Объектно-ориентированные субд
Появление объектно-ориентированных СУБД вызвано потребностями программистов на ОО-языках, которым были необходимы средства для хранения объектов, не помещавшихся в оперативной памяти компьютера. Также важна была задача сохранения состояния объектов между повторными запусками прикладной программы. Поэтому, большинство ООСУБД представляют собой библиотеку, процедуры управления данными которой включаются в прикладную программу. Примеры реализации ООСУБД как выделеного сервера базы данных крайне редки.
Сразу же необходимо заметить, что общепринятого определения «объектно-ориентированной модели данных» не существует. Сейчас можно говорить лишь о неком «объектном» подходе к логическому представлению данных и о различных объектно-ориентированных способах его реализации.
Структура
Структура объектной модели описываются с помощью трех ключевых понятий:
инкапсуляция — каждый объект обладает некоторым внутренним состоянием (хранит внутри себя запись данных), а также набором методов — процедур, с помощью которых (и только таким образом) можно получить доступ к данным, определяющим внутреннее состояние объекта, или изменить их. Таким образом, объекты можно рассматривать как самостоятельные сущности, отделенные от внешнего мира;
наследование — подразумевает возможность создавать из классов объектов новые классы объекты, которые наследуют структуру и методы своих предков, добавляя к ним черты, отражающие их собственную индивидуальность. Наследование может быть простым (один предок) и множественным (несколько предков);
полиморфизм — различные объекты могут по разному реагировать на одинаковые внешние события в зависимости от того, как реализованы их методы.
Целостность данных
Для поддержания целостности объектно-ориентированный подход предлагает использовать следующие средства:
автоматическое поддержание отношений наследования возможность объявить некоторые поля данных и методы объекта как «скрытые», не видимые для других объектов; такие поля и методы используются только методами самого объекта создание процедур контроля целостности внутри объекта
Средства манипулирования данными
К сожалению, в объектно-ориентированном программировании отсутствуют общие средства манипулирования данными, такие как реляционная алгебра или реляционное счисление. Работа с данными ведется с помощью одного из объектно-ориентированных языков программирования общего назначения, обычно это SmallTalk, C++ или Java.
В объектно-ориентированных базах данных, в отличие от реляционных, хранятся не записи, а объекты. ОО-подход представляет более совершенные средства для отображения реального мира, чем реляционная модель, естественное представление данных. В реляционной модели все отношения принадлежат одному уровню, именно это осложняет преобразование иерархических связей модели «сущность-связь» в реляционную модель. ОО-модель можно рассматривать послойно, на разных уровнях абстракции. Имеется возможность определения новых типов данных и операций с ними.
В то же время, ОО-модели присущ и ряд недостатков:
осутствуют мощные непроцедурные средства извлечения объектов из базы. Все запросы приходится писать на процедурных языках, проблема их оптимизации возлагается на программиста;
вместо чисто декларативных ограничений целостности (типа явного объявления первичных и внешних ключей реляционных таблиц с помощью ключевых слов PRIMARY KEY и REFERENCES) или полудекларативных триггеров для обеспечения внутренней целостности приходится писать процедурный код.
Очевидно, что оба эти недостатка связаны с отсутствием развитых средств манипулирования данными. Эта задача решается двумя способами — расширение ОО-языков в сторону управления данными (стандарт ODMG), либо добавление объектных свойств в реляционные СУБД (SQL-3, а также так называемые объектно-реляционных СУБД).
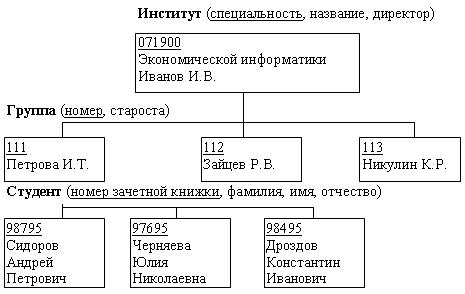
Какая модель данных называется «иерерхической»?
Описание отображаемой
предметной области в иерархической
модели данных базируется на гипотезе
о том, что моделируемую область можно
рассматривать как иерархию объектов.
