Механизм Лапласа
В связи с тем, что дифференциальная приватность является вероятностной концепцией, любой её метод обязательно имеет случайную составляющую. Некоторые из них, как и метод Лапласа, используют добавление контролируемого шума к функции, которую нужно вычислить.
Метод Лапласа добавляет шум Лапласа, то есть шум от распределения Лапласа, который может быть выражен функцией плотности вероятности noise(y)∝exp(−|y|λ){\displaystyle {\text{noise}}(y)\propto \exp(-|y|/\lambda )\,\!} и который имеет нулевое математическое ожидание и стандартное отклонение 2λ{\displaystyle {\sqrt {2}}\lambda \,\!}. Определим выходную функцию A{\displaystyle {\mathcal {A}}\,\!} как вещественнозначную функцию в виде TA(x)=f(x)+Y{\displaystyle {\mathcal {T}}_{\mathcal {A}}(x)=f(x)+Y\,\!} где Y∼Lap(λ){\displaystyle Y\sim {\text{Lap}}(\lambda )\,\!\,\!}, а f{\displaystyle f\,\!} — это запрос, который мы планировали выполнить в базе данных. Таким образом TA(x){\displaystyle {\mathcal {T}}_{\mathcal {A}}(x)\,\!} можно считать непрерывной случайной величиной, где
- pdf(TA,D1(x)=t)pdf(TA,D2(x)=t)=noise(t−f(D1))noise(t−f(D2)){\displaystyle {\frac {\mathrm {pdf} ({\mathcal {T}}_{{\mathcal {A}},D_{1}}(x)=t)}{\mathrm {pdf} ({\mathcal {T}}_{{\mathcal {A}},D_{2}}(x)=t)}}={\frac {{\text{noise}}(t-f(D_{1}))}{{\text{noise}}(t-f(D_{2}))}}\,\!}
которая не более e|f(D1)−f(D2)|λ≤eΔ(f)λ{\displaystyle e^{\frac {|f(D_{1})-f(D_{2})|}{\lambda }}\leq e^{\frac {\Delta (f)}{\lambda }}\,\!} (pdf — probability density function или функция плотности вероятности). В данном случае можно обозначить Δ(f)λ{\displaystyle {\frac {\Delta (f)}{\lambda }}\,\!} фактором конфиденциальности ε. Таким образом T{\displaystyle {\mathcal {T}}\,\!} в соответствие с определением является ε-дифференциально приватной. Если мы попытаемся использовать эту концепцию в вышеприведенном примере про наличие гастрита, то для того, чтобы A{\displaystyle {\mathcal {A}}\,\!} была ε-дифференциальный приватной функцией, должно выполняться λ=1ϵ{\displaystyle \lambda =1/\epsilon }, поскольку Δ(f)=1{\displaystyle \Delta (f)=1}).
Кроме шума Лапласа также можно использовать другие виды шума, например, гауссовский но они могут потребовать небольшого ослабления определения дифференциальной приватности.
Риски конфиденциальности в Интернете
Существуют целые компании, специализирующиеся на сборе информации о посетителях интернет-сайтов, отправляя рекламу на основе собранных данных.
Есть много способов предоставить личную информацию о себе, например, через соцсети или отправляя информацию о банке и кредитной карте на различные веб-сайты.
Более того, отслеживается и непосредственно поведение пользователя через историю просмотра, поисковые запросы и активность в соцсетях. Всё это помогает собрать наиболее нежелательные детали о личности, такие как: сексуальная ориентация, политические и религиозные взгляды, раса, пристрастие к наркотикам и уровень интеллекта. Но даже и без этого существуют способы отслеживать взаимодействие пользователя с сайтом, получая информацию о почтовом индексе, имени и адресе местонахождения.
В 1998 году FTC предупредила GeoCities за нарушение приватности пользователей.
Трекинг
Наверное, каждый из вас сталкивался с ситуацией, когда вы ввели в поиске какое-либо слово, затем, закрыв поиск, перешли на сайт и вам показывается реклама, связанная с недавними поисковыми запросами? Это и есть трекинг. Простейший пример трекинга − адресная реклама в рекламной сети Google.
У многих сегодня есть аккаунт в Google, который по умолчанию сохраняет все ваши поисковые запросы в поисковой системе Google. Эта информация используется рекламной сетью Google для вывода потенциально интересной вам рекламы. Аналогичным образом в России работает компания Яндекс.
