Немного школьной физики
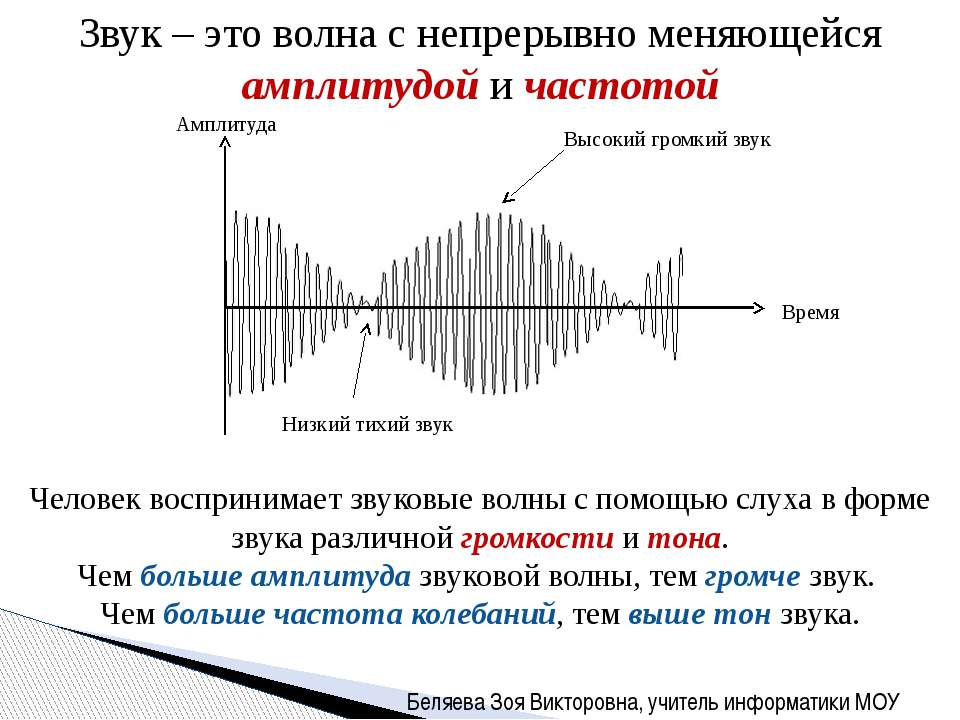
Звук — это колебания воздуха. Как волны на воде, только в воздухе. Воздух давит нам на уши, а в ушах есть чувствительные части, которые тонко чувствуют колебания воздуха. Эти колебания люди воспринимают как звук. В открытом космосе звуков нет, потому что там нет воздуха. И людей.
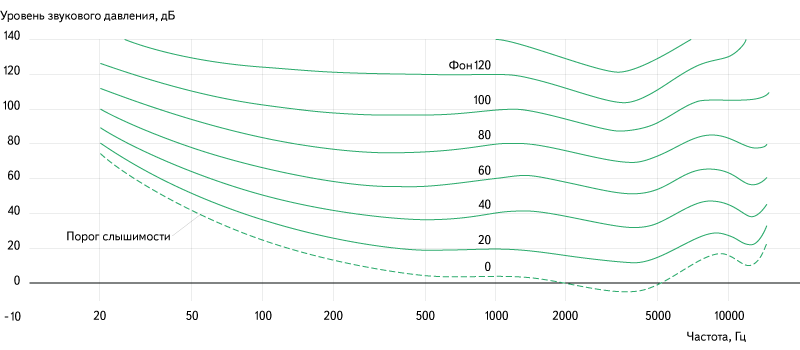
Частота. Чем быстрее колебания, тем тоньше воспринимаемый нами звук. Человек воспринимает колебания от 20 раз в секунду до примерно 20 тысяч раз в секунду. По-другому это называется частотой колебаний: герцами. То есть диапазон, который мы слышим — от 20 герц до 20 килогерц.
Для сравнения, собаки слышат от 40 герц до 60 килогерц, поэтому собачий свисток не воспринимается людьми, но очень хорошо слышен собакам. Собачий свисток как раз звучит в диапазоне 23–54 КГц.