Вся предметная
область, представляющая некоторый класс
объектов, разбивается на подклассы,
каждый подкласс на подклассы более
низкого уровня и т.д. Это модель типа
дерево.1
Иерархическая
модель организует данные в виде структуры,
состоящей из узлов и ветвей (рис. 4.1).
Наивысший уровень называется корнем.
На нижних уровнях находятся предки по
отношению к нижестоящим узлам и потомки
по отношению к вышестоящим. Каждый
потомок может быть связан только с одним
предком, а один предок может иметь 0, 1
или N
потомков. Доступ к каждому потомку
выполняется через его непосредственного
предка, и существует единственный
иерархический путь доступа к любому
узлу, начинающийся с корня дерева. В
схеме иерархической БД узлы иерархической
модели представляют сущности
(информационные объекты), а дуги – связи
между ними. Для БД определен порядок
обхода – «сверху — вниз», «слева —
направо». В иерархической БД для
поддержания целостности данных должно
выполняться правило: никакой потомок
не может существовать без своего предка.
Достоинствами
этой модели являются простота понимания
и использования. Такая модель удобна
для работы с иерархически упорядоченной
информацией. Иерархическая модель
данных, как показала практика, позволяет
эффективно использовать память компьютера
и демонстрирует достаточно высокую
скорость выполнения основных операций
над данными.
Недостатки модели
– в первую очередь, ее не универсальность:
для большинства задач требуется
дублирование данных, возможна потеря
данных, связи «многие — ко — многим» (см.
ниже) могут быть реализованы только
искусственно при избыточности данных;
а во вторую очередь – допустимость
только навигационного принципа доступа
к данным, (последовательным перемещением
по БД для нахождения требуемой записи),
записи извлекаются по одной, и чтобы
извлечь некое множество данных, нужно
повторять операции извлечения повторно.
Непосредственный доступ
по ключу
(см. ниже), как правило, возможен только
к объекту самого высокого уровня
(корневому).
Для обработки информации с достаточно
сложными логическими связями иерархическая
модель подходит плохо, поскольку
становится громоздкой и сложной для
понимания обычного пользователя.
На иерархической
модели основано сравнительно небольшое
число СУБД.
Объектные модели данных, каковы основные концепции модели?
При
построении объектных моделей данных
используются такие понятия, как сущности,
атрибуты и связи.
Сущность
– это отдельный элемент организации,
который должен быть представлен в БД.
Атрибут
– свойство, которое описывает некоторый
аспект объекта и значение которого
следует зафиксировать.
Связь
– это ассоциативное отношение между
сущностями.
Наиболее
общие типы объектных моделей данных:
1)
модель типа «сущность-связь» или
ER-модель;
2)
семантическая модель, то есть модель,
которая несет большую смысловую нагрузку,
чем просто значения данных;
3)
функциональная модель;
4)
обектно-ориентированная модель.
Модели — это сущности, а не таблицы
В большинстве случаев проектирование системы начинается именно со структуры данных (БД).
И дальше уже проектирование моделей также отталкивается от их хранения, т.е. от таблиц.
Но это в корне неправильный подход.






Рассмотрим подробнее на примере блога.
Какие модели мы имеем:
- Пост
- Автор
- Комментарий
- Тэги
- Категории
Чтобы не было нагромождения кода, рассматривать будем только модель поста и наращивать функционал будет постепенно.
Начнем с поста:
Работа с такой моделью и репой, будет выглядеть примерно так:
Теперь внедрим сущность , для этого нам нужно добавить методы в исходную модель:
Пример работы:
Теперь внедрим сущность , в данной ситуации тоже бы добавить сеттер и соответствующее поле, но если говорить про бизнес-смыслы, то у нас нет такого понятия как «указать комментарии», у нас есть такие понятия как «добавить комментарий» и «удалить комментарий».
Поэтому нашу исходную модель преобразуем таким образом:
Работа с комментариями в таком случае у нас будет выглядеть так:
В момент сохранения поста, у нас также должны обрабатываться удаление и добавление комментариев.
Но сам не должен работать с хранилищем комментариев, он должен делегировать это на .