Зачем это нужно? Google зарабатывает, когда вы кликаете на рекламное объявление. Компания заинтересована показывать актуальную вам рекламу. Поисковый гигант собирает иную информацию о вас, такую как пол, возрастная группа, язык, страна. Согласитесь, мужчину 50 лет из Магадана навряд ли заинтересует предложение покупки молодежной одежды для девушек в Лондоне.
Сегодня существует масса реализаций трекинга пользователей, например, трекинг по MAC-адресу. Ваш мобильный девайс или ноутбук при активном модуле Wi-Fi постоянно посылает сигналы, содержащие техническую информацию, в том числе и уникальный MAC-адрес устройства. Благодаря этой функции вы всегда можете находить Wi-Fi сети поблизости.
Отправляемые устройствами данные можно мониторить, тем самым отслеживая перемещения владельца. Данная система применяется торговыми сетями и спецслужбами для отслеживания пользователей.
Известно использование данной системы для поимки преступников, например, когда известен только MAC-адрес ноутбука преступника, а также то, что он появится в одном из ресторанов в центре города. Подобная система, при достаточном ее распространении, в течение нескольких секунд обнаружит преступника после того, как он включит свой ноутбук с Wi-Fi модулем.
Есть и более продвинутые технологии трекинга, например, Cross-device tracking.Мы будем подробно разбирать данную технологию в рамках нашего курса, так как она серьезно угрожает анонимности пользователей и, что еще печальнее, даже специалисты знают о ней немного. Технология Cross-device tracking немного похожа на 25-й кадр, только в данном случае используются звуки.





Изначально технология предполагала к рекламе на ТВ добавлять специальные звуковые маячки, которые бы могли воспринимать и обрабатывать мобильные девайсы, а затем передавать в единый центр обработки информации. Например, вы смотрите рекламу по Первому каналу, в этот момент раздается звуковой маячок. Его улавливает ваш мобильный и передает информацию в центр статистики, который собирает ее и затем может сказать, сколько человек видели рекламу, какие передачи и когда смотрели. Это гораздо эффективнее обзвонов и онлайн-опросов. Технология должна была позволить проводить высокоточную аналитику ТВ-рекламы и аудитории. Но разработка пошла не туда…
Согласитесь, ничто не мешает подобный сигнал издать компьютеру, владелец которого хочет оставаться анонимным. А мобильный телефон, где анонимность настроена не настолько качественно, примет этот сигнал и передаст информацию о владельце в единый центр.
Уровни конфиденциальности
Интернет и цифровая конфиденциальность рассматриваются иначе, чем традиционные ожидания приватности.
Конфиденциальность в Интернете в первую очередь касается защиты информации пользователя. Конфиденциальность информации касается сбора пользовательской информации из различных источников, что даёт отличный повод для дискуссий.
Люди, не сильно заботящиеся о приватности в Интернете, не должны достигать полной анонимности. Пользователь может защитить свою информацию посредством контролируемого раскрытия личной информации. Предоставление IP-адреса, нелично идентифицируемой и прочей информации может стать приемлемым компромиссом для удобства, которое пользователи могли бы потерять, используя обходные пути, необходимые для строго ограничения собираемой информации.
С другой стороны, некоторые пользователи хотят более высокой степени конфиденциальности. В этом случае они могут попытаться добиться полной анонимности в Интернете для обеспечения конфиденциальности — использовать Интернет, не предоставляя третьим лицам возможность связать действия в Интернете с личными данными пользователя Интернета. Стоит помнить, что когда вы заполняете формы для регистрации или покупаете товар, это отслеживается, и поскольку информация не является частной, некоторые компании отправляют интернет-пользователям рекламу об аналогичных продуктах.
Размещение чего-либо в Интернете может быть вредным или даже опасным (возможность для злонамеренной атаки). Некоторая информация, попадающая в Интернет, остаётся там навсегда, в зависимости от и определённых услуг, предлагаемых в Интернете. Некоторые работодатели могут исследовать потенциального сотрудника путём поиска в Интернете подробностей его поведения, что может повлиять на успех кандидата.
