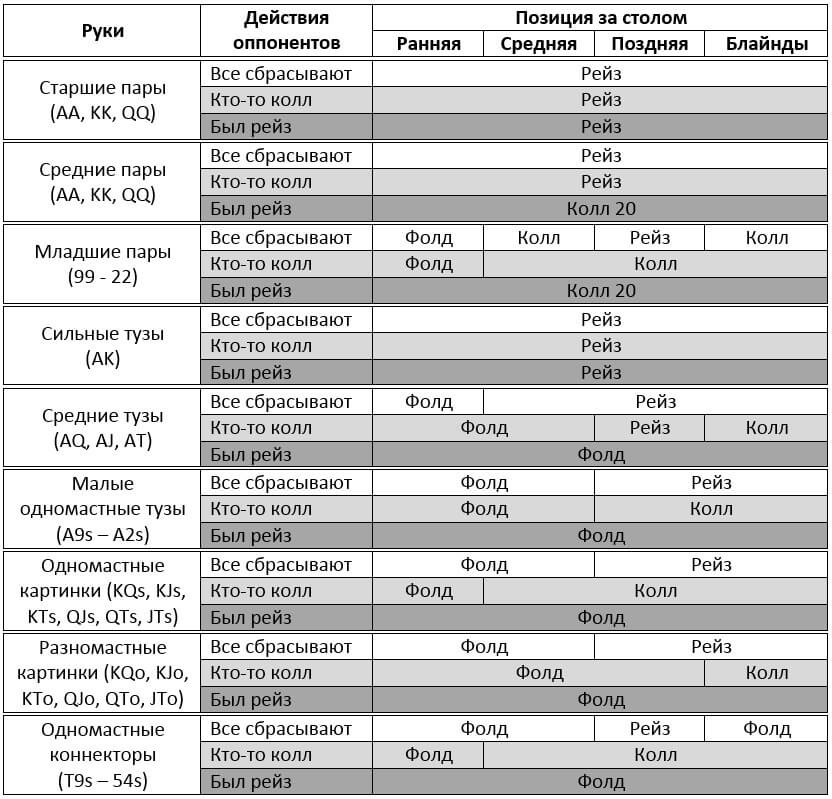
Куча
Сегмент кучи (или просто «куча») отслеживает память, используемую для динамического выделения. Мы уже немного поговорили о куче на уроке о динамическом выделении памяти в языке С++.
В языке C++, при использовании оператора new для выделения динамической памяти, память выделяется из сегмента кучи самой программы:
int *ptr = new int; // для ptr выделяется 4 байта из кучи
int *array = new int; // для array выделяется 40 байт из кучи
|
1 |
int*ptr=newint;// для ptr выделяется 4 байта из кучи int*array=newint10;// для array выделяется 40 байт из кучи |
Адрес выделяемой памяти передается обратно оператором new и затем он может быть сохранен в указателе. О механизме хранения и выделения свободной памяти нам сейчас беспокоиться не за чем. Однако стоит знать, что последовательные запросы памяти не всегда приводят к выделению последовательных адресов памяти!
int *ptr1 = new int;
int *ptr2 = new int;
// ptr1 и ptr2 могут не иметь последовательных адресов памяти
|
1 |
int*ptr1=newint; int*ptr2=newint; // ptr1 и ptr2 могут не иметь последовательных адресов памяти |
При удалении динамически выделенной переменной, память возвращается обратно в кучу и затем может быть переназначена (исходя из последующих запросов). Помните, что удаление указателя не удаляет переменную, а просто приводит к возврату памяти по этому адресу обратно в операционную систему.
Куча имеет свои преимущества и недостатки:
Выделение памяти в куче сравнительно медленное.
Выделенная память остается выделенной до тех пор, пока не будет освобождена (остерегайтесь утечек памяти) или пока программа не завершит свое выполнение.
Доступ к динамически выделенной памяти осуществляется только через указатель. Разыменование указателя происходит медленнее, чем доступ к переменной напрямую.
Поскольку куча представляет собой большой резервуар памяти, то именно она используется для выделения больших массивов, структур или классов.
Технологии, которые стали фаворитами
- JavaScript-модули. Модули отлично зарекомендовали себя в серверном JavaScript-коде. И я безмерно рад тому, что наконец могу использовать их и на стороне клиента.
-
Объектно-ориентированный JavaScript. Вот пять золотых правил объектно-ориентированной JavaScript-разработки:
- Заменяйте анонимные объекты именованными классами.
- Объявляйте и инициализируйте все свойства объектов в конструкторах.
- Защищайте объекты от изменений сразу после создания.
- Объявляйте методы с неизменными сигнатурами.
- Привязывайте к каждому коллбэку.
- Blue Phrase. Эта система позволяет мне пользоваться декларативным подходом при создании шаблонов и при подготовке различных материалов. Она превращает написание качественного HTML-кода в сплошное удовольствие.
Технологии, которые потеряли былую привлекательность
Adobe Photoshop и Illustrator. Это — два замечательных приложения, которые многие годы удовлетворяли все мои потребности в работе с графикой. Я с грустью говорю им «прощайте» и благодарю их за то, что они были со мной. Теперь всё, что мне нужно, дают их бесплатные опенсорсные заменители.
jQuery. Эта библиотека стала ненужной тогда, когда закончились войны кросс-браузерной совместимости. Единственной ценнейшей для меня возможностью jQuery был синтаксис селекторов. Он оказался настолько востребованным, что в 2009 году был добавлен в DOM в виде .
AJAX. Этот прародитель Web 2.0. теперь превратился в пережиток прошлого. API заменяется современным и более простым API , а JSON приходит на замену XML.
SASS/SCSS. Я признаю то, что написание CSS-кода без переменных было неэффективным, в результате SASS многим пришёлся по душе
И модули тоже были весьма важной возможностью. Но в итоге для того, чтобы всё это использовать в JavaScript, нужно было потратить слишком много времени и сил
При этом, наряду с развитием вспомогательных инструментов для работы со стилями, стандарт CSS тоже не стоял на месте. В результате различные средства для преобразования CSS-кода постепенно уходят в прошлое.
БЭМ. Схема именования сущностей БЭМ (Блок, Элемент, Модификатор), используемая при формировании имён CSS-классов, решает проблему глобального пространства имён. Но за это приходится платить использованием очень длинных конструкций. Я перешёл к родительским/дочерним селекторам в семантических элементах, предпочтя более лёгкий подход идентификаторам и именам классов.
Например:
Шрифты Georgia и Verdana. Эти два шрифта многие годы занимали верхнюю позицию моего рейтинга шрифтов. Я мог положиться на их доступность и на их читабельность. Но после того, как появилось правило , и после того, как начали распространяться опенсорсные шрифты, я стал пользоваться подобными шрифтами.
Babel, Grunt, Gulp, Browserify, WebPack. Первые четыре пункта в этом списке вряд ли кого удивят. Но почему мой стек веб-технологий покинул Webpack? У того, что этот бандлер потерял для меня актуальность, есть некоторые причины, на которых я остановлюсь подробнее:До появления HTTP/2 с поддержкой постоянных соединений и мультиплексирования потоков мы находились в зависимости от возможностей этих инструментов по сборке бандлов ресурсов приложений. Но бандлинг ничего нам не даёт в мире, где есть HTTP/2.
Стандарт ECMAScript 2015 был новым словом в JavaScript-разработке, все бросились использовать новые возможности языка в тот самый момент, когда они увидели свет. Однако тут была одна проблема. Код, написанный с использованием новых возможностей, не поддерживался браузерами. Поэтому его приходилось транспилировать в ECMAScript 5-код. В этом деле мы полагались на Babel, его применение стало стандартным шагом подготовки веб-проектов к публикации. Сегодня же все необходимые мне новые возможности языка доступны буквально повсюду. В результате Babel мне больше не нужен.
До появления в браузерах возможности динамического импорта модулей код приходилось транспилировать в формат CommonJS. Теперь же большинство основных браузеров поддерживает (да и Edge 76+ скоро подтянется). В результате скоро мы сможем поздороваться с ECMAScript-модулями и попрощаться со всем остальным.
JSX. Я не понимаю тех, кто полагает, что JSX — это хорошо. И «Но вы же к этому привыкли» для меня — не аргумент.
Функциональное программирование. Я ограничил применение функционального программирования в своём коде до простых однострочных конструкций вроде . Для всего остального я использую объектно-ориентированное программирование.
Определение[править]
Стек
Стек (от англ. stack — стопка) — структура данных, представляющая из себя упорядоченный набор элементов, в которой добавление новых элементов и удаление существующих производится с одного конца, называемого вершиной стека. Притом первым из стека удаляется элемент, который был помещен туда последним, то есть в стеке реализуется стратегия «последним вошел — первым вышел» (last-in, first-out — LIFO). Примером стека в реальной жизни может являться стопка тарелок: когда мы хотим вытащить тарелку, мы должны снять все тарелки выше. Вернемся к описанию операций стека:



- — проверка стека на наличие в нем элементов,
- (запись в стек) — операция вставки нового элемента,
- (снятие со стека) — операция удаления нового элемента.