Амплитуда. Чем сильнее колебания — тем громче, и наоборот. Можно представить, что это высота волн на поверхности пруда: может быть мелкая рябь (тихий звук), а могут быть большие мощные волны.
График. Если мы произнесём фразу «Привет, это журнал „Код“», то с точки зрения волн он будет выглядеть как-то так (очень примерно):

Изменение разрядности файла[править]
Разрядность файла определяет динамический диапазон звука. Adobe Audition поддерживает 32-битное разрешение. Вы можете повысить разрядность файла, для получения более широкого динамического диапазона, или же вы можете снизить разрядность, для уменьшения размера файла.
Некоторые наиболее часто используемые программы и медиа-плееры требуют звук 16-бит или ниже.
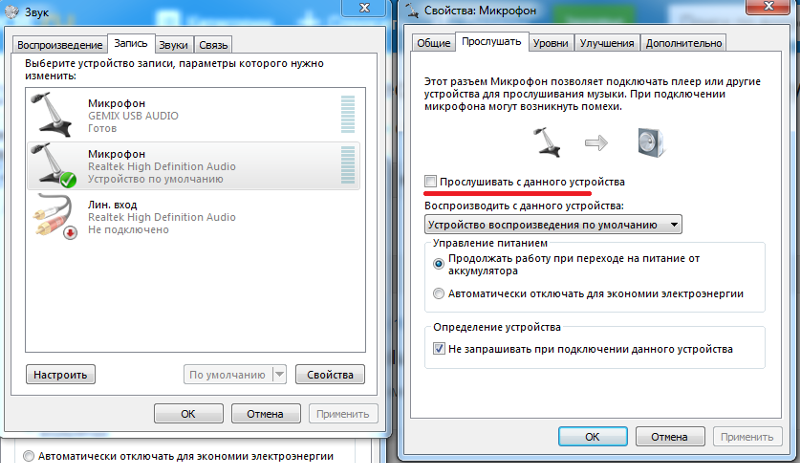
- В редакторе Waveform, выберите Edit > Convert Sample Type.
- Выберите Bit Depth (глубина разрядности) из меню или введите пользовательскую разрядность в текстовое поле.
- В разделе Advanced установите следующие параметры:
-
Dithering (дизеринг) — включает или выключает дизеринг
Дизеринг вводит небольшое количество шума, но результат является гораздо более предпочтительным, чем увеличение искажений которые вы могли бы услышать при низком уровне сигнала. Дизеринг также позволяет слышать звуки, которые будут замаскированы шумом и искаженные пределы звука при меньшей разрядности.
при переходе на более низкую разряднсть. Если дизеринг отключен, разрядность резко усекается, производя трескающий эффект на низких уровнях громкости, который вызван искажением квантования.
-
Dither Type (тип дизеринга) — управляет тем как шум дизеринга распределяется по отношению к исходному значению амплитуды. Как правило, Triangular обеспечивает лучший компромисс между соотношением сигнал-шум, искаженями и шум модуляции.
- Triangular (треугольный) — снижение отношения сигнал-шум: 4.8 dB. Нет модуляции шума.
-
Gaussian (Гауса
Triangular (Shaped) и Gaussian (Shaped) сдвигают немного больше шума на высокие частоты. Для дополнительного контроля, установите опцию Noise Shaping.
) — снижение отношения сигнал-шум: 6.0 dB. Незначительная модуляция шума.
-
Noise Shaping (формирование шума) — определяет, какие частоты содержит шум дизеринга. Вводя ограничения шума, вы можете использовать более низкие глубины, без добавления звуковых артефактов. Наилучший выбор Noise Shaping зависит от источника звука, конечной частоты дискретизации и разрядности.
- Noise Shaping отключено для частоты дискретизации 32 кГц и ниже, потому как все шумы останутся в слышимых частотах.
- High Pass (пропускающий высокие) — с кроссовером установленным на 7,3 кГц, шум дизеринга снижается до -180 дБ на 0 Гц и -162 дБ на 100 Гц.
- Light Slope (светлый склон) — с кроссовером установленным на 11 кГц, шум снижается до -3 дБ на 0 Гц и -10 дБ на 5 кГц.