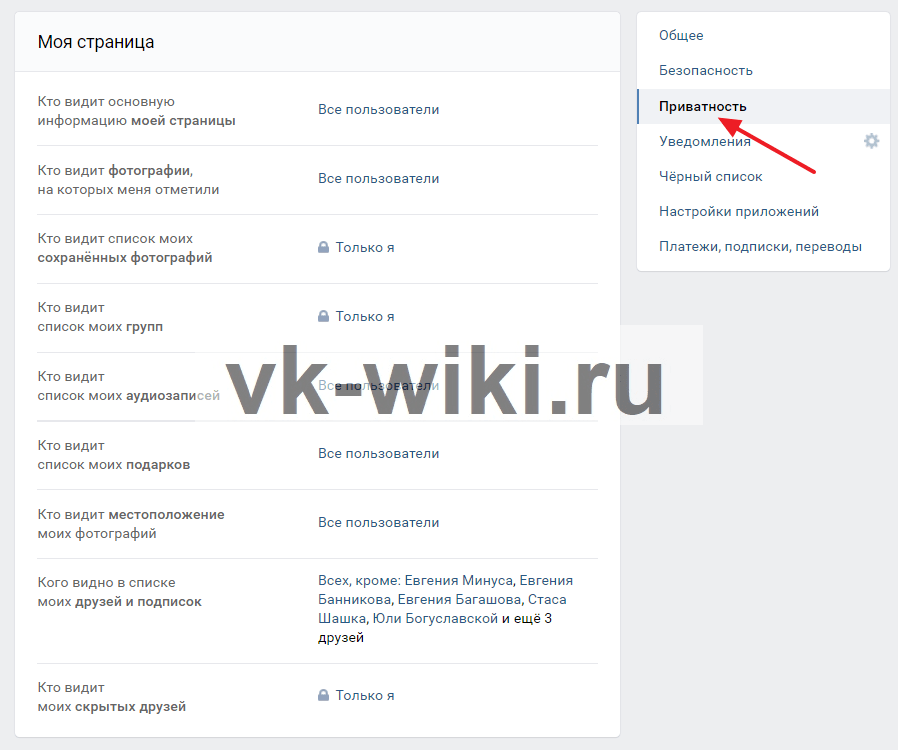
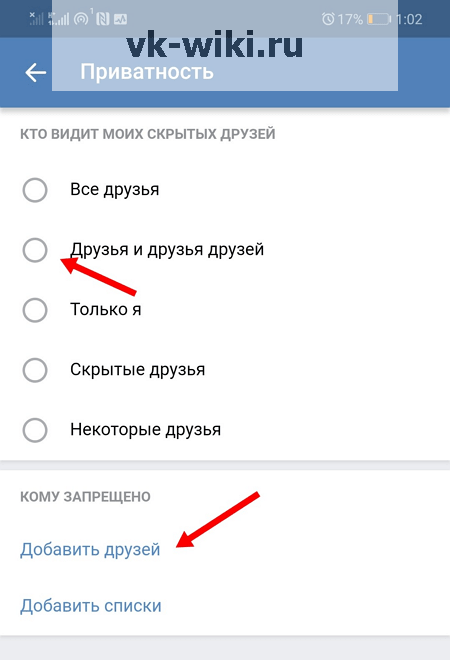
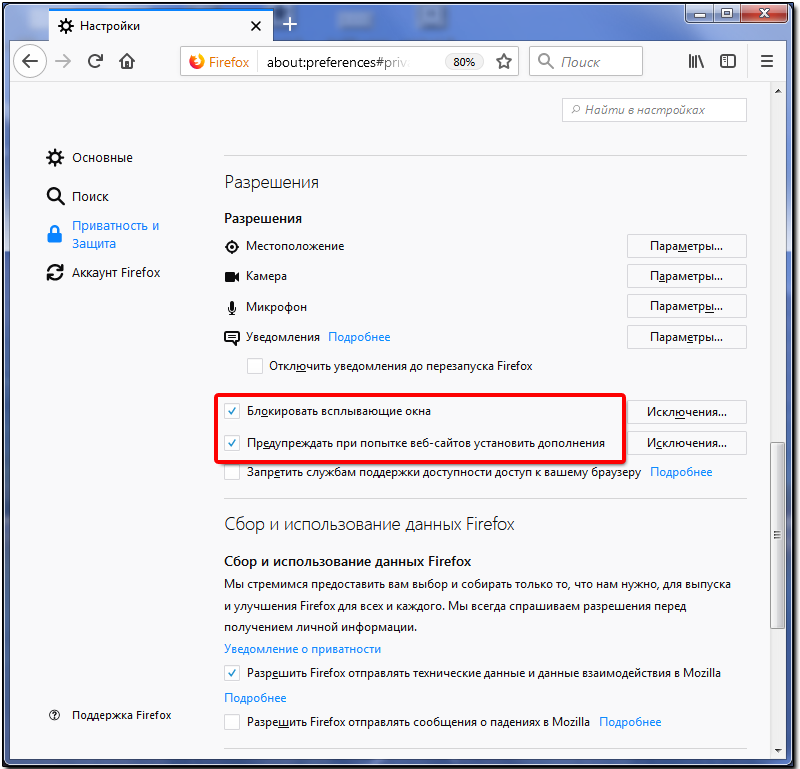
Покопайтесь в настройках социальных сетей
Социальные сети — публичные пространства, но не все публичные пространства одинаковы и не все публичные вещи следует показывать всем подряд. Во многих соцсетях можно выбрать, кто будет видеть определенный контент на вашей странице — все пользователи, только зарегистрированные, друзья и друзья друзей, только друзья и так далее.