То есть репозиторий постов, должен выглядеть примерно так:
При этом важно учесть, что если мы посмотрим на связь «пост — комментарий» со стороны комментария, то у нас не должно быть метода , т.к. он нарушает связь «целое — часть»
Причем метод эту логику не нарушает и вполне может существовать.
В примере ниже, мы меняем «владельца» комментария, что противоречит бизнес-логике: мы не можем комментарий переместить в другой пост, мы можем только добавить, удалить или изменить комментарий.
Перейдем к сущности , если говорить про бизнес-смысл, то здесь вполне корректным является действие «установить тэги».
Но если говорить про удобство использования, методы и также стоит добавить.
Таким образом дополняем модель следующими методами:
Работа с тегами будет выглядеть так:
Если посмотреть на связь «пост — тэги» со стороны сущности , то мы опять не может добавить метод т.к. нарушаем связь «целое — часть» (потому что , а не ).






Но при этом и метод мы также не можем использовать, потому что он также нарушает связь «целое — часть».
Правильным решение будет вынести метод получения списка постов конкретного тега в репозиторий:
Ну и наконец перейдем к сущности .
Казалось бы тут все тоже самое что и у тэгов, но как раз наоборот: с точки зрения бизнес-логики посты являются частью категорий, т.е. посты «складываются» в категории как в папки, а не категории привязываются к постам, как в случае с тэгами.
Поэтому в модель поста вы добавляем лишь геттер:
А работа с категориями будет выглядеть так:
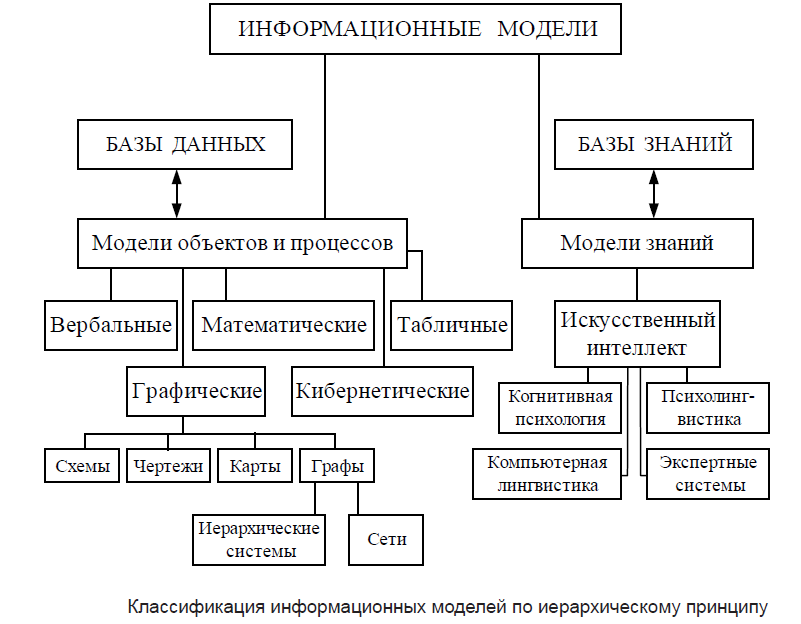
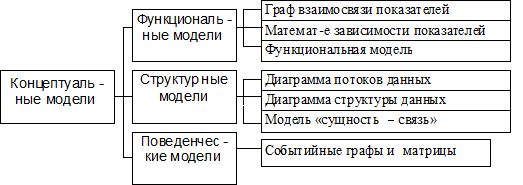
Классификация моделей данных
При трехуровневой архитектуре понятие модели данных относится к каждому уровню. Физическая модель данных использует категории, которые касаются организации внешней памяти и структур хранения в данной операционной среде. Сегодня в качестве физических моделей используют разные методы размещения данных, которые основаны на файловых структурах: файлы прямого и последовательного доступа, индексные файлы и инвертированные файлы, файлы, использующие разные методы хеширования, взаимосвязанные файлы. Также в современных СУБД широко используется страничная организация данных. Физические модели данных, которые основаны на страничной организации, признаны наиболее перспективными.
