechanical Turk .
Такие спецификации, как eRDF и RDFa, позволяют встраивать произвольные данные RDF в HTML-страницы. Механизм GRDDL (Сбор описаний ресурсов из диалектов языка) позволяет автоматически интерпретировать существующий материал (включая микроформаты) как RDF, поэтому издателям нужно использовать только один формат, например HTML.
пример
В следующем примере текст «Пауль Шустер родился в Дрездене» на веб-сайте будет снабжен аннотацией, связывающей человека с местом его рождения. Следующий фрагмент HTML показывает, как описывается небольшой граф в RDFa -синтаксисе с использованием словаря schema.org и идентификатора Викиданных :
<div vocab="http://schema.org/" typeof="Person">
<span property="name">Paul Schuster</span> was born in
<span property="birthPlace" typeof="Place" href="http://www.wikidata.org/entity/Q1731">
<span property="name">Dresden</span>.
</span>
</div>

График, полученный из примера RDFa
В примере определены следующие пять троек (показаны в синтаксисе Turtle ). Каждая тройка представляет одно ребро в результирующем графе: первый элемент тройки ( субъект ) — это имя узла, с которого начинается ребро, второй элемент ( предикат ) — тип ребра, а последний и третий элемент ( объект ) либо имя узла, на котором заканчивается край, либо буквальное значение (например, текст, число и т. д.).
Результатом троек является график, показанный .
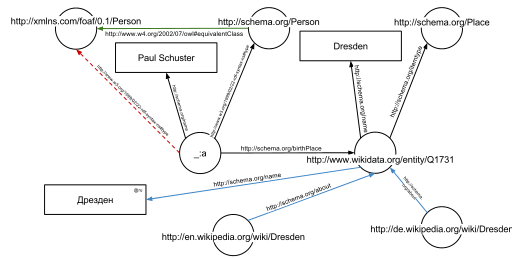 График, полученный из примера RDFa, обогащенный дополнительными данными из Интернета
График, полученный из примера RDFa, обогащенный дополнительными данными из Интернета
Одним из преимуществ использования унифицированных идентификаторов ресурсов (URI) является то, что их можно разыменовать с помощью протокола HTTP . Согласно так называемым принципам связанных открытых данных , такой разыменованный URI должен приводить к созданию документа, который предлагает дополнительные данные о данном URI. В этом примере всех идентификаторы URI, как для ребер и узлы (например , , ) может быть разыменовываются и приведет к дальнейшим графам RDF, описывающий URI, например , что Дрезден это город в Германии, или что человек, в том смысле , этот URI может быть вымышленным.
На втором графике показан предыдущий пример, но теперь он дополнен несколькими тройками из документов, которые являются результатом разыменования (зеленый край) и (синие края).
В дополнение к краям, явно указанным в задействованных документах, можно автоматически вывести края: тройной
из исходного фрагмента RDFa и тройной
из документа в (зеленый край на рисунке) позволяют вывести следующую тройку с учетом семантики OWL (красная пунктирная линия на втором рисунке):
Описание алгоритма решения задачи
1. Запустить табличный процессор MS Excel.





2. Создать книгу с именем «Продажи мобильных телефонов».
3. Лист 1 переименовать в лист с названием Модели и цены.
4. На рабочем листе Модели и цены MS Excel создать таблицу прайс-листа.
5. Заполнить таблицу прайс-листа исходными данными (рис. 16.1).
6. Лист 2 переименовать в лист с названием Список продаж.
7. На рабочем листе Список продаж MS Excel создать таблицу, в которой будет содержаться, какое количество мобильных телефонов каждой модели продано.
8. Заполнить таблицу, в которой будет содержаться, какое количество мобильных телефонов каждой модели продано, исходными данными.
9. Лист 3 переименовать в лист с названием Ведомость продаж.
10. На рабочем листе Ведомость продаж MS Excel создать таблицу, в которой будут содержаться, суммы, полученные от продаж каждой из моделей телефонов.
11. Заполнить таблицу, в которой будут содержаться, суммы, полученные от продаж каждой из моделей телефонов, исходными данными.