В дополнение к этому в большинстве социальных сетей есть еще множество самых разных настроек. Вы можете, например, запретить показывать ваш профиль в результатах поиска или не дать другим пользователям отмечать вас в публикациях и писать вам сообщения. Так что если вы устали от навязчивых «друзей», спамеров и мошенников, поройтесь в настройках приватности , Instagram, , TikTok, «Одноклассников», и других сервисов.
Если хотите глубже погрузиться в изучение настроек соцсетей, рекомендуем воспользоваться нашим сервисом под названием Privacy Checker. Здесь подробно расписано, зачем нужна каждая настройка каждого сервиса (да еще и на каждой платформе), как использовать ее с умом и как ее применение скажется на вашем удобстве — как мы уже говорили, приватность требует определенных жертв.
Также Privacy Checker поможет вам настроить приватность в операционной системе.
Общественные взгляды
В то время, как конфиденциальность в Интернете широко признана в качестве основного источника внимания в любом интерактивном взаимодействии, как это видно в общественном простесте против SOPA/CISPA, общественное понимание политики конфиденциальности в Интернете фактически отрицательно сказывается на текущих тенденциях в отношении приватности в Интернете.
Пользователи имеют тенденцию избегать ознакомления с политикой конфиденциальности в Интернете. Соединяя это со всё более исчерпывающими лицензионными соглашениями, компании требуют, чтобы потребители согласились до использования своего продукта, поэтому потребители реже ознакамливаются со своими правами.
История
Широкое распространение это право получило на территории Европы в период буржуазных революций. Нормативно было закреплено в законодательстве Франции, в Конституции США и Билле о правах США до сих пор позитивно не закреплено, но выводится из ряда поправок к Конституции.
Впервые научно разработано в статье известных ученых-юристов С. Д. Уоррена и Л. Д. Брендайса «Право на частную жизнь», опубликованную в 1890 г. в США.




Впоследствии право на неприкосновенность частной жизни было поддержано серией прецедентов Верховного суда США, обосновавшего его существование и выводившего его из ряда поправок к Конституции США (Билль о правах).
В послевоенное время (40—50 гг.) было закреплено рядом международных договоров, нормы которых были имплементированы законодательством многих стран, в том числе и СССР (право на личную жизнь), а впоследствии и Россией.
Дальнейшее развитие право на неприкосновенность частной жизни получило в ряде прецедентов Европейского суда по правам человека в Страсбурге (известные прецеденты Принцесса Ганноверская против Германии, Знаменская против России, Фадеева против России и др.).
Риски конфиденциальности в Интернете
Существуют целые компании, специализирующиеся на сборе информации о посетителях интернет-сайтов, отправляя рекламу на основе собранных данных.
Есть много способов предоставить личную информацию о себе, например, через соцсети или отправляя информацию о банке и кредитной карте на различные веб-сайты.
Более того, отслеживается и непосредственно поведение пользователя через историю просмотра, поисковые запросы и активность в соцсетях. Всё это помогает собрать наиболее нежелательные детали о личности, такие как: сексуальная ориентация, политические и религиозные взгляды, раса, пристрастие к наркотикам и уровень интеллекта. Но даже и без этого существуют способы отслеживать взаимодействие пользователя с сайтом, получая информацию о почтовом индексе, имени и адресе местонахождения.
В 1998 году FTC предупредила GeoCities за нарушение приватности пользователей.