Реализации[править]
Для стека с элементами требуется памяти, так как она нужна лишь для хранения самих элементов.
На массивеправить
Перед реализацией стека выделим ключевые поля:
- — массив, с помощью которого реализуется стек, способный вместить не более элементов,
- — индекс последнего помещенного в стек элемента.
Стек состоит из элементов , где — элемент на дне стека, а — элемент на его вершине.
Если , то стек не содержит ни одного элемента и является пустым (англ. empty). Протестировать стек на наличие в нем элементов можно с помощью операции — запроса . Если элемент снимается с пустого стека, говорят, что он опустошается (англ. underflow), что обычно приводит к ошибке. Если значение больше , то стек переполняется (англ. overflow)
(В представленном ниже псевдокоде возможное переполнение во внимание не принимается.)
Каждую операцию над стеком можно легко реализовать несколькими строками кода:
boolean empty(): return s.top == 0
function push(element : T): s.top = s.top + 1 s = element
T pop():
if empty()
return error "underflow"
else
s.top = s.top - 1
return s
Как видно из псевдокода выше, все операции со стеком выполняются за .
На саморасширяющемся массивеправить
Возможна реализация стека на динамическом массиве, в результате чего появляется существенное преимущество над обычной реализацией: при операции push мы никогда не сможем выйти за границы массива, тем самым избежим ошибки исполнения.
Создадим вектор и определим операции стека на нём. В функции Перед тем, как добавить новый элемент, будем проверять, не нужно ли расширить массив вдвое, а в , перед тем, как изъять элемент из массива, — не нужно ли вдвое сузить размер вектора. Ниже приведён пример реализации на векторе.
Ключевые поля:
- — старый массив, в котором хранится стек,
- — временный массив, где хранятся элементы после перекопирования,
- — верхушка стека,
- — размер массива.
function push(element : T):
if head == capacity - 1
T newStack
for i = 0 to capacity - 1
newStack = s
s = newStack
capacity = capacity * 2
head++
s = element
T pop():
temp = s
head--
if head < capacity / 4
T newStack[capacity / 2]
for i = 0 to capacity / 4 - 1
newStack = s
s = newStack
capacity = capacity / 2
return temp
На спискеправить