-
Neutral (нейтральный):
- Light (лёгкий) — плоский до 14 кГц, шум поднимается до максимума на 17 кГц, и снова плоский на высоких частотах. Фоновый шум звучит так же как и без формирования шума, но около 11 дБ тише.
-
Heavy (тяжелый) — плоский до 15.5 кГц, устанавливая весь шум дизеринга
Выберите форму Neutral, чтобы избежать акустической окраски фонового шипения. Однако следует отметить, что шипение будет звучать громче, чем с другими формами.
выше 16 кГц (или там, где вы указываете кроссовером). Если кроссовер слишком мал, то чувствительные уши на высокой тональности услышат звон. Однако при преобразовании 48 или 96 кГц, кроссовер может быть размещён значительно выше 20 кГц.
-
-
U-Shaped (U-образный):
- Shallow (поверхностный) — в основном плоский от 2 кГц до 14 кГц, но становящийся громче, когда звук подходит к 0 Гц, поскольку низкие частоты гораздо меньше слышно.
- Medium (средний) — помещает немного больше шума на высоких выше 9 кГц, обеспечивая более низкий уровень шума ниже этой частоты.
- Deep (глубокий) — шум увеличивается выше 9 кГц ещё больше, но гораздо больше снижается в диапазоне 2-6 кГц.
-
Weighted (взвешенный):
- Light (лёгкий) — пытается сопоставить с тем как ухо воспринимает низкий уровень звука, за счёт большего снижения шума в диапазоне 2-6 кГц, и его повышения в диапазоне 10-14 кГц. При высоких уровнях, шипение может быть более заметным.
- Heavy (тяжелый) — более равномерно снижает самый чувствительный диапазон 2-6 кГц, за счет большего шума выше 8 кГц.
- Crossover (кроссовер) — определяет частоту, выше которой будет происходить формирование шума.
- Strength (интенсивность) — указывает максимальную амплитуду добавляемого шума к частоте.
- Adaptive Mode (адаптивный режим) — изменяет распределение шума по частотам.








Преобразование сигнала между сурраунд, стерео и моно[править]
Команда Convert Sample Type это самый быстрый способ для преобразования сигнала с различным количеством каналов.
- В редакторе Waveform, выберите Edit > Convert Sample Type.
- В меню Channels выберите Mono, Stereo или 5.1.
- В разделе Advanced, введите проценты для Left Mix (подмешивание в левый) и Right Mix (подмешивание в правый):
- При преобразовании из моно в стерео, Left Mix и Right Mix указывают относительную амплитуду, с которой исходный моно сигнал помещается в каждый из стерео каналов. Например, вы можете поместить моно источник только в левый или только правый канал, или в любую точку между ними.
- При преобразовании из стерео в моно, Left Mix и Right Mix управляют количеством сигнала из соответствующего канала, которые будут смешаны в конечный моно сигнал. Наиболее распространённый метод смешивания это 50% от обоих каналов.
Для других методов преобразования каналов, см. в следующие разделы:
- Сохранение и экспорт файлов
- Копирование, вырезание, вставка и удаление звука
- Эффект Channel Mixer
Делим звук на отрезки
Давайте увеличим наш график и посмотрим, что происходит, например, за одну секунду (опять же, очень примерно и упрощённо!):
 Упрощённо!
Упрощённо!
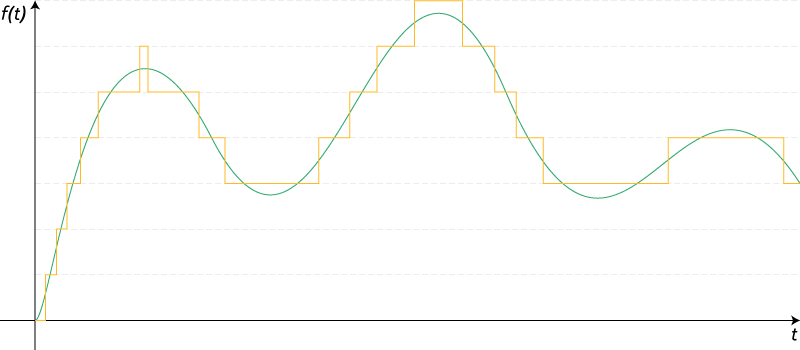
А теперь сделаем вот что: разделим секунду на 4 части, и для каждой найдём значение амплитуды:
 Мы за секунду четыре раза измерили состояние волны. Это называется дискретизацией
Мы за секунду четыре раза измерили состояние волны. Это называется дискретизацией
Мы измерили значение амплитуды в каждой из четырёх точек, получили, условно говоря, четыре числа: +30, −50, −50 и −60. Теоретически, если взять ток и подать эти четыре напряжения на динамик, у нас получится воспроизвести тот же звук. Но есть несколько проблем:
- Из-за того, что мы замерили волну только в четырёх местах, мы пропустили целое колебание. Оно было настолько быстрым, что уместилось между нашими ключевыми точками.