Избавьтесь от слежки в браузере
Когда вы заходите на сайт, срабатывает система аналитики — веб-трекер. Она следит за тем, кто и как часто посещает страницу. Как правило, эта система принадлежит какому-нибудь интернет-гиганту вроде Google или Facebook. Они используют информацию о посещенных вами сайтах, чтобы определять ваши интересы и предлагать «правильную» рекламу.
Чтобы избавиться от такого внимания, можно использовать режим «инкогнито». Но учтите, что приватный поиск скрывает не всю информацию о вас — кое-что все же будет видно сайтам, которые вы посещаете (и третьим сторонам, о которых вы даже и не подозреваете).
От чересчур любознательных сайтов и систем аналитики спасут специальные решения для блокировки веб-трекеров: например, компонент «Защита от сбора данных» в Kaspersky Security Cloud.
Однако ни блокировка веб-трекеров, ни режим «инкогнито» не помогут вам скрыться от вашего собственного интернет-провайдера. Он может собирать информацию о ваших действиях в Интернете и продавать ее или даже забрасывать вас рекламой (и такое бывает). Чтобы не допустить этого, используйте защищенный шифрованием тоннель между вашим устройством и удаленным сервером. В этом случае все, что увидит ваш провайдер — это сам факт подключения к этому серверу.
Мы, разумеется, для этих целей рекомендуем наше защищенное соединение — Kaspersky Secure Connection.
Кстати, некоторые браузеры и поисковые системы тоже собирают данные пользователей, чтобы показывать им рекламу. Не хотите такого? Тогда используйте браузер, который бережно отнесется к вашей приватности (например, Firefox), и поисковик, который не будет за вами шпионить (например, DuckDuckGo или Startpage.com). Но имейте в виду, что такая приватность требует жертв. Как правило, приватные поисковые системы выдают менее релевантные результаты, ведь они о вас ничего не знают.
У браузеров, выступающих против слежки, есть свой недостаток — несовместимость с некоторыми сайтами. Так, в Firefox некоторые страницы могут отображаться некорректно, поскольку чаще всего их адаптируют под считающийся золотым стандартом среди веб-дизайнеров браузер Google Chrome.
Общественные взгляды
В то время, как конфиденциальность в Интернете широко признана в качестве основного источника внимания в любом интерактивном взаимодействии, как это видно в общественном простесте против SOPA/CISPA, общественное понимание политики конфиденциальности в Интернете фактически отрицательно сказывается на текущих тенденциях в отношении приватности в Интернете.
Пользователи имеют тенденцию избегать ознакомления с политикой конфиденциальности в Интернете. Соединяя это со всё более исчерпывающими лицензионными соглашениями, компании требуют, чтобы потребители согласились до использования своего продукта, поэтому потребители реже ознакамливаются со своими правами.






Формальное определение и пример использования
Пусть ε — положительное действительное число и A — вероятностный алгоритм, который принимает на вход набор данных (представляет действия доверенной стороны, обладающей данными). Образ A обозначим imA. Алгоритм A является ε-дифференциально приватным, если для всех наборов данных D1{\displaystyle D_{1}} и D2{\displaystyle D_{2}}, которые отличаются одним элементом (то есть данными одного человека), а также всех подмножеств S множества imA:
PA(D1)∈S≤eϵ×PA(D2)∈S,{\displaystyle P\leq e^{\epsilon }\times P,}
где P — вероятность.
В соответствии с этим определением дифференциальная приватность является условием механизма публикации данных (то есть определяется доверенной стороной, выпускающей информацию о наборе данных), а не самим набором. Интуитивно это означает, что для любых двух схожих наборов данных, дифференциально-частный алгоритм будет вести себя примерно одинаково на обоих наборах. Определение также дает сильную гарантию того, что присутствие или отсутствие индивидуума не повлияет на окончательный вывод алгоритма.