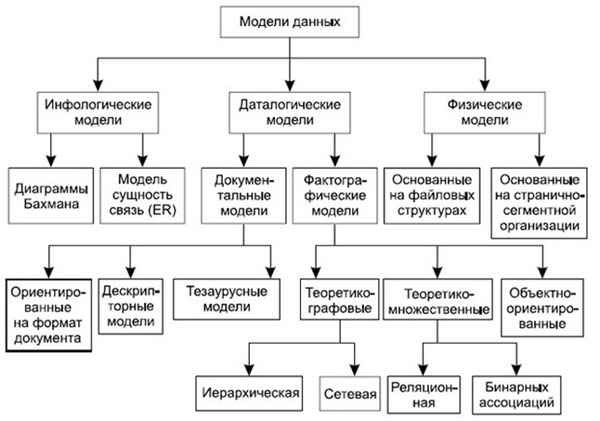
Модели данных, которые используются на концептуальном уровне, вызывают наибольший интерес. Внешние модели по отношению к ним называют подсхемами и ими используются те же абстрактные категории, что и в концептуальных моделях данных.
При проектировании баз данных имеет место еще один уровень, который им предшествует.
Определение 3
Модель этого уровня выражает информацию о предметной области в таком виде, который не зависит от используемой СУБД. Такие модели называются инфологическими (семантическими).
Инфологические модели данных используют на ранних стадиях проектирования с целью описать структуры данных при разработке приложения, а даталогические модели уже поддерживает конкретная СУБД.
Определение 4
Документальные модели данных представляют собой слабо структурированную организацию информации, которая ориентирована зачастую на свободные форматы текстов на естественном языке и документов.
Модели, которые основаны на языках разметки документов, прежде всего связаны со стандартным общим языком разметки – SGML (Standard Generalized Markup Language), утвержденным ISO как стандарт еще в 1980-х гг. Язык SGML применяется для создания других языков разметки, им определяется допустимый набор тегов (ссылок), их атрибуты и внутренняя структура документа. Контроль правильности использования тегов выполняется с помощью DTD-описаний (специальный набор правил). Из-за сложности SGML используется в основном для описания синтаксиса других языков (наиболее известный из них HTML) и напрямую с SGML-документами работали немногие приложения.
Язык HTML, более простой и удобный, предоставляет возможность определить оформление элементов документа и содержит набор инструкций – тегов, с помощью которых выполняется разметка. Команды HTML прежде всего предназначены для управления выводом содержимого документа на экран программы-клиента.
Более мощным, гибким и удобным языком гипертекстовой разметки является XML.
XML (Extensible Markup Language) является языком разметки, который описывает целый класс объектов данных – XML-документов. Его используют для описания грамматики других языков и как средство контроля правильности составления документов. Т.е. XML не содержит никаких тегов, а просто определяет порядок их создания.
Основой тезаурусных моделей является принцип организации словарей, которые содержат определенные языковые конструкции и правила их взаимодействия в определенной грамматике.
Такие модели эффективно используют в системах-переводчиках, особенно многоязыковых.
Дескрипторные модели являются самыми простыми из документальных моделей. Их широко применяли на ранних стадиях использования документальных БД. Каждому документу соответствовал дескриптор – описатель, который обладал жесткой структурой и описывал документ соответственно тем характеристикам, которые необходимы для работы с документами.








Данные, которые хранятся в БД, описываются моделью данных, которая поддерживается СУБД. К классическим относятся модели данных:
- иерархическая;
- сетевая;
- реляционная.
В последнее время разработаны и активно внедряются модели данных:
- постреляционная;
- многомерная;
- объектно-ориентированная.
Ведется разработка всевозможных систем, основанных на других моделях данных, которые расширяют известные модели. К ним можно отнести ориентированные, концептуальные, семантические, дедуктивно-объектно-ориентированные и объектно-реляционные модели.
Типы
Модель базы данных
Модель базы данных — это спецификация, описывающая структуру и использование базы данных.
Было предложено несколько таких моделей. Общие модели включают:
- Плоская модель
- Это не может строго квалифицироваться как модель данных. Плоская (или табличная) модель состоит из одного двумерного массива элементов данных, где предполагается, что все элементы данного столбца имеют одинаковые значения, а все элементы строки связаны друг с другом.