- Опять же, из-за больших отрезков мы получим очень грубый звук по сравнению с оригиналом. Это то же самое, как взять картину с тысячей разных оттенков и нарисовать её тремя цветами, не смешивая их.
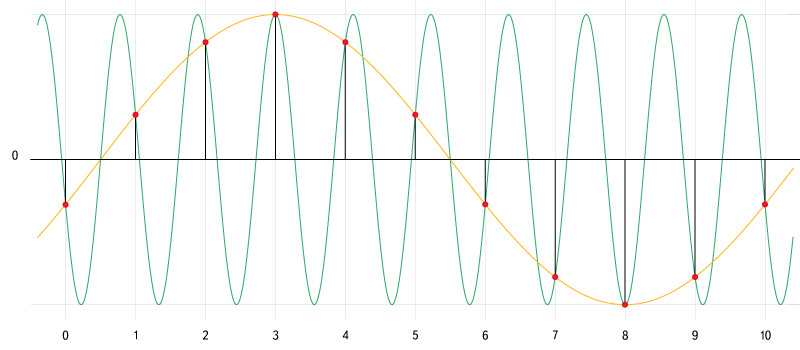
Дискретизация с частотой 4 (сколько значений мы измеряем в секунду) — это слишком мало для звука. Чтобы получить более или менее разборчивую речь, нужно секунду делить на 8 тысяч отрезков, а для музыки обычно хватает 41 тысячи.
Увеличим частоту дискретизации: нарежем звук на более мелкие кусочки за ту же единицу времени:
 Теперь измерения будут намного точнее, а получившийся звук — естественнее
Теперь измерения будут намного точнее, а получившийся звук — естественнее
Разрядность звука
Если горизонтальное дробление волны дает нам представление о частоте дискретизации, то вертикальная дискретизация – это разрядность, отвечающая за достоверную передачу динамических элементов записи. Чем большее количество «ступенек» может зафиксировать преобразователь, тем выше разрядность записанного звукового файла.



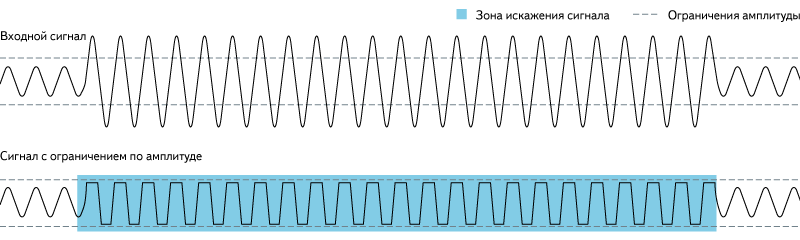



Например, волна за отрезок времени может совершить движение одной ступенькой от 0 до 16, а может четырьмя — по 4 единицы за шаг. Более точным представлением будет 16 шагов по единице. Количество ступенек, на которые волна дробится по вертикали, — это и есть разрядность.
Чем выше разрядность конвертора, тем достовернее он передаст сигналы разного уровня громкости. Если мы движемся большими шагами, каждый из которых равен 16 единицам (низкая разрядность), то при громкости входящей волны на уровне 4 график ее будет округлять до нуля. А если каждая ступенька разрядности равна 4 единицам (средняя разрядность), значение 4 будет зафиксировано на своем уровне, а значения 3 и 5 округлятся до 4. При единичном шаге все эти значения будут находиться на своих ступеньках — 3, 4, 5 (высокая разрядность).