Стек можно реализовать и на списке. Для этого необходимо создать список и операции работы стека на созданном списке. Ниже представлен пример реализации стека на односвязном списке. Стек будем «держать» за голову. Добавляться новые элементы посредством операции будут перед головой, сами при этом становясь новой головой, а элементом для изъятия из стека с помощью будет текущая голова. После вызова функции текущая голова уже станет старой и будет являться следующим элементом за добавленным, то есть ссылка на следующий элемент нового элемента будет указывать на старую голову. После вызова функции будет получена и возвращена информация, хранящаяся в текущей голове. Сама голова будет изъята из стека, а новой головой станет элемент, который следовал за изъятой головой.
Заведем конструктор вида
Ключевые поля:
- — значение в верхушке стека,
- — значение следующее за верхушкой стека.
function push(element : T): head = ListItem(head, element)
T pop(): data = head.data head = head.next return data
В реализации на списке, кроме самих данных, хранятся указатели на следующие элементы, которых столько же, сколько и элементов, то есть, так же . Стоит заметить, что стек требует дополнительной памяти на указатели в списке.
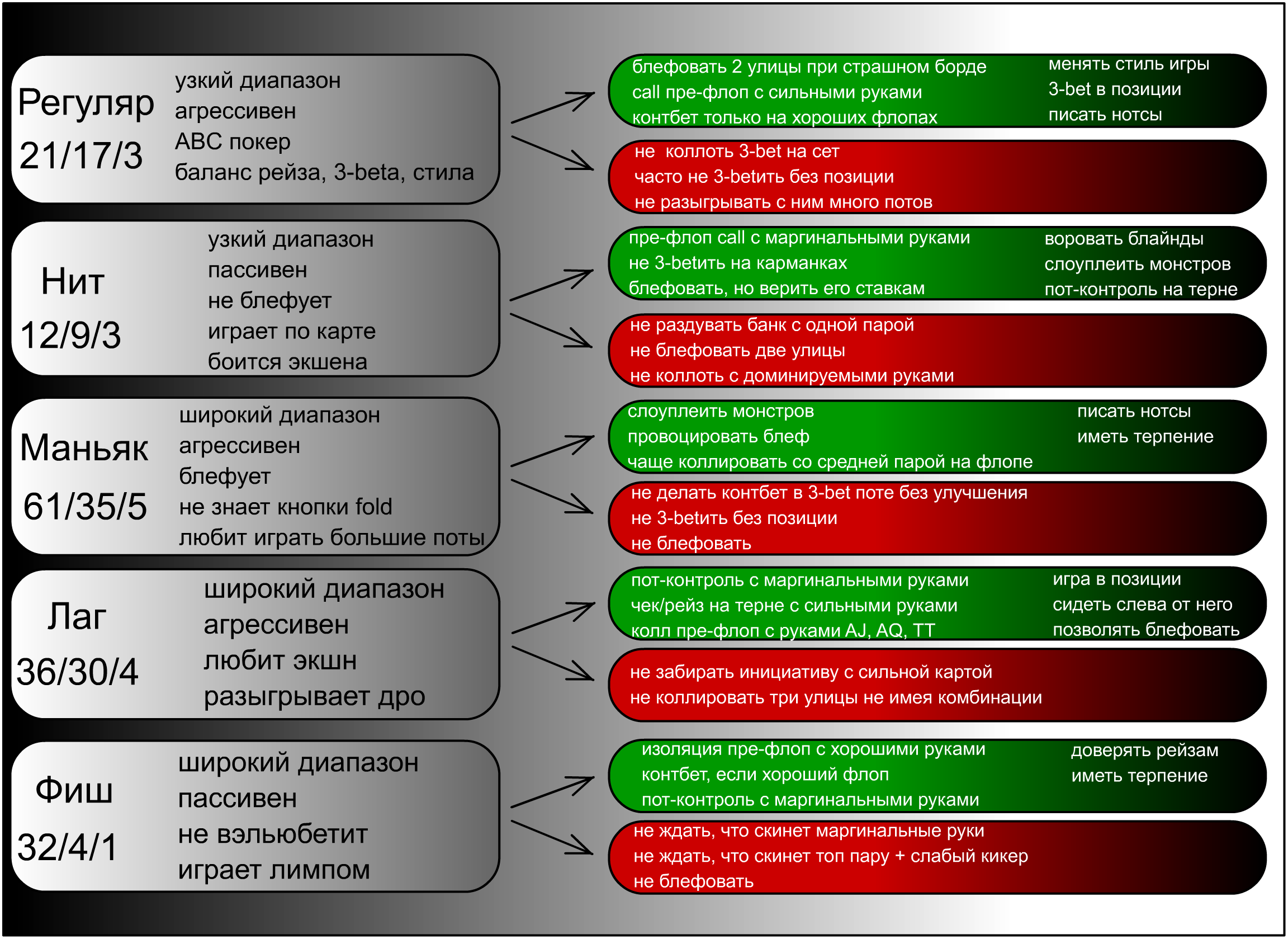
Зависимость между Стеком и стратегией
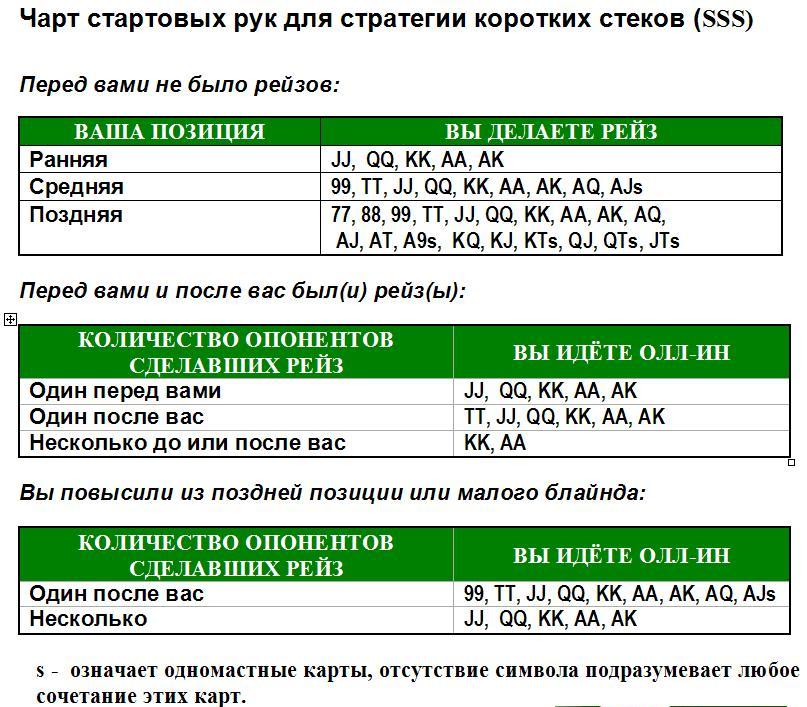
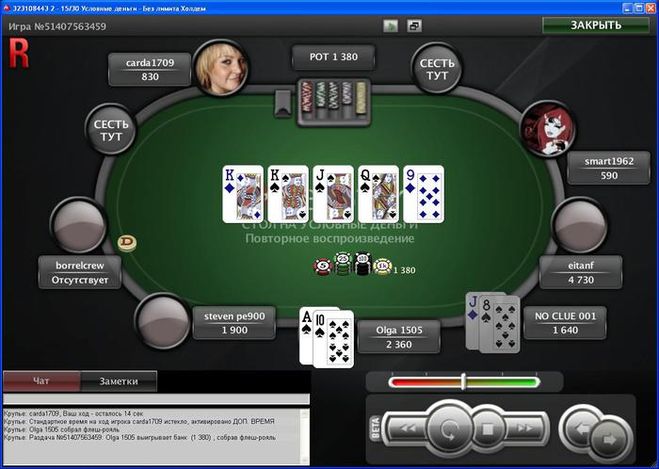
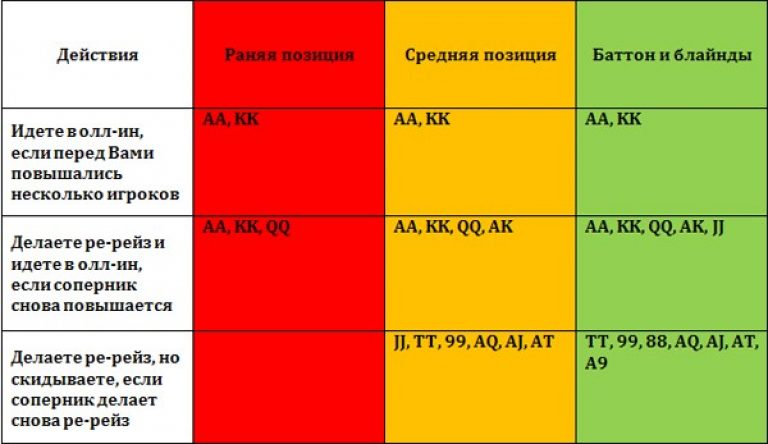
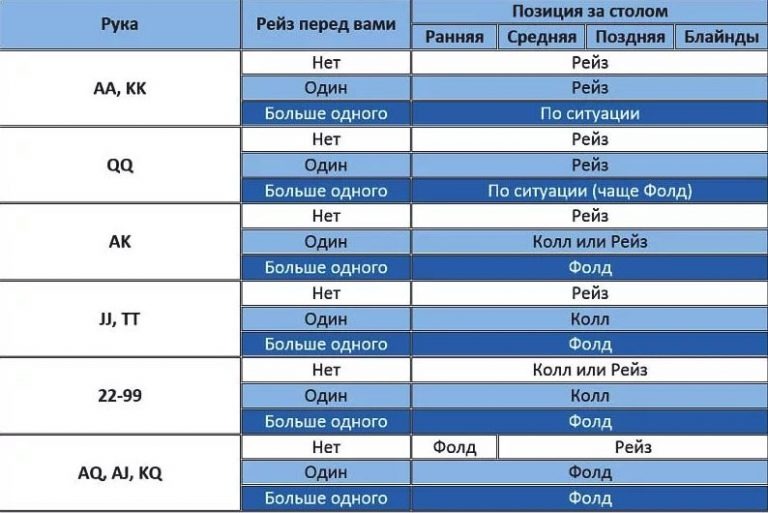
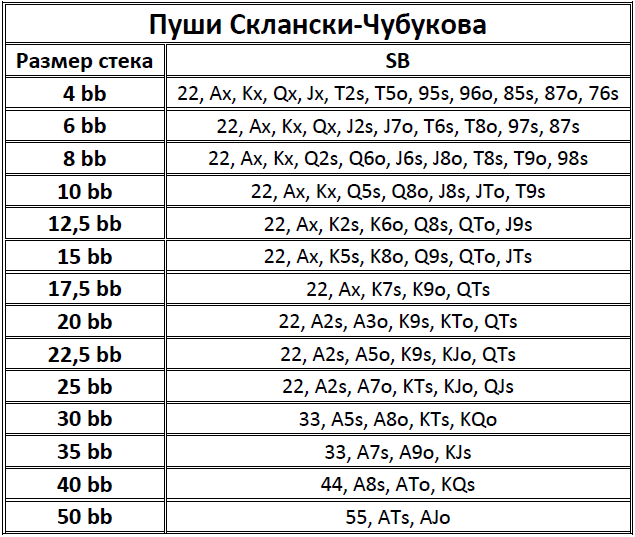
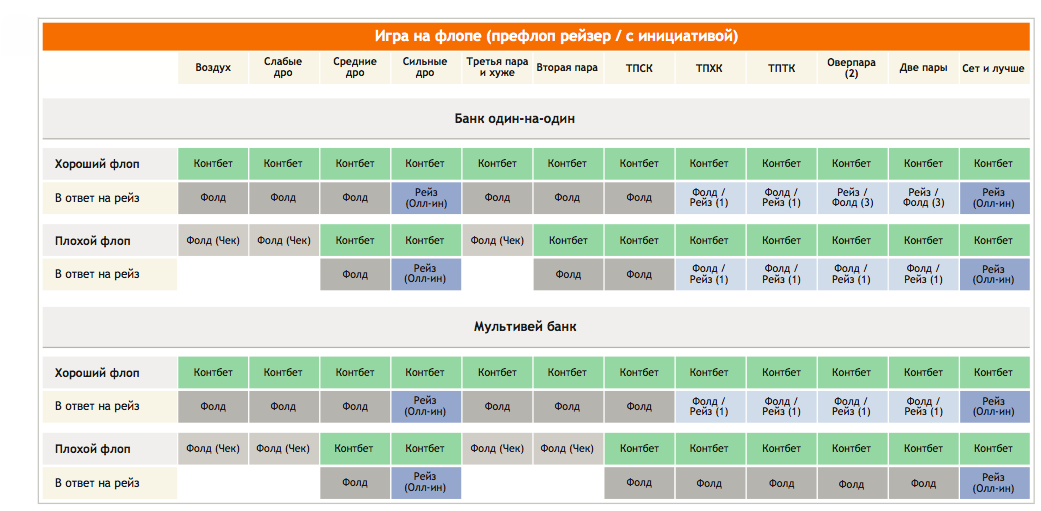
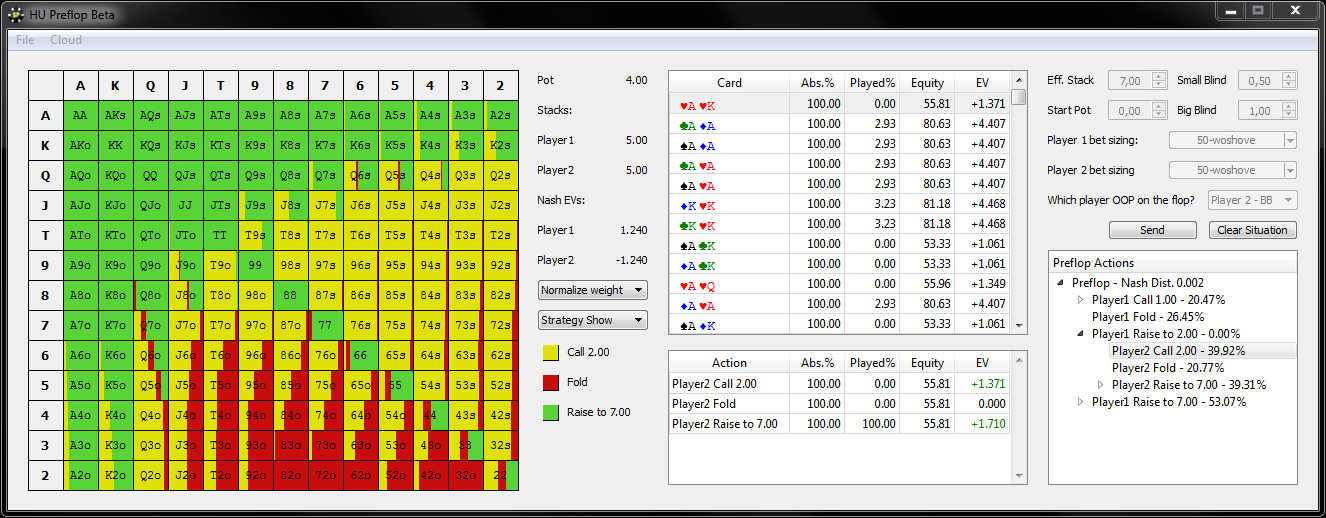
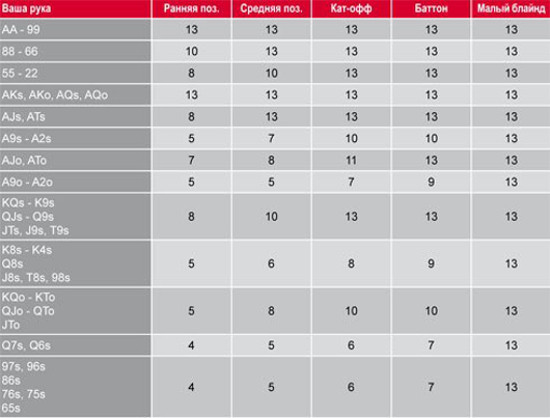
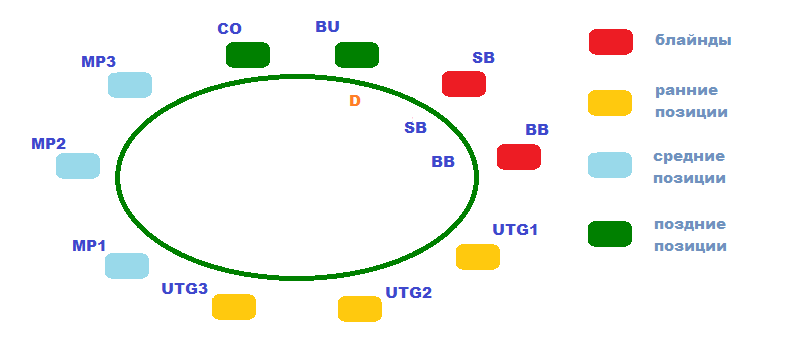
Количество денег, которые Вы берете за кэш-стол, должно определяться не случайным образом, а согласно особенностям Вашей стратегии. Их различают по соотношению Стека и блайндов. Например, если покерист берет за стол 20-40ББ, он играет по стратегии коротких стеков. Такая игра требует разыгрывать только самые сильные стартовые руки, вести агрессивные торги на префлопе и стремиться поставить все фишки в банк, если покерист получает высокую комбинацию. Их не хватит, чтобы использовать тактические приемы, поэтому следует избегать сложных ситуаций на флопе. Однако большинство опытных покеристов играет по стратегии высоких или глубоких Стеков, размером в 100ББ и больше. Такой запас фишек за столом позволяет использовать весь спектр тактических приемов и получать от игры максимальную прибыль.