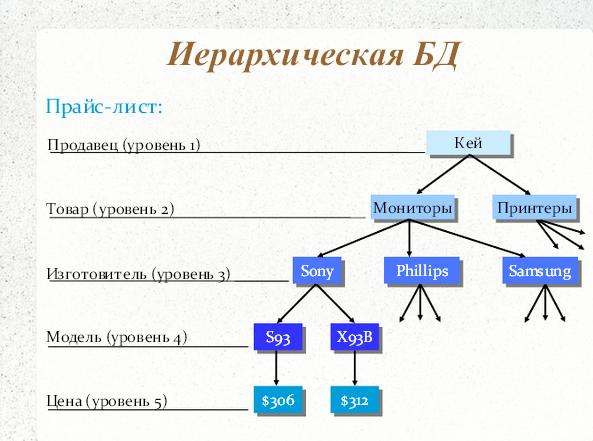
- Иерархическая модель
- Иерархическая модель аналогична сетевой модели, за исключением того, что связи в иерархической модели образуют древовидную структуру, а сетевая модель допускает произвольный граф.
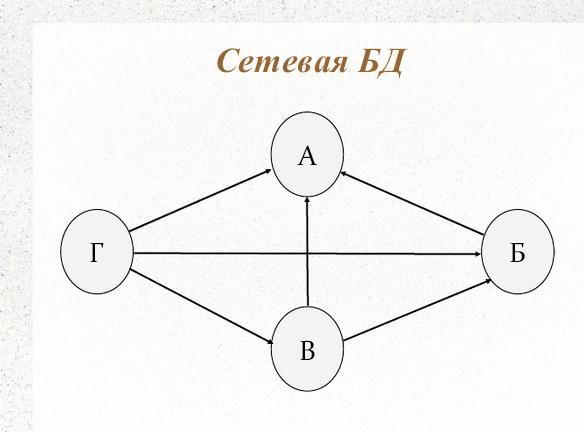
- Сетевая модель
- Эта модель организует данные с помощью двух фундаментальных конструкций, называемых записями и наборами. Записи содержат поля, а наборы определяют отношения «один ко многим» между записями: один владелец, много членов. Сетевая модель данных — это абстракция концепции проекта, используемой при реализации баз данных.
- Реляционная модель
- — это модель базы данных, основанная на логике предикатов первого порядка. Его основная идея состоит в том, чтобы описать базу данных как набор предикатов для конечного набора переменных предиката, описывая ограничения на возможные значения и комбинации значений. Сила реляционной модели данных заключается в ее математической основе и простой парадигме пользовательского уровня.
- Объектно-реляционная модель
- Подобно модели реляционной базы данных, но объекты, классы и наследование напрямую поддерживаются в схемах баз данных и на языке запросов.
- Объектно-ролевое моделирование
- Метод моделирования данных, который был определен как «свободный от атрибутов» и «основанный на фактах». Результатом является проверяемая правильная система, из которой могут быть получены другие общие артефакты, такие как ERD, UML и семантические модели. Связи между объектами данных описываются во время процедуры проектирования базы данных, поэтому нормализация является неизбежным результатом процесса.
- Схема звездочки
- Самый простой стиль схемы хранилища данных. Схема типа «звезда» состоит из нескольких «таблиц фактов» (возможно, только одной, оправдывающей название), ссылающихся на любое количество «таблиц измерений». Схема «звезда» считается важным частным случаем схемы «снежинка» .
Схема структуры данных
Пример диаграммы структуры данных
Диаграмма структуры данных (DSD) — это диаграмма и модель данных, используемые для описания концептуальных моделей данных путем предоставления графических обозначений, которые документируют сущности и их отношения , а также связывающие их ограничения . Основными графическими элементами DSD являются блоки , представляющие сущности, и стрелки , представляющие отношения. Диаграммы структуры данных наиболее полезны для документирования сложных объектов данных.
Диаграммы структуры данных являются расширением модели сущность-связь (модель ER). В DSD атрибуты указываются внутри блоков сущностей, а не вне их, в то время как отношения изображаются как блоки, состоящие из атрибутов, которые определяют ограничения, связывающие сущности вместе. DSD отличаются от модели ER тем, что модель ER фокусируется на отношениях между различными объектами, тогда как DSD фокусируется на отношениях элементов внутри объекта и позволяет пользователям полностью видеть связи и отношения между каждым объектом.