Например, предположим, что у нас есть база данных медицинских записей D1{\displaystyle D_{1}} где каждая запись представляет собой пару (Имя, X), где X{\displaystyle X} является нулем или единицей, обозначающим, имеет ли человек гастрит или нет:
| Имя | Наличие гастрита (Х) |
|---|---|
| Иван | 1 |
| Петр | |
| Василиса | 1 |
| Михаил | 1 |
| Мария |
Теперь предположим, что злонамеренный пользователь (часто называемый злоумышленником) хочет найти, имеет ли Михаил гастрит или нет. Также предположим, что он знает, в какой строке находится информация о Михаиле в базе данных. Теперь предположим, что злоумышленнику разрешено использовать только конкретную форму запроса Qi{\displaystyle Q_{i}}, который возвращает частичную сумму первых i{\displaystyle i} строк столбца X{\displaystyle X} в базе данных. Чтобы узнать, есть ли гастрит у Михаила, противник выполняет запросы: Q4(D1){\displaystyle Q_{4}(D_{1})} и Q3(D1){\displaystyle Q_{3}(D_{1})}, затем вычисляет их разницу. В данном примере, Q4(D1)=3{\displaystyle Q_{4}(D_{1})=3}, а Q3(D1)=2{\displaystyle Q_{3}(D_{1})=2}, поэтому их разность равна 1{\displaystyle 1}. Это значит, что поле «Наличие гастрита» в строке Михаила должно быть равно 1{\displaystyle 1}. Этот пример показывает, как индивидуальная информация может быть скомпрометирована даже без явного запроса данных конкретного человека.
Продолжая этот пример, если мы построим D2{\displaystyle D_{2}} заменив (Михаил, 1) на (Михаил, 0), то этот злоумышленник сможет отличить D2{\displaystyle D_{2}} от D1{\displaystyle D_{1}} путем вычисления Q4−Q3{\displaystyle Q_{4}-Q_{3}} для каждого набора данных. Если бы злоумышленник получал значения Qi{\displaystyle Q_{i}} через ε-дифференциально приватный алгоритм, для достаточно малого ε, то он не смог бы отличить два набора данных.
Также пример с монеткой, описанный выше является (ln3){\displaystyle (\ln 3)}-дифференциально приватным.
Граничные случаи
Случай, когда ε = 0, является идеальным для сохранения конфиденциальности, поскольку наличие или отсутствие любого информации о любом человеке в базе данных никак не влияет на результат алгоритма, однако он является бессмысленным с точки зрения полезной информации, так как даже нулевом количестве людей он будет давать такой же или подобный результат.
Если устремить ε в бесконечность, то любой вероятностный алгоритм будет подходить под определение, поскольку неравенство PA(D1)∈S≤∞×PA(D2)∈S,{\displaystyle P\leq \infty \times P,} — выполняется всегда.
Чувствительность
Пусть d{\displaystyle d} — положительное целое число, D{\displaystyle {\mathcal {D}}} — набор данных и fD→Rd{\displaystyle f\colon {\mathcal {D}}\rightarrow \mathbb {R} ^{d}} — функция. Чувствительность функции, обозначаемая Δf{\displaystyle \Delta f}, определяется формулой
- Δf=max‖f(D1)−f(D2)‖1,{\displaystyle \Delta f=\max \lVert f(D_{1})-f(D_{2})\rVert _{1},}
по всем парам наборов данных D1{\displaystyle D_{1}} и D2{\displaystyle D_{2}} в D{\displaystyle {\mathcal {D}}}, отличающихся не более чем одним элементом и где ‖⋅‖1{\displaystyle \lVert \cdot \rVert _{1}} обозначает ℓ1{\displaystyle \ell _{1}} норму.
На выше приведенном примере медицинской базы данных, если мы рассмотрим чувствительность d{\displaystyle d} функции Qi{\displaystyle Q_{i}}, то она равна 1{\displaystyle 1}, так как изменение любой из записей в базе данных приводит к тому, что Qi{\displaystyle Q_{i}} либо изменится на 1{\displaystyle 1} либо не изменится.
Другие способы остаться приватным
Разобравшись, что такое приватный аккаунт, а также проведя необходимые манипуляции, можно установить дополнительные функции.
Для ограничения количества личной информации на своей странице, лучше использовать ненастоящее имя. Чтобы поменять его нужно:
- Коснуться значка учётной записи.
- Нажать «Изменить свой профиль».
- Выбрать любой из четырёх вариантов: имя, имя пользователя, веб-сайт, биография.
Кроме этого, есть возможность заблокировать любого человека, у которого был доступ к публикациям до установки настроек приватности:
- Выделить имя нужного человека, чтобы открыть его учётную запись.
- Кликнуть значок с тремя горизонтальными точками.
- Нажать «Заблокировать пользователя».
Теперь он не сможет видеть публикации, помимо этого оставленные им лайки, комментарии удалятся автоматически.