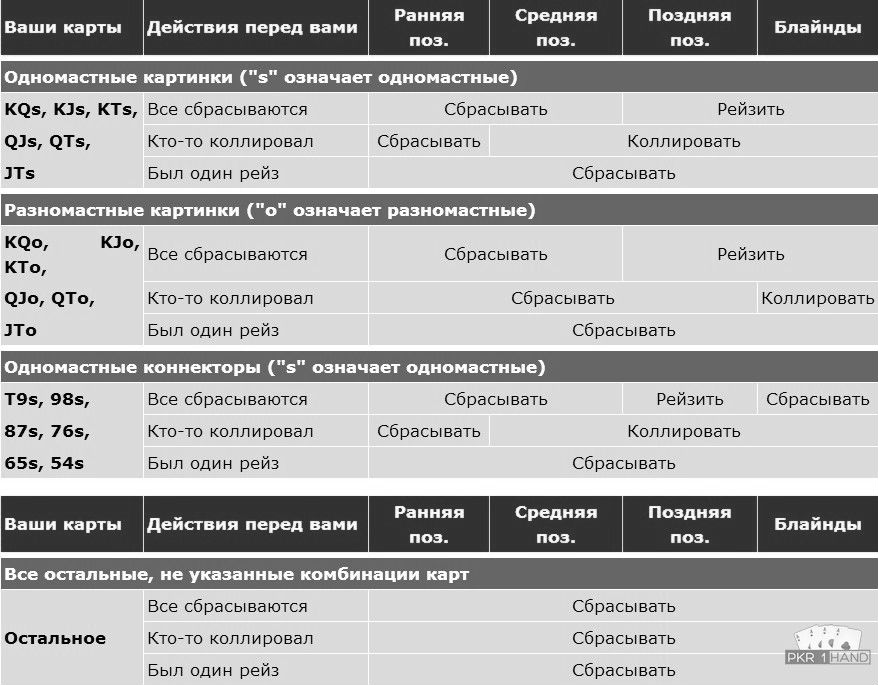
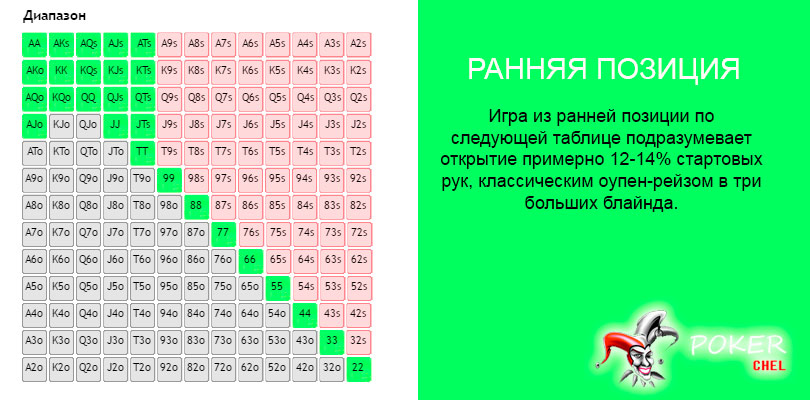




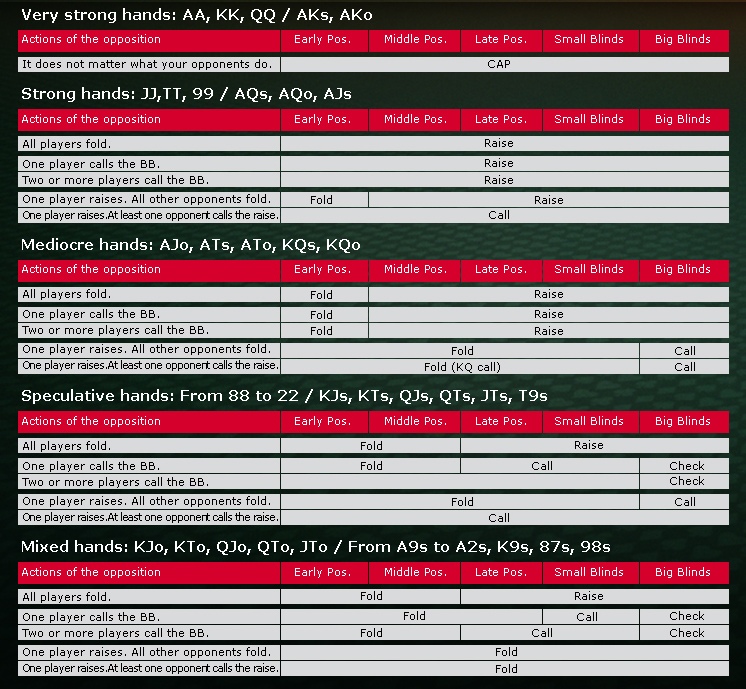


Казалось бы, если взять с собой за стол 100ББ, можно столкнуться высокими рисками проигрыша, так как в случае, если раздача ва-банк будет проиграна, покерист потеряет серьезную часть банкролла. Но это оправдывается тем, что играя по стратегии, пользователь ставит все 100ББ только в тех ситуациях, которые выгодны в долгосрочной перспективе. Поэтому, проиграв один или два раза все 100ББ, он компенсирует свои расходы, выиграв один раз в аналогичной ситуации, а также получит прибыль.
Чтобы стратегия, которую использует покерист, работала, необходимо своевременно пополнять Стек, докупая его до нужного количества блайндов. Например, если Вы проиграли 20ББ, между раздачами следует пополнить запас фишек до 100ББ. Может показаться, что это будет отвлекать от игрового процесса, но иначе стратегия окажется неэффективной. К тому же, большинство покерных клиентов позволяют делать докупку автоматически. Вы можете установить параметры автодокупки, установив при каких порогах приложение автоматически должно пополнять запас денег за столом.
В некоторых случаях Вы будете попадать в ситуации, когда у Вас будут скапливаться деньги за столом, превышая максимальный бай-ин. Например, Вы взяли с собой в игру 20$ – максимум для стола, а через час у Вас скопилось 120$. Если у остальных соперников нет столько денег, например – они по-прежнему имеют примерно по 20$, ситуация не страшна, так как они не могут за одну раздачу забрать все Ваши фишки. Но если среди соперников есть оппоненты, также имеющие много денег, лучше скинуть лишние фишки, покинув на время стол. Дело в том, что игра против такого оппонента может оказаться невыгодной в долгосрочной перспективе, если Вы поставите все 120 долларов. В случае если Вы проиграете их, Вы не сможете докупить столько же фишек (120$), чтобы реализовать математическое ожидание от ситуации, так как правила не позволят Вам взять больше 20$ – максимальный бай-ин. После того, как Вы покинете игру, все деньги окажутся в кассе, а Вы сможете вновь сесть в игру с тем стеком, который оптимальной величины для Вашей стратегии.
Функции
Функция создания «Стека»/добавления элемента в «Стек»
При добавлении элемента у нас возникнет две ситуации:
- Стек пуст, и нужно создать его
- Стек уже есть и нужно лишь добавить в него новый элемент
Разберем чуть чуть по-подробнее.
Во-первых, почему функция принимает **top, то есть указатель на указатель, для того чтобы вам было наиболее понятно, я оставлю рассмотрение этого вопроса на потом. Во-вторых, по-подробнее поговорим о q->next = *top и о том, что же означает ->.