Пример диаграмм отношений IDEF1X Entity, используемых для моделирования самого IDEF1X
Географическая модель данных
- вектор модель данных представляет географию как наборы точек, линий и полигонов;
- модель растровых данных представляет географию в виде матриц ячеек, хранящих числовые значения;
- а модель данных триангулированной нерегулярной сети (TIN) представляет географию в виде наборов смежных неперекрывающихся треугольников.
Семантическая модель данных
Семантические модели данных
Семантическая модель данных в программной инженерии — это метод определения значения данных в контексте их взаимосвязей с другими данными. Семантическая модель данных — это абстракция, которая определяет, как хранимые символы относятся к реальному миру. Семантическую модель данных иногда называют концептуальной моделью данных .
Мультимодельные СУБД «без основной модели»
На рынке также представлены СУБД, позиционирующие себя как изначально мультимодельные, не имеющие никакой унаследованной основной модели. К их числу относятся ArangoDB, OrientDB (c 2018 года компания-разработчик принадлежит SAP) и CosmosDB (сервис в составе облачной платформы Microsoft Azure).
На самом деле «основные» модели в ArangoDB и OrientDB есть. Это в том и в другом случае собственные модели данных, являющиеся обобщениями документной. Обобщения заключаются в основном в облегчении возможности производить запросы графового и реляционного характера.
Эти модели являются в указанных СУБД единственно доступными для использования, для работы с ними предназначены собственные языки запросов. Безусловно, такие модели и СУБД перспективны, однако отсутствие совместимости со стандартными моделями и языками делает невозможным использование этих СУБД в унаследованных системах — замену ими уже используемых там СУБД.
Про ArangoDB и OrientDB на Хабре уже была замечательная статья: JOIN в NoSQL базах данных.
ArangoDB
ArangoDB заявляет поддержку графовой модели данных.
Узлы графа в ArangoDB — это обычные документы, а ребра — документы специального вида, имеющие наряду с обычными системными полями (, , ) системные поля и . Документы в документных СУБД традиционно объединяются в коллекции. Коллекции документов, представляющих ребра, в ArangoDB называются edge-коллекциями. К слову, документы edge-коллекций — это тоже документы, поэтому ребра в ArangoDB могут выступать также и узлами.
OrientDB
В основе реализации графовой модели поверх документной в OrientDB лежит возможность полей документов иметь помимо более-менее стандартных скалярных значений еще и значения таких типов, как , , , и . Значения этих типов — ссылки или коллекции ссылок на системные идентификаторы документов.
Присваиваемый системой идентификатор документа имеет «физический смысл», указывая позицию записи в базе, и выглядит примерно так: . Тем самым значения ссылочных свойств — действительно скорее указатели (как в графовой модели), а не условия отбора (как в реляционной).
Как и в ArangoDB, в OrientDB ребра представляются отдельными документами (хотя если у ребра нет своих свойств, его можно сделать легковесным, и ему не будет соответствовать отдельный документ).
Azure CosmosDB
В меньшей степени сказанное выше об ArangoDB и OrientDB относится к Azure CosmosDB. CosmosDB предоставляет следующие API доступа к данным: SQL, MongoDB, Gremlin и Cassandra.








SQL API и MongoDB API используются для доступа к данным в документной модели. Gremlin API и Cassandra API — для доступа к данным соответственно в графовой и колоночной. Данные во всех моделях сохраняются в формате внутренней модели CosmosDB: ARS («atom-record-sequence»), которая также близка к документной.
Но выбранная пользователем модель данных и используемый API фиксируются в момент создания аккаунта в сервисе. Невозможно получить доступ к данным, загруженным в одной модели, в формате другой модели, что иллюстрировалось бы примерно таким рисунком:
Тем самым мультимодельность в Azure CosmosDB на сегодняшний день представляет собой лишь возможность использовать несколько баз данных, поддерживающих различные модели, от одного производителя, что не решает всех проблем многовариантного хранения.