Таким образом, более высокая разрядность АЦП дает возможность детальнее интерпретировать различные значения громкости звука и максимально приблизиться к форме реальной волны.
Разбиение волны на «ступеньки» по вертикали и горизонтали называется квантованием. Иногда частоту дискретизации называют частотой квантования, а разрядность динамическим квантованием, то есть разделением по уровням громкости (динамика).
Естественно, пример с 16 единицами — условность. Конверторы работают на гораздо более высоких значениях. Например, при разрядности 16 бит система может передать 65536 уровней громкости (2 в степени 16). А при 24 битах — 16777216 уровней (2 в степени 24).
Казалось бы, зачем столько? Неужели наше ухо способно различить хотя бы десять тысяч уровней громкости? Напрямую — не может. Скажем, два сигнала с «соседними» значениями даже при разрядности 16 бит мы различить не в состоянии. Но работа в студии ведется с разнообразными звуками, и некоторые из них имеют значительные перепады по громкости (к примеру, реверберация). Многие процессы требуют тонкой работы с громкостями (например, едва заметное воздействие эквалайзером на спектр). Для корректной работы нужна система с хорошей разрешающей способностью и по горизонтали, и по вертикали.
Но есть и обратная сторона медали. Высокие значения дискретизации и разрядности делают файлы более объемными, и для их обработки системе требуется больше ресурсов. Здесь самое время вспомнить про различия между ресурсонезависимыми и нативными системами. Чем выше квантование, тем сильнее загружается компьютер. Этот фактор более критичен для нативной системы, обремененной обслуживанием операционки и фоновых процессов.
Всегда нужно искать баланс между значениями дискретизации и разрядности и реальными возможностями системы. Не заставляйте ее работать на пределе, оставляйте резерв мощности.
Мы приближаемся к очень важной и мало кому понятной теме, связанной с музыкальным производством. Речь о так называемых шумах квантования
В ближайшее время этому явлению будет посвящен отдельный материал. Понимание природы шумов квантования дает возможность музыканту и звукорежиссеру разобраться в некоторых непростых вопросах, связанных с записью музыки в цифровой среде. Поскольку ввиду дороговизны и сложности в обслуживании аналогового оборудования подавляющее большинство музыкантов работает прежде всего именно в цифровых системах записи, эта тема так или иначе затрагивает всех.
Следите за обновлениями блога, подписывайтесь на новые статьи, чтобы совершенно бесплатно получать их на электронную почту. Также хочу напомнить, что очень много познавательной практической и теоретической информации содержится в моей книге «Академия Мюзикмейкера», которую без посредников можно приобрести на сайте MusicMaker.Pro.



Алексей ДаниловИллюстрации: А. РублевскийПри перепечатывании ссылка на источник обязательна
Интересное:
- Диалог (Мешков/Гришаев/Данилов)Не так давно я выкладывал в этом блоге запись, сделанную в жанре Progressiv…
-
Книга А. Данилова «АКАДЕМИЯ МЮЗИКМЕЙКЕРА» (предзаказ)
Ура! Книга готова и на днях отправляется в типографию. Работа по подгот…
- Компрессия звукаПонятие громкости близко и понятно не только музыканту, но и людям, не связ…
- Лучшие звуковые картыДля давних читателей моего блога эта статья может оказаться неожиданной. Од…
Как теперь воспроизвести звук
Чтобы что-то зазвучало, нужно сделать следующие шаги:
- Взять колонки или наушники — что угодно, что умеет «толкать воздух», то есть создавать акустические волны. В колонках за это отвечают динамики, к которым подключены специальные мягкие конусы, которые, собственно, и создают колебания воздуха. Та круглая ерунда в колонке — это и есть конус.
- Подать на эти колонки некий ток. От того, насколько мощный этот ток, конус будет двигаться по-разному.
- Чтобы получить этот меняющийся ток, нужен специальный чип под названием ЦАП — цифро-аналоговый преобразователь. Он получает на вход число, а на выходе дает ток. У всех ваших смартфонов и компьютеров есть такие ЦАПы.