-> означает то, что грубо говоря, мы заходим в нашу структуру и достаем оттуда элемент этой структуры. В строчке q->next = *top мы из нашей ячейки достаем указатель на следующий элемент *next и заменяем его на указатель, который указывает на вершину стека *top. Другими словами мы проводим связь, от нового элемента к вершине стека. Тут ничего сложного, все как с книгами. Новую книгу мы кладем ровно на вершину стопки, то есть проводим связь от новой книги к вершине стопки книг. После этого новая книга автоматически становится вершиной, так как стек не стопка книг, нам нужно указать, что новый элемент — вершина, для этого пишется: *top = q;.
Функция удаления элемента из «Стека» по данным
Данная функция будет удалять элемент из стека, если число Data ячейки(q->Data) будет равна числу, которое мы сами обозначим.
Здесь могут быть такие варианты:
- Ячейка, которую нам нужно удалить является вершиной стека
- Ячейка, которую нам нужно удалить находится в конце, либо между двумя ячейками
Указатель q в данном случае играет такую же роль, что и указатель в блокноте, он бегает по всему стеку, пока не станет равным NULL(while(q != NULL)), другими словами, пока стек не закончится.
Для лучшего понимания удаления элемента проведем аналогии с уже привычной стопкой книг. Если нам нужно убрать книгу сверху, мы её убираем, а книга под ней становится верхней. Тут то же самое, только в начале мы должны определить, что следующий элемент станет вершиной *top = q->next; и только потом удалить элемент free(q);
Если книга, которую нужно убрать находится между двумя книгами или между книгой и столом, предыдущая книга ляжет на следующую или на стол. Как мы уже поняли, книга у нас-это ячейка, а стол получается это NULL, то есть следующего элемента нет. Получается так же как с книгами, мы обозначаем, что предыдущая ячейка будет связана с последующей prev->next = q->next;, стоит отметить что prev->next может равняться как ячейке, так и нулю, в случае если q->next = NULL, то есть ячейки нет(книга ляжет на стол), после этого мы очищаем ячейку free(q).
Так же стоит отметить, что если не провести данную связь, участок ячеек, который лежит после удаленной ячейки станет недоступным, так как потеряется та самая связь, которая соединяет одну ячейку с другой и данный участок просто затеряется в памяти
Функция вывода данных стека на экран
Самая простая функция:
Здесь я думаю все понятно, хочу сказать лишь то, что q нужно воспринимать как бегунок, он бегает по всем ячейкам от вершины, куда мы его установили вначале: *q = top;, до последнего элемента.
Главная функция
Хорошо, основные функции по работе со стеком мы записали, вызываем.
Посмотрим код:
Вернемся к тому, почему же в функцию мы передавали указатель на указатель вершины. Дело в том, что если бы мы ввели в функцию только указатель на вершину, то «Стек» создавался и изменялся только внутри функции, в главной функции вершина бы как была, так и оставалась NULL. Передавая указатель на указатель мы изменяем вершину *top в главной функции. Получается если функция изменяет стек, нужно передавать в нее вершину указателем на указатель, так у нас было в функции s_push,s_delete_key. В функции s_print «Стек» не должен изменяться, поэтому мы передаем просто указатель на вершину.
Вместо цифр 1,2,3,4,5 можно так-же использовать переменные типа int.



Полный код программы:
Переполнение стека
Стек имеет ограниченный размер и, следовательно, может содержать только ограниченный объем информации. В операционной системе Windows размер стека по умолчанию составляет 1МБ. На некоторых других Unix-системах этот размер может достигать и 8МБ. Если программа пытается поместить в стек слишком много информации, то это приведет к переполнению стека. Переполнение стека (англ. «stack overflow») происходит, когда запрашиваемой памяти нет в наличии (вся память уже занята).