12. Заполнить графу Модель мобильного телефона таблицы «Ведомость продаж», находящейся на листе Ведомость продаж, следующим образом:
Занести в ячейку В2 формулу:
=ПРОСМОТР(A2;’Модели и цены’!A2:A18;’Модели и цены’!B2:B18)
Размножить введенную в ячейку В2 формулу для остальных ячеек (с В3 по В9) данной графы.
Таким образом, будет выполнен цикл, управляющим параметром которого является номер строки.
13. Заполнить графу Цена, руб. таблицы «Ведомость продаж», находящейся на листе Ведомость продаж следующим образом:
Занести в ячейку С2 формулу:
=ПРОСМОТР(‘Ведомость продаж’!A2;’Модели и цены’!A2:A18;’Модели и цены’!C2:C18)
Размножить введенную в ячейку С2 формулу для остальных ячеек (с С3 по С9) данной графы.
14. Заполнить графу Продано, шт. таблицы «Ведомость продаж», находящейся на листе Ведомость продаж следующим образом:
Занести в ячейку D2 формулу:
=ПРОСМОТР(A2;’Список продаж’!B2:B9;’Список продаж’!C2:C9)
Размножить введенную в ячейку D2 формулу для остальных ячеек (с D3 по D9) данной графы.
15. Заполнить графу Сумма, руб. таблицы «Ведомость продаж», находящейся на листе Ведомость продаж следующим образом:
Занести в ячейку E2 формулу:
=C2*D2
Размножить введенную в ячейку C2 формулу для остальных ячеек (с C3 по C9) данной графы.
16. Заполнить ячейку Е10 таблицы «Ведомость продаж», находящейся на листе Ведомость продаж следующим образом:
=СУММ(E2:E9)
17. На рабочем листе «Ведомость продаж» активизировать любую ячейку списка, выбрать команду Вставка/Диаграмма.
Задаем искомый диапазон и создаем на новом листе диаграмму.
По графам «Модель мобильного телефона» и «Продано, шт.»
По графам «Модель мобильного телефона» и «Цена, руб.»+ «Сумма, руб.»





Список литературы
Статья из журнала
1. Э. Нойманн, С. Стивенс, Л. Фейгенбаум, И. Херман, Т. Хонгзермайер. Семантическая сеть в действии // В мире науки (SCIENTIFIK AMERICAN). — 2008. — №3. — С. 60-67.
Публикации в сети Интернет
1. Директор Google сомневается в Семантической сети. — http://habrahabr.ru/blog/columns/5961.html (20.07.06)
2. Евгений Золин. Обзор статьи: семантическая сеть. — http://ezolin.pisem.net/logic/semantic_web_rus.html (05.05.2008)
3. Семантическая паутина. Википедиа Свободная энциклопедиа. — http://ru.wikipedia.org/wiki/%D0%A1%D0%B5%D0%BC%D0%B0%D0%BD%D1%82%D0%B8%D1%87%D0%B5%D1%81%D0%BA%D0%B0%D1%8F_%D0%BF%D0%B0%D1%83%D1%82%D0%B8%D0%BD%D0%B0
4. Google приходит конец. Вокруг света. — http://www.vokrugsveta.ru/news/3519/ (13.03.08)
5. Опубликован язык запросов для «семантического Web». — http://www.osp.ru/news/2008/0116/4698619/ (16.01.08)
Размещено на Allbest.ru
Основы семантических сетей
Семантическая сеть используется, когда у каждого есть знание, которое лучше всего понято как ряд понятий, которые связаны с друг другом.
Большинство семантических сетей познавательно базируется. Они также состоят из дуг и узлов, которые могут быть организованы в таксономическую иерархию. Семантические сети внесли идеи распространить активацию, наследование и узлы как первичные объекты.
Ограничения
Семантические сети тяжелы для больших областей, и они не представляют работу или метазнание очень хорошо.
Некоторые свойства легко не выражены, используя семантическую сеть, например, отрицание, дизъюнкция и общее нетаксономическое знание. Выражение этих отношений требует, чтобы искусственные приемы, такие как наличие дополнительных предикатов и использование специализированных процедур проверили на них, но это может быть расценено как менее изящное.
История
Примеры использования семантических сетей в логике, ориентированных ациклических графов как мнемонического инструмента насчитывают столетия. Самым ранним документированным использованием является комментарий греческого философа Порфирия к категориям Аристотеля в третьем веке нашей эры.