Приватность группы
Дифференциальная приватность в целом предназначена для защиты конфиденциальности между базами данных, которые отличаются только одной строкой. Это означает, что ни один злоумышленник с произвольной вспомогательной информацией не может узнать, представил ли какой-либо один отдельно взятый участник свою информацию. Однако это понятие можно расширить на группу, если мы хотим защитить базы данных, отличающиеся на c{\displaystyle c} строк, чтобы злоумышленник с произвольной вспомогательной информацией, не мог узнать, предоставили ли c{\displaystyle c} отдельных участников свою информацию. Это может быть достигнуто если в формуле из определения заменить exp(ϵ){\displaystyle \exp(\epsilon )} на exp(ϵc){\displaystyle \exp(\epsilon c)}, тогда для D1 и D2 отличающихся на c{\displaystyle c} строчек







- PrA(D1)∈S≤exp(ϵc)×PrA(D2)∈S{\displaystyle \Pr\leq \exp(\epsilon c)\times \Pr\,\!}
Таким образом, использование параметра (ε/c) вместо ε позволяет достичь необходимого результата и защитить c{\displaystyle c} строк. Другими словами, вместо того, чтобы каждый элемент был ε-дифференциально приватным, теперь каждая группа из c{\displaystyle c} элементов являются ε-дифференциально приватной, а каждый элемент (ε/c)-дифференциально приватным.
Исследования
В России наиболее значительные исследования данного права на монографическом уровне предпринимались М. Н. Малеиной (в контексте гражданского права), И. Л. Петрухиным, конституционалистами Г. Б. Романовским и И. М. Хужоковой.
Право на частную жизнь как отдельный институт права также был рассмотрен в монографии Кротова А. В. «Институт права на частную жизнь в Конституции РФ. Понятие и содержание». При этом в институт права на частную жизнь входят по мнению Кротова А. В. ряд конституционных прав и свобод, гарантирующих реализацию права на уважение частной жизни, закрепленного в статье 8 Конвенции о защите прав человека и основных свобод.
Право на неприкосновенность частной жизни может быть ограничено только в порядке, предусмотренном законодательством, как правило, только по судебному решению. И. М. Хужокова отмечает несоответствие Конституции РФ и норм Федерального конституционного закона «О чрезвычайном положении» современным реалиям ввиду того, что в тексте этих актов право на неприкосновенность частной жизни трактуется как не подлежащее ограничению, что является следствием его ошибочного толкования при имплементации из западных источников.
Риски конфиденциальности в Интернете
Существуют целые компании, специализирующиеся на сборе информации о посетителях интернет-сайтов, отправляя рекламу на основе собранных данных.
Есть много способов предоставить личную информацию о себе, например, через соцсети или отправляя информацию о банке и кредитной карте на различные веб-сайты.
Более того, отслеживается и непосредственно поведение пользователя через историю просмотра, поисковые запросы и активность в соцсетях. Всё это помогает собрать наиболее нежелательные детали о личности, такие как: сексуальная ориентация, политические и религиозные взгляды, раса, пристрастие к наркотикам и уровень интеллекта. Но даже и без этого существуют способы отслеживать взаимодействие пользователя с сайтом, получая информацию о почтовом индексе, имени и адресе местонахождения.
В 1998 году FTC предупредила GeoCities за нарушение приватности пользователей.
Direct
Разбираясь, что значит приватный аккаунт нельзя пройти мимо функции директ, потому что она тоже касается приватности. И даёт возможность отправлять публикации другим пользователям, но они не будут отображаться в общей ленте. Это удобно для тех, кто не хочет закрывать страницу полностью, но желает делиться фото, видео только с определёнными людьми. Пользоваться этим сервисом довольно легко:
- Перейти к разделу «Фото», из которого обычно отправляются публикации.
- Сделать снимок или найти его, перейдя к галерее устройства, при необходимости обработать, нажать «Далее». При опубликовании выбрать над фотографией «Direct».
- Добавить описание, отметить получателей, кликнув по аватарам из списка ниже.
- Кликнуть на галочку «Опубликовать».
После этого фото будет доступно только тем, кому оно адресовано.