Переполнение стека является результатом добавления слишком большого количества переменных в стек и/или создания слишком большого количества вложенных вызовов функций (например, когда функция A() вызывает функцию B(), которая вызывает функцию C(), а та, в свою очередь, вызывает функцию D() и т.д.). Переполнение стека обычно приводит к сбою в программе, например:
int main()
{
int stack;
return 0;
}
|
1 |
intmain() { intstack1000000000; return; } |
Эта программа пытается добавить огромный массив в стек вызовов. Поскольку размера стека недостаточно для обработки такого массива, то операция его добавления переходит и на другие части памяти, которые программа использовать не может. Следовательно, получаем сбой.
Вот еще одна программа, которая вызовет переполнение стека, но уже по другой причине:
void boo()
{
boo();
}
int main()
{
boo();
return 0;
}
|
1 |
voidboo() { boo(); } intmain() { boo(); return; } |
В программе, приведенной выше, фрейм стека добавляется в стек каждый раз, когда вызывается функция boo(). Поскольку функция boo() вызывает сама себя бесконечное количество раз, то в конечном итоге в стеке не хватит памяти, что приведет к переполнению стека.
Стек имеет свои преимущества и недостатки:
Выделение памяти в стеке происходит сравнительно быстро.
Память, выделенная в стеке, остается в области видимости до тех пор, пока находится в стеке. Она уничтожается при выходе из стека.
Вся память, выделенная в стеке, обрабатывается во время компиляции, следовательно, доступ к этой памяти осуществляется напрямую через переменные.
Поскольку размер стека является относительно небольшим, то не рекомендуется делать что-либо, что съест много памяти стека (например, передача по значению или создание локальных переменных больших массивов или других затратных структур данных).
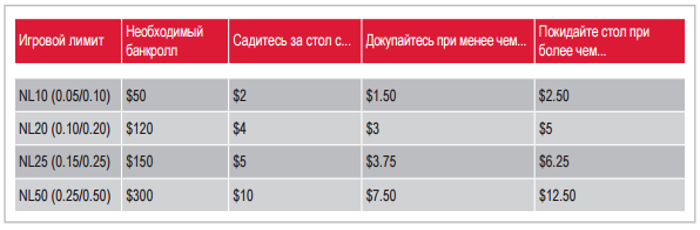
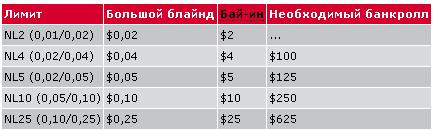
Правила для кэш-столов
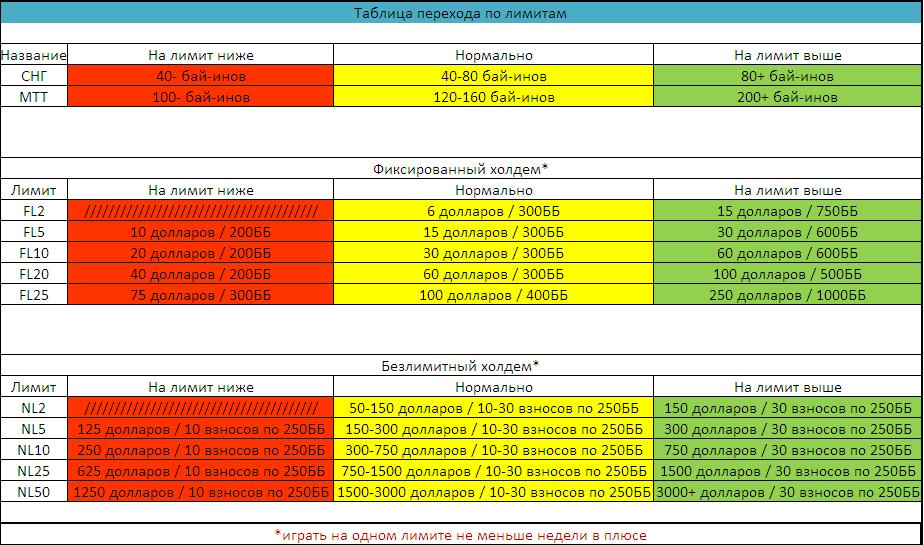
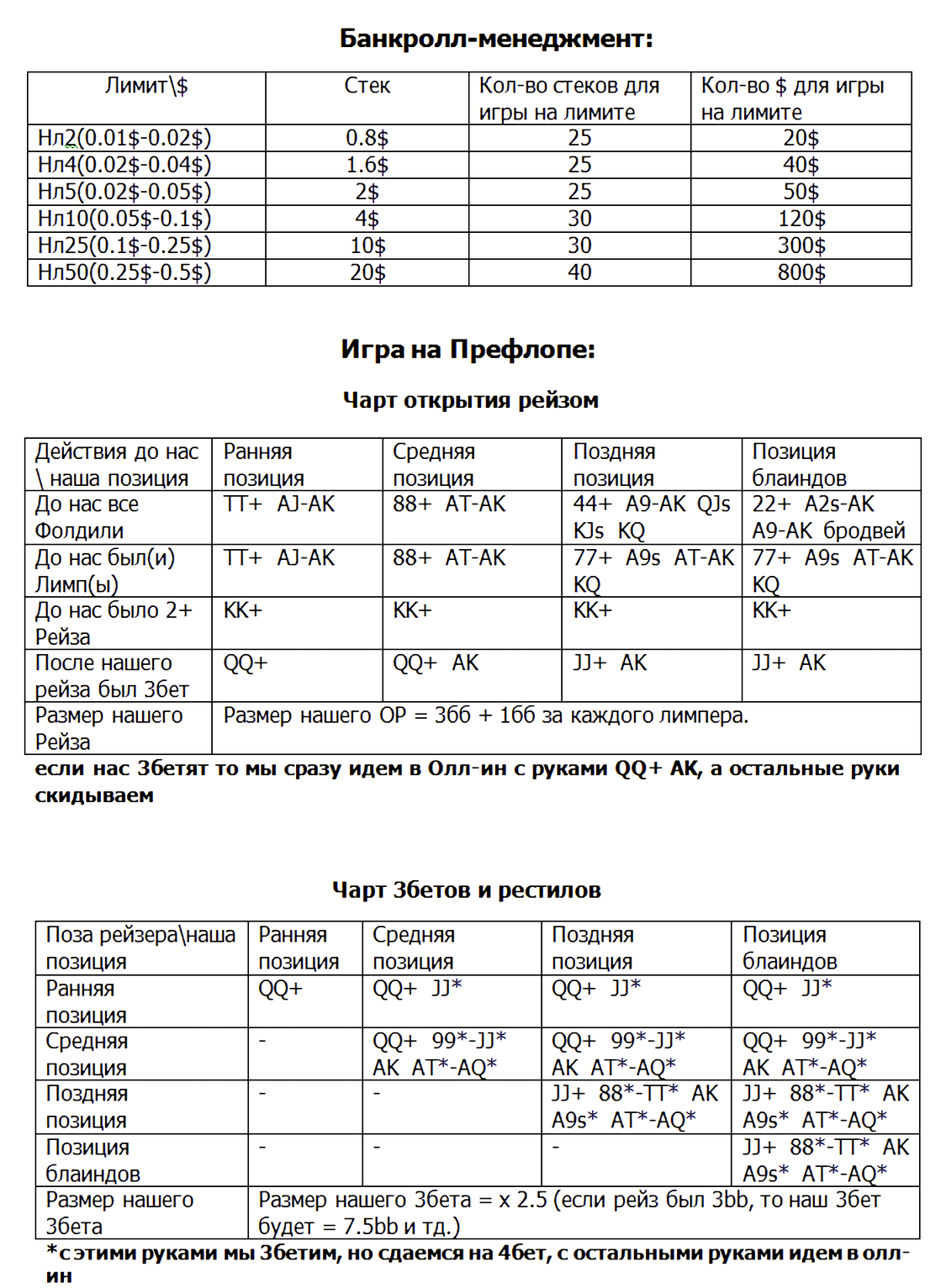
Для каждого кэш-стола устанавливается диапазон, регулирующий минимум и максимум количества денег, которые покерист может иметь за кэш-столом при посадке. Таким образом, новому участнику предоставляется возможность выбрать размер стека при посадке – установить бай-ин такого размера, который его устраивает, не выходя за рамки диапазона. Например, для столов с Безлимитным Холдемом со ставками 0,01/0,02$ стартовый стек или бай-ин примерно составит сумму от 0,80 до 2$. Однако по мере отыгрыша раздач его размер может меняться, так как пользователь может выигрывать или проигрывать фишки. При этом действуют следующие правила:
- Игрок может вести игру пока у него не закончатся фишки – если Стек в покере становится меньше минимального бай-ина, докупать его не требуется;
- Выигранные фишки можно использовать в игре – все деньги, которые пользователь выигрывает за столом, он может использовать для ставок, даже если его Стек становится больше, чем максимальный бай-ин;
- Докупка разрешена только между раздачами – в ходе раздачи нельзя добавить в Стек деньги, даже если ставка оппонента выше, чем запас оставшихся денег у Вас. В таком случае Вы можете сравнять только ту её часть, на которую хватает фишек. Между раздачами докупка допускается, но выходить за диапазоны бай-ина нельзя.
В турнирном покере размер стартового Стека определяется до начала события. Узнать, сколько фишек Вы получите при старте события можно из правила турнира. При этом все участники получают одинаковые Стеки, а докупки возможны только в том случае, если в турнире предусмотрены Ребаи и Аддоны.
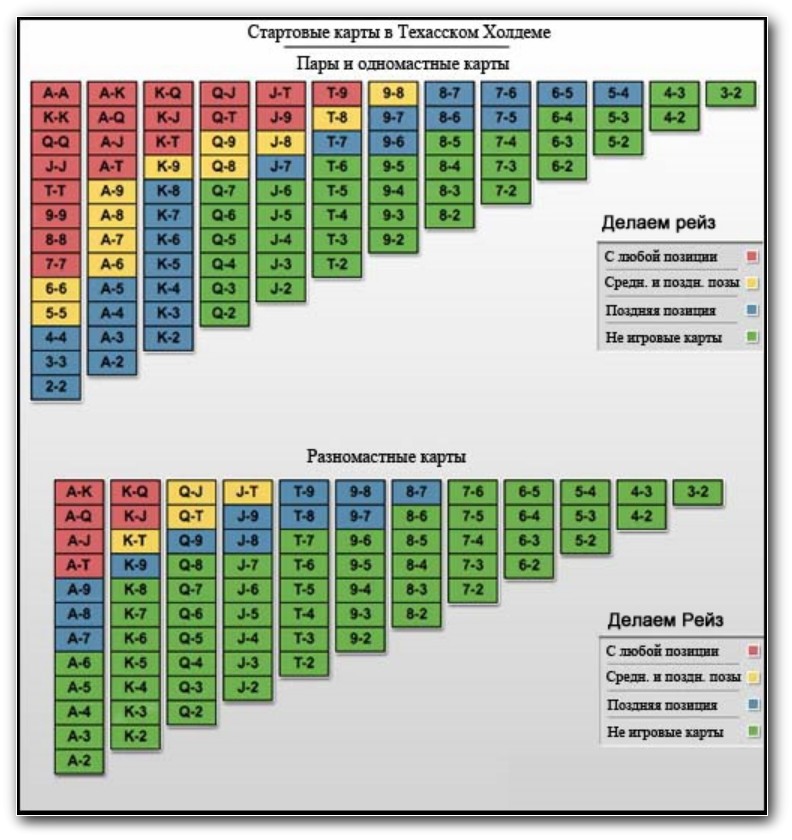
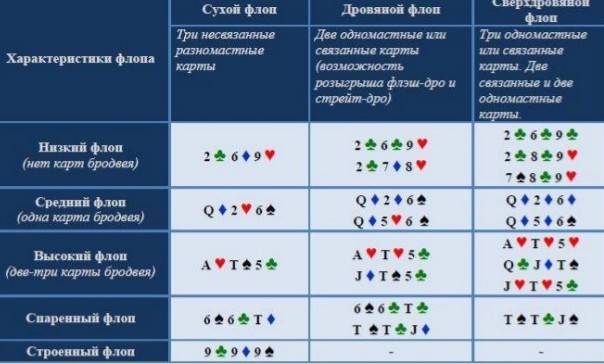


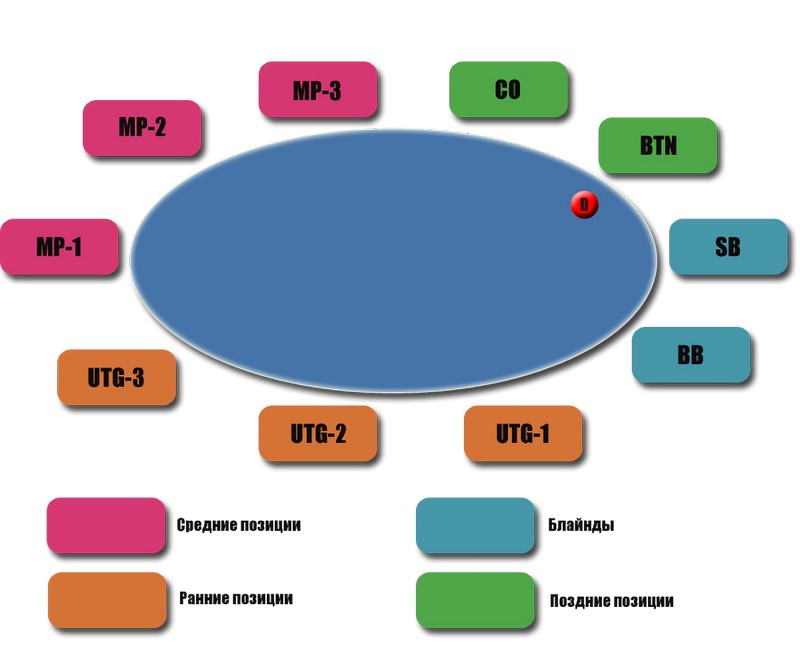
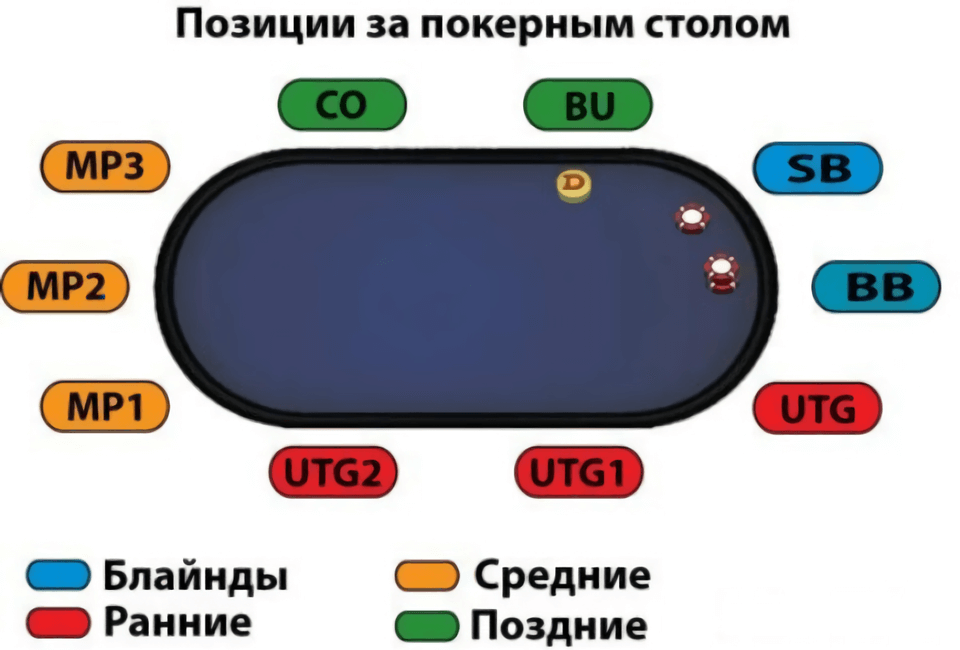


Сегменты
Память, которую используют программы, состоит из нескольких частей — сегментов:
Сегмент кода (или «текстовый сегмент»), где находится скомпилированная программа. Обычно доступен только для чтения.