В компьютерной истории, «Семантический Нетс» для исчисления высказываний были впервые реализован для компьютеров от Richard H. Richens исследовательского отдела Кембриджского языка в 1956 году как « Интерлингва » для машинного перевода из естественных языков
Хотя важность этой работы и CLRU была осознана лишь с опозданием
Семантические сети были также независимо реализованы Робертом Ф. Симмонсом и Шелдоном Кляйном, используя в качестве основы исчисление предикатов первого порядка после того, как они были вдохновлены демонстрацией Виктора Ингве. Это направление исследований было инициировано первым президентом ассоциации Виктором Ингве, который в 1960 году опубликовал описания алгоритмов использования грамматики фразовой структуры для генерации синтаксически правильно сформированных бессмысленных предложений. Шелдон Кляйн и Примерно в 1962-1964 годах я был очарован этой техникой и обобщил ее до метода контроля смысла того, что было произведено, путем соблюдения семантических зависимостей слов, встречающихся в тексте ». Другие исследователи, в первую очередь М. Росс Куиллиан и другие сотрудники System Development Corporation, помогли внести свой вклад в их работу в начале 1960-х годов в рамках проекта SYNTHEX. Именно из этих публикаций в SDC большинство современных производных от термина «семантическая сеть» цитируют как основу. Позже выдающиеся работы были выполнены Алланом М. Коллинзом и Куиллианом (например, Коллинз и Куиллиан; Коллинз и Лофтус Куиллиан). Еще позже, в 2006 году, Герман Хельбиг полностью описал MultiNet .
В конце 1980-х годов два нидерландских университета, Гронинген и Твенте , совместно начали проект под названием « Графы знаний» , которые представляют собой семантические сети, но с дополнительным ограничением, заключающимся в том, что ребра ограничиваются ограниченным набором возможных отношений, чтобы упростить алгебры на графе. . В последующие десятилетия различия между семантическими сетями и графами знаний были размыты. В 2012 году дал своему графу знаний название « Сеть знаний» .
Сеть семантических ссылок систематически изучалась как метод социальной семантической сети. Его базовая модель состоит из семантических узлов, семантических связей между узлами и семантического пространства, которое определяет семантику узлов и ссылок, а также правила рассуждения о семантических связях. Систематическая теория и модель были опубликованы в 2004 году. Это направление исследований можно проследить до определения правил наследования для эффективного поиска модели в 1998 году и Active Document Framework ADF. С 2003 года исследования развиваются в направлении социальных семантических сетей. Эта работа является систематическим нововведением в эпоху всемирной паутины и глобальных социальных сетей, а не приложением или простым расширением семантической сети (сети). Его цель и объем отличаются от семантической сети (или сети). Правила рассуждений, эволюции и автоматического обнаружения неявных ссылок играют важную роль в сети семантических ссылок. Недавно он был разработан для поддержки кибер-физического и социального интеллекта. Он был использован для создания общего метода реферирования. Самоорганизующаяся сеть семантических связей была интегрирована с многомерным пространством категорий для формирования семантического пространства для поддержки расширенных приложений с многомерными абстракциями и самоорганизованными семантическими связями. Было подтверждено, что сеть семантических связей играет важную роль в понимании. и представление через приложения для обобщения текста. Для исследования особой социальной семантики, отношения конкуренции и отношения симбиоза, а также их роли в развивающемся обществе были изучены в новой теме: киберфизический социальный интеллект.
Для конкретного использования созданы более специализированные формы семантических сетей. Например, в 2008 году докторская диссертация Фоси Бендека формализовала сеть семантического сходства (SSN), которая содержит специализированные отношения и алгоритмы распространения для упрощения представления и вычислений семантического сходства .
Стандарты
Стандартизация семантической сети в контексте Web 3.0 находится под контролем W3C.