Что такое информация и информатика?

Чтобы перейти к изучению структуры модели данных, нужно понять, что эти данные и информация представляют из себя в принципе.
Абсолютно в любой момент существования человеческого общества огромную роль играла информация, то есть сведения, получаемые человеком из обширного и разнообразного окружающего нас мира. Например, даже первобытные люди оставляли для нас информацию об их простейшем быте и традициях с помощью наскальных рисунков.
С тех пор люди совершали множественные научные открытия, собирали информацию о своих предшественниках и накапливали сведения из каждодневных новостей, набирая тем самым все больше объемов информации и придавая ей такие качества, как ценность и достоверность.
Со временем количество информации стало настолько обширным и огромным, что человечество было не в состоянии самостоятельно хранить это в своей памяти, заниматься ручной ее обработкой и производить какие-либо действия над ней. Именно поэтому и возникла потребность в фундаментальной на сегодняшний день науке — информатике, в сферу изучения которой входит область человеческой деятельности, связанная с различными преобразованиями информации. Информатика охватывает практически каждую область нашей жизни: от проведения простейших математических вычислений до сложного инженерного и архитектурного проектирования, а также создания анимационных и мультипликационных фильмов. Она ставит перед собой такие основные цели, как автоматизированная обработка, структурирование, хранение и передача информации.
В сегодняшней теме мы затронем конкретно структурирование информации, а именно поговорим о модели данных. Однако перед этим следует прояснить некоторые другие моменты, непосредственно связанные с темой нашего разговора. А именно: базы данных и СУБД.
Polyglot persistence
Сказанное выше приводит к тому, что порою в рамках даже одной системы приходится для хранения данных и решения различных задач по их обработке использовать несколько различных СУБД, каждая из которых поддерживает свою модель данных. С легкой руки М. Фаулера, автора ряда известных книг и одного из соавторов Agile Manifesto, такая ситуация получила название многовариантного хранения («polyglot persistence»).
Фаулеру принадлежит и следующий пример организации хранения данных в полнофункциональном и высоконагруженном приложении в сфере электронной коммерции.
Пример этот, конечно, несколько утрированный, но некоторые соображения в пользу выбора той или иной СУБД для соответствующей цели можно найти, например, здесь.
Понятно, что быть служителем в таком зоопарке нелегко.
- Объем кода, выполняющего сохранение данных, растет пропорционально числу используемых СУБД; объем кода, синхронизирующего данные, — хорошо если не пропорционально квадрату этого числа.
- Кратно числу используемых СУБД возрастают затраты на обеспечение enterprise-характеристик (масштабируемости, отказоустойчивости, высокой доступности) каждой из используемых СУБД.
- Невозможно обеспечить enterprise-характеристики подсистемы хранения в целом — особенно транзакционность.
С точки зрения директора зоопарка все выглядит так:
- Кратное увеличение стоимости лицензий и техподдержки от производителя СУБД.
- Раздутие штата и увеличение сроков.
- Прямые финансовые потери или штрафные санкции из-за несогласованности данных.
Имеет место значительный рост совокупной стоимости владения системой (TCO). Есть ли из ситуации «многовариантного хранения» какой-то выход?
Отношения и функции
Данная система управления базой данных может предоставлять одну или несколько моделей. Оптимальная структура зависит от естественной организации данных приложения и требований приложения, которые включают скорость транзакций (скорость), надежность, ремонтопригодность, масштабируемость и стоимость. Большинство систем управления базами данных построено на одной конкретной модели данных, хотя продукты могут предлагать поддержку более чем одной модели.
Различные физические модели данных могут реализовать любую заданную логическую модель. Большинство программ баз данных предлагают пользователю некоторый уровень контроля при настройке физической реализации, поскольку сделанный выбор оказывает значительное влияние на производительность.









Модель — это не просто способ структурирования данных: она также определяет набор операций, которые могут выполняться с данными. Например, реляционная модель определяет такие операции, как выбор ( проект ) и соединение . Хотя эти операции могут быть неявными в конкретном языке запросов , они обеспечивают основу, на которой построен язык запросов.