Сегмент bss (или «неинициализированный сегмент данных»), где хранятся глобальные и статические переменные, инициализированные нулем.
Сегмент данных (или «сегмент инициализированных данных»), где хранятся инициализированные глобальные и статические переменные.
Куча, откуда выделяются динамические переменные.
Стек вызовов, где хранятся параметры функции, локальные переменные и другая информация, связанная с функциями.
Суть и понятие стека
Процессор и память — основные конструктивные элементы компьютера. Процессор исполняет команды, манипулирует адресами памяти, извлекает и изменяет значения по этим адресам. На языке программирования все это трансформируется в переменные и их значения. Суть стека и понятие last in first out (LIFO) остается неизменным.
Аббревиатура LIFO уже не используется так часто, как раньше. Вероятно потому, что списки трансформировались в объекты, а очереди first in first out (FIFO) применяются по мере необходимости. Динамика типов данных потеряла свою актуальность в контексте описания переменных, но приобрела свою значимость на момент исполнения выражений: тип данного определяется в момент его использования, а до этого момента можно описывать что угодно и как угодно.
Так, стек — что это такое? Теперь вы знаете, что это вопрос неуместный. Ведь без стека нет современного программирования. Любой вызов функции — это передача параметров и адреса возврата. Функция может вызвать другую функцию — это опять передача параметров и адреса возврата. Наладить механизм вызова значений без стека — это лишняя работа, хотя достижимое решение, безусловно, возможное.
Многие спрашивают: «Стек — что это такое?». В контексте вызова функции он состоит из трех действий:
- сохранения адреса возврата;
- сохранения всех передаваемых переменных или адреса на них;
- вызова функции.
Как только вызванная функция исполнит свою миссию, она просто вернет управление по адресу возврата. Функция может вызывать любое количество других функций, так как ограничение накладывается только размером стека.
Что такое эффективный Стек в покере
Есть такое понятие, как эффективный Стек, которое требуется знать каждому покеристу. С данным выражением Вы будете нередко сталкиваться при изучении покерной теории. По сути – это количество фишек, которое Вы сможете использовать в игре против определенного оппонента. Проще всего понять это определение можно с помощью наглядного примера:
Пример 1: У Вашего оппонента 80 долларов, а у Вас 100$. В раздаче, если Вы пойдете ва-банк, Вы сможете использовать только 80$, так как у соперника больше нет денег, и он не сможет вложить в банк столько же, сколько и Вы. Поэтому, рассчитывая прибыль от ставки, Вы должны учитывать не все 100$, а только 80$ – это и будет в данной раздаче эффективным стеком.
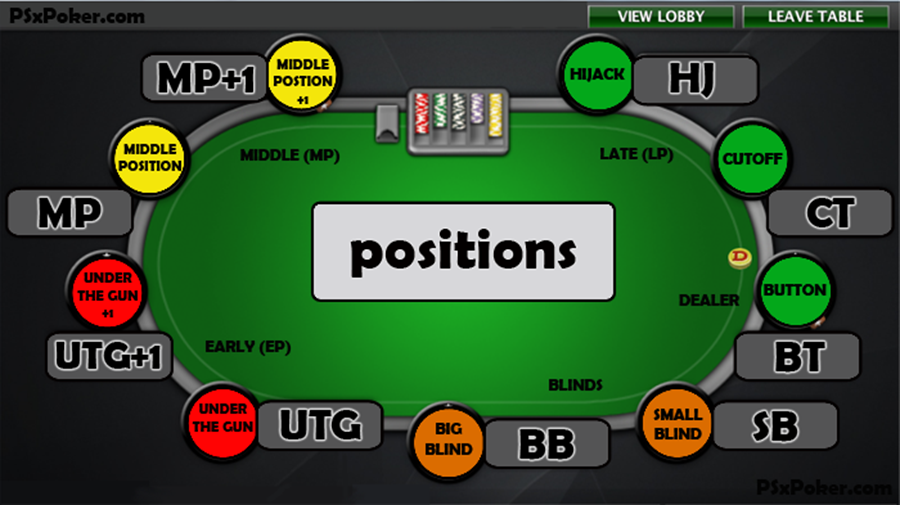
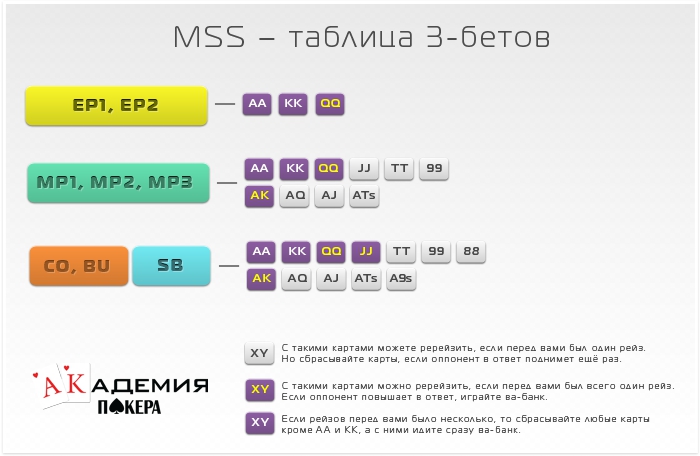

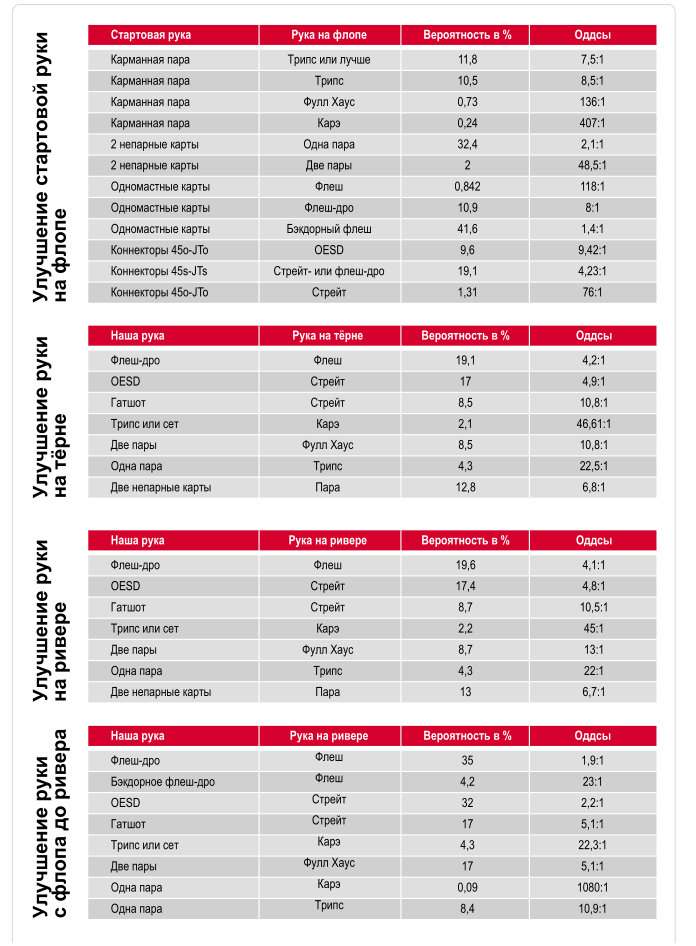

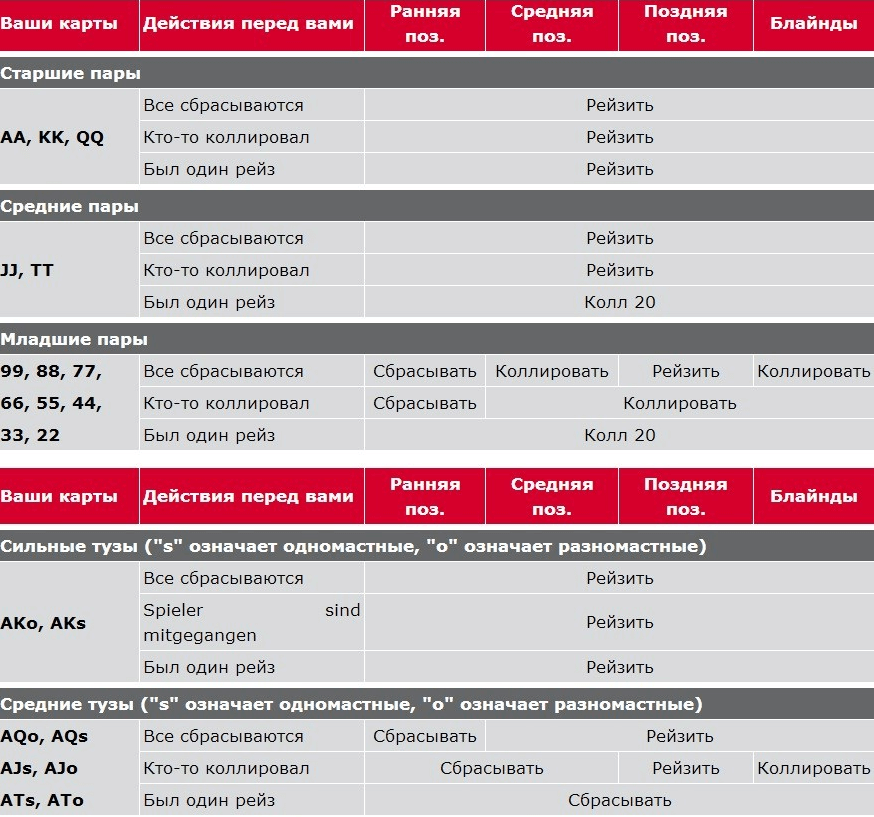

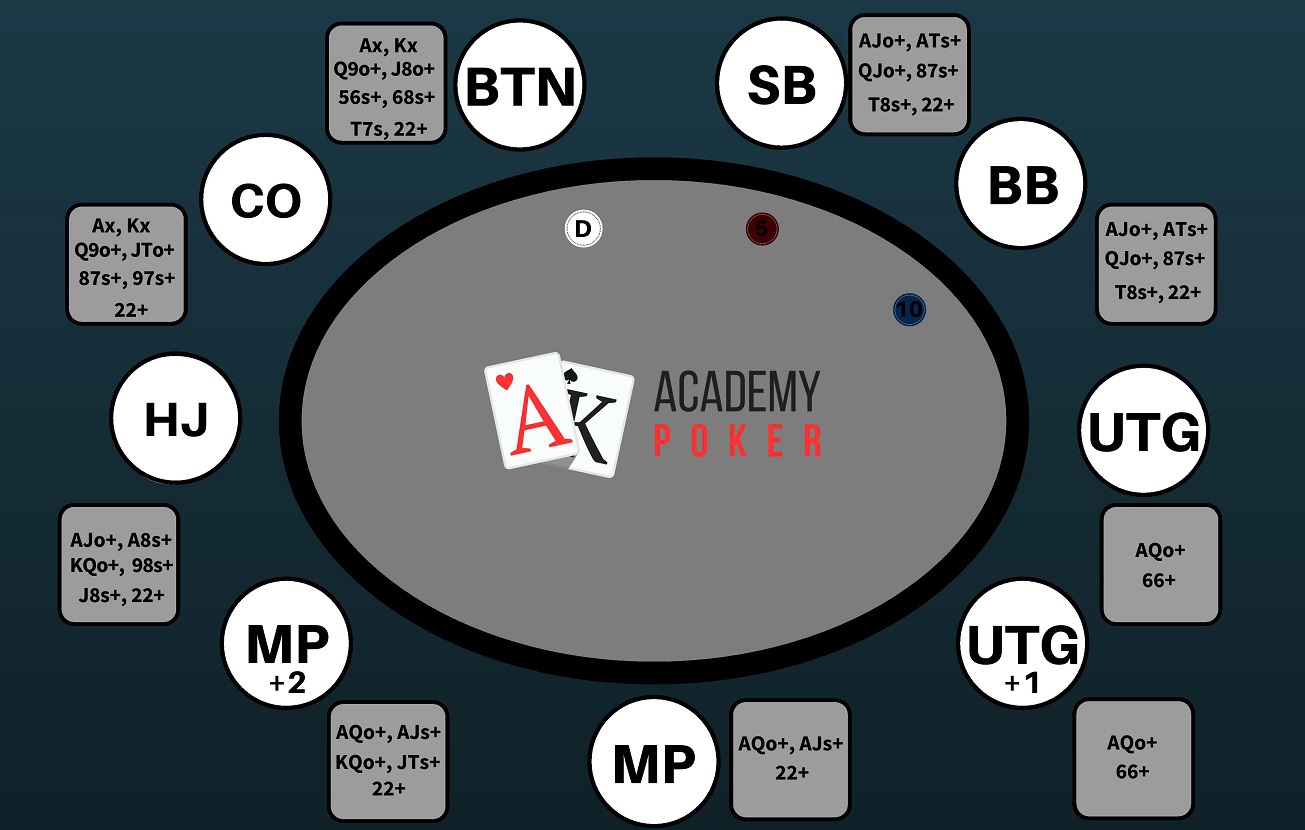

Учитывая данное понятие, Вы должны выбирать столы для игры с тем расчетом, чтобы Ваш стек оказывался эффективным при игре против как можно большего количества оппонентов. Например, для игры со 100$, Вам не подойдет стол, где сидят оппоненты, имеющие только 40-60$. Оптимальным столом будет тот, где у большинства участников больше фишек, чем у Вас.