Итого:
- Процессор отправляет цифры из звукового файла в ЦАП.
- ЦАП получает числа и выдаёт меняющееся электричество по этим цифрам.
- Электричество попадает в колонку, передаётся на динамик.
- Динамик из-за электричества начинает двигать конус колонки.
- Конус начинает толкать воздух перед собой, создавая звуковые волны.
- Волны долетают до наших ушей, и мы воспринимаем их как звук.
Что такое битность записи, динамический диапазон и на что они влияют
Если вы послушаете старые mp3 файлы или плохие MIDI записи вы заметите, что вам сложно различать музыкальные инструменты, если они играют одновременно, они просто сливаются в «звуковую кашу» и разобрать в ней ничего невозможно.
Это происходит от того, что у записи узкий динамический диапазон. Чем он больше, тем более глубоким слышится звук, более приятным и реалистичным. Узкий динамический диапазон просто не позволяет разным инструментам, которые звучат одновременно, иметь различную громкость и один инструмент глушит другой, от этого возникает мутный неприятный звук и слушать такую музыку совершенно не хочется.
Теоретически за динамический диапазон отвечает битность звука во время его кодирования в цифровой вид. Чем выше битность, тем больше значений может принимать звуковая волна за единицу времени и тем шире может быть динамический диапазон. Но это в теории, т.к. это кроме битности на громкость могут влиять много других факторов и битность начинает влиять на динамический диапазон тогда, когда все другие факторы исключены.
Например, почти вся современная музыка выпускается со значительной компрессией, чтобы увеличить базовую громкость всего материала, от этого сильно страдает динамический диапазон, т.к. все тихие места композиции подтягиваются и становятся более громкими, а очень громкие пики инструментов срезаются до среднего значения
Таким образом, после процедуры компрессии уже почти не важно какой была битность записи. Но в том случае если вы слушаете качественный материал, который не испортили на студии, битность действительно начинает играть значительную роль в динамическом диапазоне
Самое распространённое значение сегодня это 16 битная запись, но уже набирает популярность 24 битная музыка, а в скором времени в общее пользование начнут попадать 32 битные записи музыкальных произведений. При качественной обработки музыкального материала на студии и без ужасающей компрессии 16 битная точность записи, в общем, достаточна для того, чтобы не испытывать проблем с динамическим диапазоном.
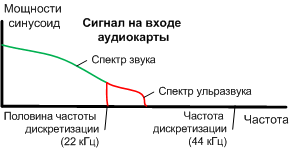






Но в определении качества звука мы снова сталкиваемся с особенностями человеческого восприятия звука. Что такое 16 битная запись звука? Это значит, что одно измерение изменения амплитуды звуковой волны может принимать 65536 значений, что даёт нам динамический диапазон до 96,33 Дб. В свою очередь это означает, что звук с громкостью до 96,33 Дб должен быть записан без искажений по уровню громкости.
Если вы похожи на меня, то в большинстве случаев вы слушаете музыку в наушниках, а в наушниках довольно опасно долго слушать громкую музыку и, поверьте, 96,33 Дб это очень громко. Я стараюсь не превышать 60-65 Дб при прослушивании, этого вполне достаточно чтобы в полной мере насладиться звуком, но недостаточно чтобы повредить слух. И, как видите, у меня остается значительный запас по громкости до заветных 96,33 дб. По этой причине записи с 24 битной точностью для меня не дадут никакого преимущества, я просто не буду слышать разницы из-за того, что не слушаю музыку достаточно громко. Если кто-то из ваших знакомых, слушающий музыку в наушниках, говорит вам, что есть разница между 16 битной записью и 24 битной — не верьте ему. Он стал жертвой маркетинга и просто верит, что разница есть, хоть он её и не слышит. Добавим к этому тот факт, что наш слух имеет разную чувствительность по громкости к разным частотам звука, поэтому 16 битных записей для прослушивания в наушниках хватит для любых ситуаций.