Составные части
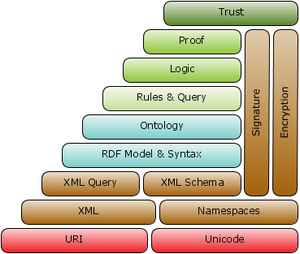
Термин «семантическая сеть Web» часто используется более конкретно для обозначения форматов и технологий, которые его обеспечивают. Сбор, структурирование и восстановление связанных данных обеспечивается технологиями, которые обеспечивают формальное описание концепций, терминов и отношений в рамках данной области знаний . Эти технологии определены как стандарты W3C и включают:
- Структура описания ресурсов (RDF), общий метод описания информации
- Схема RDF (RDFS)
- Простая система организации знаний (SKOS)
- SPARQL , язык запросов RDF
- Notation3 (N3), разработанный с учетом удобства восприятия человеком
- N-Triples , формат для хранения и передачи данных
- Черепаха (Terse RDF Triple Language)
- Язык веб-онтологий (OWL), семейство языков представления знаний
- Rule Interchange Format (RIF), структура диалектов языков веб-правил, поддерживающая обмен правилами в Интернете.
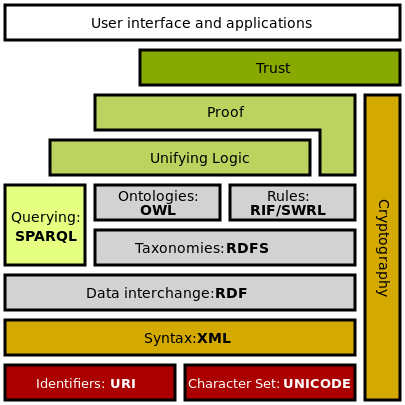
Semantic Web Stack
Semantic Web Stack иллюстрирует архитектуру Semantic Web. Функции и взаимосвязи компонентов можно резюмировать следующим образом:
- XML обеспечивает элементарный синтаксис для структуры содержимого в документах, но не связывает семантику со смыслом содержимого, содержащегося внутри. XML в настоящее время не является необходимым компонентом технологий семантической паутины в большинстве случаев, поскольку существуют альтернативные синтаксисы, такие как Turtle . Черепаха является стандартом де-факто, но не прошла формального процесса стандартизации.
- XML-схема — это язык для предоставления и ограничения структуры и содержимого элементов, содержащихся в XML-документах.
- RDF — это простой язык для выражения моделей данных , которые относятся к объектам (« веб-ресурсам ») и их отношениям. Модель на основе RDF может быть представлена в различных синтаксисах, например, RDF / XML, N3, Turtle и RDFa. RDF — это фундаментальный стандарт семантической сети.
- Схема RDF расширяет RDF и представляет собой словарь для описания свойств и классов ресурсов на основе RDF с семантикой для обобщенных иерархий таких свойств и классов.
- OWL добавляет дополнительный словарь для описания свойств и классов: среди прочего, отношения между классами (например, дизъюнктность), мощность (например, «ровно один»), равенство, более широкое типирование свойств, характеристики свойств (например, симметрия) и пронумерованные классы.
- SPARQL — это протокол и язык запросов для источников данных семантической сети.
- RIF — это формат обмена правилами W3C. Это язык XML для выражения веб-правил, которые могут выполнять компьютеры. RIF предоставляет несколько версий, называемых диалектами. Он включает в себя диалект базовой логики RIF (RIF-BLD) и диалект правил производства RIF (RIF PRD).
Текущее состояние стандартизации
Установленные стандарты:
- RDF
- RDFS
- Формат обмена правил (RIF)
- SPARQL
- Unicode
- Единый идентификатор ресурса
- Язык веб-онтологий (OWL)
- XML
Еще не полностью осознано:
- Объединение слоев логики и проверки
- Язык правил семантической сети (SWRL)
Бизнес и финансы
БанкиБогатство и благосостояниеКоррупция(Преступность)МаркетингМенеджментИнвестицииЦенные бумагиУправлениеОткрытые акционерные обществаПроектыДокументыЦенные бумаги — контрольЦенные бумаги — оценкиОблигацииДолгиВалютаНедвижимость(Аренда)ПрофессииРаботаТорговляУслугиФинансыСтрахованиеБюджетФинансовые услугиКредитыКомпанииГосударственные предприятияЭкономикаМакроэкономикаМикроэкономикаНалогиАудитМеталлургияНефтьСельское хозяйствоЭнергетикаАрхитектураИнтерьерПолы и перекрытияПроцесс строительстваСтроительные материалыТеплоизоляцияЭкстерьерОрганизация и управление производством
Что такое семантика
Эта наука изучает лингвистический и философский смысл языка, языков программирования, формальных логик, семиотики и проводит анализ текста. Она связана отношением:
- с означающими словами;
- словами;
- фразами;
- знаками;
- символами и тем, что они означают, их обозначением.