Итак, теперь Вы знаете, что такое Стек в покере, и в каких случаях важен его размер. При формировании стратегии Вам необходимо определить эффективное количество фишек для игры, которое позволит Вам реализовывать математическое ожидание от конкретных решений и получать оптимальную прибыль.
Какой способ создания стека использовать
Сегодня мы изучили два способа реализации стека:
- С помощью шаблона C++.
- При помощи массива.
Если вы используете стек в вашей программе и вам лучше чтобы она работа как можно быстрее, то используйте первый способ реализации стека.
Если же вам все равно на быстродействие программы, то можете использовать создание стека через массив. Лично мы всегда используем первый способ реализации стека. Он быстр и прост для использования и объявления.
В следующем уроке мы изучим еще одну очень важную структуру данных — очередь. Эту структуру данных используют во многих мессенджерах (например, telegram).
Маленький итог
- При запуске новая Activity становится на вершину стека, смещая текущую
- При сворачивании приложения таск уходит в background и хранит свое состояния. После очередного запуска приложения таск восстанавливается вместе со своим стеком
- При нажатии back текущая Activity безвозвратно удаляется. На вершину стека ставится предыдущая
- Одна и та же Activity может иметь сколько угодно экземпляров в стеке
Атрибут launchMode
- standard — (по умолчанию) при запуске Activity создается новый экземпляр в стеке. Activity может размещаться в стеке несколько раз
- singleTop — Activity может распологаться в стеке несколько раз. Новая запись в стеке создается только в том случаи, если данная Activity не расположена в вершине стека. Если она на данный момент является вершиной, то у нее сработает onNewIntent() метод, но она не будет пересоздана
- singleTask — создает новый таск и устанавливает Activity корнeвой для него, но только в случаи, если экземпляра данной Activity нет ни в одном другом таске. Если Activity уже расположена в каком либо таске, то откроется именно тот экземпляр и вызовется метод onNewIntent(). Она в свое время становится главной, и все верхние экземпляры удаляются, если они есть. Только один экземпляр такой Activity может существовать
- singleInstance — тоже что и singleTask, но для данной Activity всегда будет создаваться отдельный таск и она будет в ней корневой. Данный флаг указывает, что Activity будет одним и единственным членом своего таска
Флаги
-
FLAG_ACTIVITY_NEW_TASK — запускает Activity в новом таске. Если уже существует таск с экземпляром данной Activity, то этот таск становится активным, и срабатываем метод onNewIntent().
Флаг аналогичен параметру singleTop описанному выше -
FLAG_ACTIVITY_SINGLE_TOP — если Activity запускает сама себя, т.е. она находится в вершине стека, то вместо создания нового экземпляра в стеке вызывается метод onNewIntent().
Флаг аналогичен параметру singleTop описанному выше - FLAG_ACTIVITY_CLEAR_TOP — если экземпляр данной Activity уже существует в стеке данного таска, то все Activity, находящиеся поверх нее разрушаются и этот экземпляр становится вершиной стека. Также вызовется onNewIntent()