Чем отличается приватный профиль от открытого
Чтобы лучше понять, что такое приват в инстаграме, нужно выделить главные отличия:
- для подписки на закрытую страницу, необходимо отправить запрос его владельцу, который решает, стоит ли разрешать этому человеку подписку;
- запросы подписчиков находятся в разделе «Действия», их можно подтвердить или проигнорировать;
- фотографии, видео из закрытых учётных записей не отображаются в общем поиске по хэштегам, поэтому их смогут найти только подписчики этих людей. Это также относится к геолокации;
- приватный аккаунт можно найти через поиск пользователей, но виден будет только аватар, ник, количество подписчиков, публикаций;
- комментарии, лайки закрытых аккаунтов могут видеть те, у кого есть доступ для просмотра этих публикаций. Ссылка на приватную страницу активна, но, когда по ней переходят не подписчики, они видят оповещение о включенных настройках конфиденциальности;
- один из важных моментов — даже если пользователь делает свои публикации закрытыми для Instagram, то при отправке их в социальные сети, они будут видны всем, кому открыт доступ страницы. То есть это зависит от настроек конфиденциальности другой соцсети.
Композиция
Последовательное применение
Если мы выполним запрос в ε-дифференциально защищенной T{\displaystyle T} раз, и вносимый случайный шум независим для каждого запроса, тогда суммарная приватность будет будет (εt)-дифференциальной. В более общем случае, если есть N{\displaystyle N} независимых механизмов: M1,…,Mn{\displaystyle {\mathcal {M}}_{1},\dots ,{\mathcal {M}}_{n}}, чьи гарантии приватности равны ϵ1,…,ϵn{\displaystyle \epsilon _{1},\dots ,\epsilon _{n}} соответственно, то любая функция g(M1,…,Mn){\displaystyle g({\mathcal {M}}_{1},\dots ,{\mathcal {M}}_{n})} будет (∑i=1nϵi){\displaystyle (\sum \limits _{i=1}^{n}\epsilon _{i})}-дифференциально приватной.
Параллельная композиция
Кроме того, если запросы выполняются на непересекающихся подмножествах базы данных, то функция g{\displaystyle g} была бы (maxiϵi){\displaystyle (\max _{i}{\epsilon }_{i})}-дифференциально приватной.
Пользуйтесь GDPR — его для вас же и придумали (если, конечно, вы европеец)
Когда в Европейском Союзе приняли регламент по защите персональных данных (GDPR), защита приватности вышла на новый уровень. Теперь, если вы попадаете под действие GDPR, вы можете запросить у любой компании данные, которые она собрала о вас. По закону компания обязана ответить вам и даже удалить какую-то информацию по вашему требованию.
Проблема в том, что многие просто не знают, что такое GDPR и как им пользоваться. Согласно результатам нашего опроса, четыре человека из пяти (82%) пытались удалить из Интернета личные данные, но меньше половины (37%) знало, как это сделать: как составить GDPR-запрос, куда его отправить, какие задавать вопросы, как правильно формулировать запросы и так далее. GDPR сложен, как и большинство юридических документов и процедур.




Здесь очень кстати придется новый сервис «Лаборатории Касперского» — Undatify. Он поможет частично автоматизировать отправку запроса на удаление данных и составить его в правильной форме. Также здесь вам разъяснят ответы компаний и помогут составить жалобу, если ответа не будет. Поскольку GDPR охраняет права только граждан Европейского Союза, сервис Undatify доступен только для них.
Прежде чем что-то публиковать, подумайте
Да, не вы за собой шпионите и нарушаете собственные границы, но ваша онлайн-приватность все же начинается с вас и ваших решений: того, какой информацией вы делитесь и что оставляете при себе.
Перед тем как что-нибудь опубликовать, подумайте о последствиях: не выкладывайте на всеобщее обозрение контент, который может нарушить вашу (или чью-то еще) приватность. Вы же не выложите на Facebook ваш пароль? Вот именно. И со всем остальным так же: не нужно публиковать то, что может рассказать о вас больше, чем следует — например, адрес, личный номер телефона, адрес электронной почты и так далее.
То же касается билетов на самолет и любых документов со штрихкодами или QR-кодами. Если вы сфотографировали билет на концерт с QR-кодом и выложили его в Instagram, считайте, что вы его уже кому-то подарили.
Если вы все же хотите выложить фото билета, позаботьтесь о том, чтобы не было видно QR-код и номер билета — их нужно хорошенько замазать в фоторедакторе. Мы уже писали о том, как замазывать что-либо на картинке правильно, чтобы потом нельзя было прочитать информацию. Но безопаснее, конечно, ничего не выкладывать вообще.