Проблема понимания была предметом многих запросов в течение длительного периода времени, но этим вопросом занимались большей частью психологи, а не лингвисты. Но только в лингвистике изучается интерпретация знаков или символов, используемых в сообществах при определённых обстоятельствах и контекстах. В этом представлении звуки, мимика, язык тела и проксемика имеют семантический (значимый) контент, и каждый из них включает несколько отделений. На письменном языке такие вещи, как структура абзаца и пунктуация, содержат семантический контент.
Формальный анализ семантики пересекается со многими другими областями исследования, включая:
- лексикологию;
- синтаксис;
- прагматику;
- этимологию и другие.
Само собой разумеется, определение семантики также является чётко определённой областью в своём праве, часто с синтетическими свойствами. В философии языка, семантика и ссылка тесно связаны. Дальнейшие смежные области включают филологию, связь и семиотику.






Семантика контрастирует с синтаксисом, изучением комбинаторики единиц языка (без ссылки на их смысл) и прагматикой, изучением отношений между символами языка, их значением и пользователями языка. Область исследования в этом случае также имеет существенные связи с различными репрезентативными теориями смысла, включая истинные теории смысла, теории связности смысла и теории соответствий смысла. Каждый из них связан с общим философским исследованием реальности и представлением смысла.
Справочная информация
ДокументыЗаконыИзвещенияУтверждения документовДоговораЗапросы предложенийТехнические заданияПланы развитияДокументоведениеАналитикаМероприятияКонкурсыИтогиАдминистрации городовПриказыКонтрактыВыполнение работПротоколы рассмотрения заявокАукционыПроектыПротоколыБюджетные организацииМуниципалитетыРайоныОбразованияПрограммыОтчетыпо упоминаниямДокументная базаЦенные бумагиПоложенияФинансовые документыПостановленияРубрикатор по темамФинансыгорода Российской Федерациирегионыпо точным датамРегламентыТерминыНаучная терминологияФинансоваяЭкономическаяВремяДаты2015 год2016 годДокументы в финансовой сферев инвестиционной
дальнейшее чтение
- Программируемая сеть Аарона Шварца: незаконченная работа, подаренная издательством Morgan & Claypool после смерти Аарона Шварца в январе 2013 года.
- Григорис Антониу, Франк ван Хармелен (31 марта 2008 г.). Учебник по семантической паутине, 2-е издание . MIT Press . ISBN 978-0-262-01242-3.
- Дин Аллеманг , Джеймс Хендлер (9 мая 2008 г.). Семантическая сеть для рабочего онтолога: эффективное моделирование в RDFS и OWL . Морган Кауфманн. ISBN 978-0-12-373556-0.
- Томас Б. Пассин (1 марта 2004 г.). Руководство исследователя по семантической сети . Публикации Мэннинга. ISBN 978-1-932394-20-7.
- Джеффри Т. Поллок (23 марта 2009 г.). . Для чайников. ISBN 978-0-470-39679-7.
Как поступить, если организация настаивает на незаконных выплатах?
Работник вправе не согласиться на трудоустройство, противоречащее нормам, установленным в действующих правовых актах. Первое, что нужно сделать человеку – обратиться к руководству. Если гражданин настойчив в своих требованиях, то начальство пойдет на уступки и переоформит соглашение, а отчисления будет производить по всем правилам. Дело в том, что жалоба в уполномоченные инстанции станет для нанимателя ударом по репутации и кошельку, ведь документ является прямым доказательством противоправных действий.
Легализация
Узаконить «серые» отчисления можно несколькими способами. Первый – выплата дивидендов. Это допустимо, если работник является одним из учредителей компании. Такой доход освобождается от начисления взносов в страховые фонды. Однако НДФЛ все равно нужно уплачивать. Второй – начисление компенсации за позднее перечисление заработной платы. Размер должен обязательно фиксироваться во внутренних актах организации.