Так почему многие люди верят, что 24 битная запись музыки значительно превосходит 16 битную? Для некоторых ситуаций это действительно так. Например, если вы слушаете живую запись симфонического оркестра, вам действительно нужна 24 битная запись, т.к. вам придется значительно повышать громкость, чтобы услышать все нюансы. Вы повышаете громкость технически, на вашем устройстве, но та громкость, которую вы услышите будет нормальной, потому что записи симфонической музыки делаются довольно тихими как раз для того, чтобы можно было расслышать все нюансы звука. Но это правило не работает для современных записей поп музыки, т.к. уже на студии записи делают предельно громкими и если вы будете слушать её на той же громкости, что и качественную запись оркестра, вы просто рискуете повредить свой слух.
Также 24 битная запись подходит для записи звука. Гораздо эффективнее сделать запись в более высокой битности и потом, при финальной обработке снизить её до 16, чем наоборот. Если вы сделаете запись в 16 битах и потом искусственно увеличите её до 24, то качество будет даже ниже, чем при исходных 16 битах, а возможно и такое, что в звуке появится посторонний фоновый шум.
Полный цикл преобразования звука: от оцифровки до воспроизведения у потребителя

Полный цикл преобразования звука: от оцифровки до воспроизведения
Помехоустойчивое и канальное кодирование
Помехоустойчивое кодирование позволяет при воспроизведении сигнала выявить и устранить (или снизить частоту их появления) ошибки чтения с носителя. Для этого при записи к сигналу, полученному на выходе АЦП, добавляется искусственная избыточность (контрольный бит), которая впоследствии помогает восстановить поврежденный отсчет. В устройствах записи звука обычно используется комбинация из двух или трех помехоустойчивых кодов. Для лучшей защиты от пакетных ошибок также применяется перемежение.
Канальное кодирование служит для согласования цифровых сигналов с параметрами канала передачи (записи/воспроизведения). К полезному сигналу добавляются вспомогательные данные, которые облегчают последующее декодирование. Это могут быть сигналы временного кода, служебные сигналы, сигналы синхронизации.
В устройствах воспроизведения цифровых сигналов канальный декодер выделяет из общего потока данных тактовые сигналы и преобразует поступивший канальный сигнал в цифровой поток данных. После коррекции ошибок сигнал поступает в ЦАП.
Принцип действия ЦАП
Цифровой сигнал, полученный с декодера, преобразовывается в аналоговый. Это преобразование происходит следующим образом:
- Декодер ЦАП преобразует последовательность чисел в дискретный квантованный сигнал
- Путём сглаживания во временной области из дискретных отсчетов вырабатывается непрерывный во времени сигнал
- Окончательное восстановление сигнала производится путём подавления побочных спектров в аналоговом фильтре нижних частот
Параметры, влияющие на качество звука при его прохождении по полному циклу
Основными параметрами, влияющими на качество звука при этом являются:
- Разрядность АЦП и ЦАП.
- Частота дискретизации АЦП и ЦАП.
- Джиттер АЦП и ЦАП
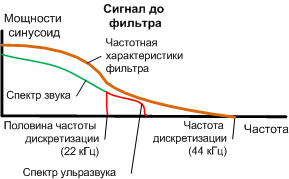
- Передискретизация
Также немаловажными остаются параметры аналогового тракта цифровых устройств кодирования и декодирования:
- Отношение сигнал/шум
- Коэффициент нелинейных искажений
- Интермодуляционные искажения
- Неравномерность амплитудно-частотной характеристики
- Взаимопроникновение каналов
- Динамический диапазон
Устройства синхронизации

Когда 2 или более устройств обмениваются цифровыми данными в реальном времени…
Их внутренние часы должны быть синхронизированы, чтобы сэмплы оставались выровненными…
И не появлялись раздражающие щелчки и хлопки.
Для их синхронизации одно устройство служит “главным”, а остальные — “ведомыми”.
В простых домашних студиях главными обычно являются часы аудиоинтерфейса.
В профессиональных студиях, которым необходимы идеальная цифровая конвертация и сложный путь прохождения сигнала…
Вместо этого используется специальное отдельное устройство, известное как цифровое устройство синхронизации (также известное как word clock). По словам многих пользователей, при использовании таких устройств звук улучшается гораздо сильнее, чем можно было бы подумать.





Далее…