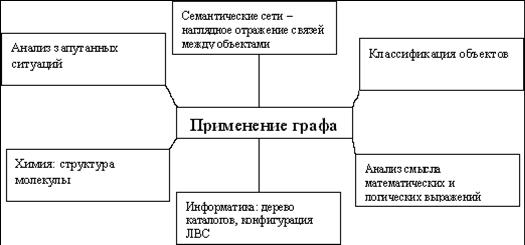
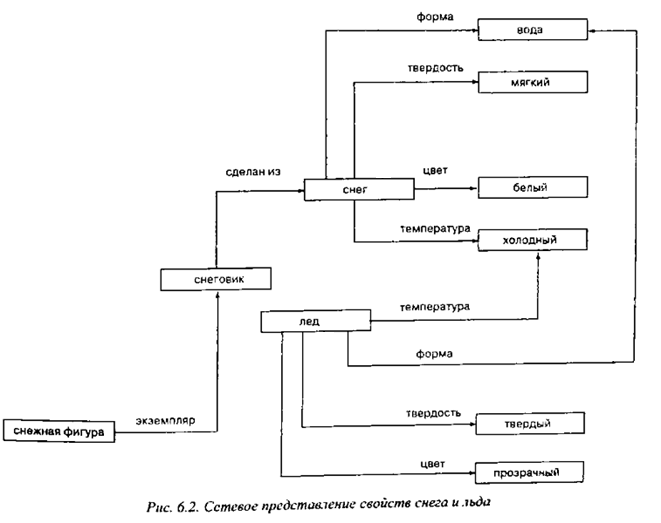
Классификация семантических сетей
Для
всех семантических сетей справедливо
разделение по арностии
количеству типов отношений.
По
количеству типов отношений, сети могут
быть однородными и неоднородными.
-
Однородные
сети обладают только одним типом
отношений (стрелок), например, таковой
является классификация биологических
видов (с единственным отношением AKO). -
В
неоднородных сетях количество типов
отношений больше двух. Классические
иллюстрации данной модели представления
знаний представляют именно такие сети.
Неоднородные сети представляют больший
интерес для практических целей, но и
большую сложность для исследования.
Неоднородные сети можно представлять
как переплетение древовидных многослойных
структур. Примером такой сети может
быть Семантическая сеть Википедии.
По
арности:
-
типичными
являются сети с бинарными отношениями
(связывающими ровно два понятия).
Бинарные отношения очень просты и
удобно изображаются на графе в виде
стрелки между двух концептов. Кроме
того, они играют исключительную роль
в математике. -
На
практике, однако, могут понадобиться
отношения, связывающие более двух
объектов — N-арные.
При этом возникает сложность — как
изобразить подобную связь на графе,
чтобы не запутаться. Концептуальные
графы снимают это затруднение, представляя
каждое отношение в виде отдельного
узла.
По
размеру:
-
Для
решения конкретных задач, например,
тех которые решают системы искусственного
интеллекта. -
Семантическая
сеть отраслевого масштаба должна
служить базой для создания конкретных
систем, не претендуя на всеобщее
значение. -
Глобальная
семантическая сеть.Возможно когда-нибудь
такой сетью станет Всемирная
паутина.
В
семантических сетях часто используются
также следующие отношения:
—
таксономические («класс – подкласс –
экземпляр», «множество – подмножество
– элемент» и т.п.).
—
структурные («часть – целое»).
—
родовые («предок» — «потомок»);
—
производственные («начальник» —
«подчиненный»);
—
функциональные (определяемые обычно
глаголами «производит», «влияет» и
т.п.);
—
количественные (больше, меньше, равно
и т.п.);
—
пространственные (далеко от, близко от,
за, под, над и т.п.);
—
временные (раньше, позже, в течение и
т.п.);
—
атрибутивные (иметь свойство, иметь
значение);
—
логические (И, ИЛИ, НЕ);
—
казуальные (причинно-следственные).
Достоинствасемантических
сетей:
-
универсальность,
достигаемая за счет выбора соответствующего
набора отношений. В принципе с помощью
семантической сети можно описать сколь
угодно сложную ситуацию, факт или
предметную область; -
наглядность
системы знаний, представленной
графически; -
близость
структуры сети, представляющей систему
знаний, семантической структуре фраз
на естественном языке; -
соответствие
современным представлениям об организации
долговременной памяти человека.
Недостаткисемантических
сетей:
-
сетевая
модель не дает (точнее, не содержит)
ясного представления о структуре
предметной области, поэтому формирование
и модификация такой модели затруднительны; -
сетевые
модели представляют собой пассивные
структуры, для обработки которых
необходим специальный аппарат формального
вывода; -
проблема
поиска решения в семантической сети
сводится к задаче поиска фрагмента
сети, соответствующего подсети,
отражающей поставленный запрос. Это,
в свою очередь, обуславливает сложность
поиска решения в семантических сетях; -
представление,
использование и модификация знаний
при описании систем реального уровня
сложности оказывается трудоемкой
процедурой, особенно при наличии
множественных отношений между ее
понятиями.
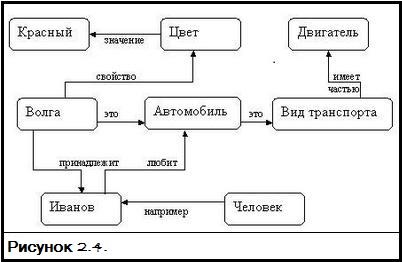
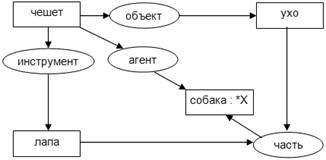
Примеры:
э
Транспорт
ч
Машина
Хозяин
ц
Черный
д
Поездка
к
м
Работа
2107
ч
– чья
д
– для
к
– куда
э
— это
ц
– цвет
м
— модель
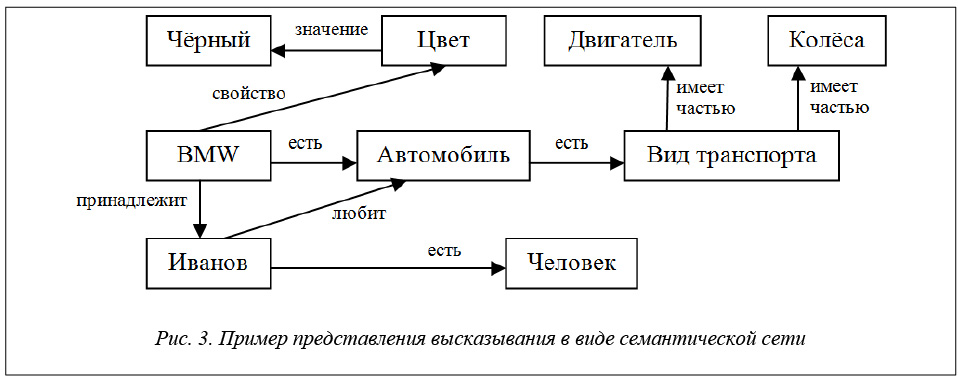
Рыжая
о
в
п
Собака
Лабрадор
Хозяин
д
ч
Защита
Имущество
п
— принадлежность
о
— окрас
в
— вид
д
— для
ч
— чего
Машины логического вывода
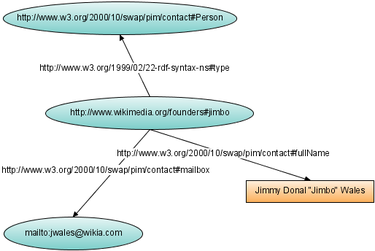
Онтологии можно считать работающими уровнем выше RDF, а машины логического вывода работают уровнем выше онтологий. Эти программы исследуют различные онтологии и находят новые взаимоотношения и связи между содержащимися в них терминами и данными. Например, машина логического вывода может изучать три представленные ниже RDF-тройки и сделать вывод, что Flipper есть млекопитающее. Распознавание связей межу различными источниками — важный этап на пути к выявлению «смысла» информации.






<uri for Flipper> <uri for Is > <uri for Dolphine>
<uri for Dolphine> <uri for Subclass Of> <uri for Mammal>
<uri for Flipper> <uri for Is A> <uri for Mammal>







