Мотивация и история
Laclusion pratique à laquelle je suis arrivé dès maintenant, c’est que chaque fois que en vertu de mes critères, une varété de modules (ou plutôt, un schema de modules) для классификации вариантов (глобальных, или бесконечных) определенных структуры (различные совокупности, не являющиеся сингулярными, векторные волокна и т. д.) ne peut exister, malgré de bonnes, hypothèses de platitude, propreté, et non singularité éventuellement, la raison en est seulement l’existence d’automorphismes de la structure qui empêche la method descente de marcher.
Письмо Гротендика Серру, 5 ноября 1959 г.
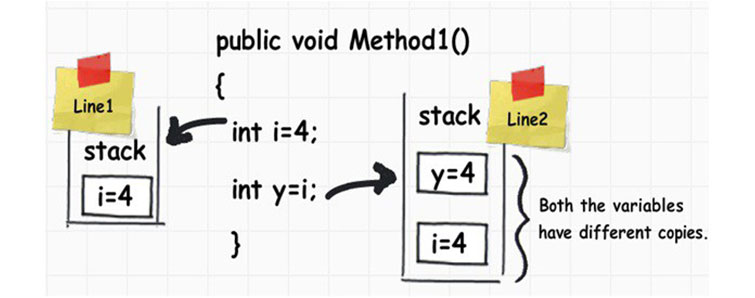
Концепция стеков берет свое начало в определении данных эффективного спуска в . В письме Серру в 1959 г. Гротендик заметил, что фундаментальным препятствием для построения хороших пространств модулей является существование автоморфизмов. Основная мотивация для стеков состоит в том, что если пространство модулей для некоторой проблемы не существует из-за существования автоморфизмов, все еще может быть возможно построить стек модулей.
изучал группу Пикара стека модулей эллиптических кривых до того, как стеки были определены. Стеки были впервые определены Жиро ( , ), а термин «стек» был введен для оригинального французского термина «чемпион», означающего «поле». В этой статье они также представили стеки Делиня – Мамфорда , которые они назвали алгебраическими стеками, хотя термин «алгебраический стек» теперь обычно относится к более общим стекам Артина, введенным Артином ( ).
При определении частных схем по групповым действиям часто бывает невозможно, чтобы частное было схемой и по-прежнему удовлетворяло желаемым свойствам для частного. Например, если несколько точек имеют нетривиальные стабилизаторы, то категориального фактора не будет среди схем.
Точно так же пространства модулей кривых, векторных расслоений или других геометрических объектов часто лучше всего определять как стеки, а не схемы. При построении пространств модулей часто сначала строят более крупное пространство, параметризуя рассматриваемые объекты, а затем вычисляя факторное действие по групповому действию, чтобы учесть объекты с автоморфизмами, которые были пересчитаны.
Программный стек
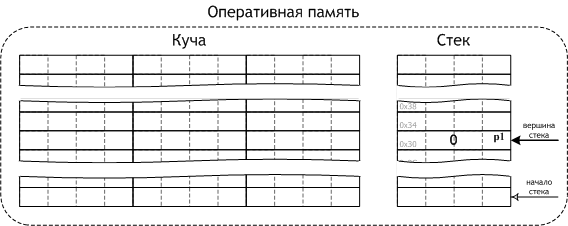
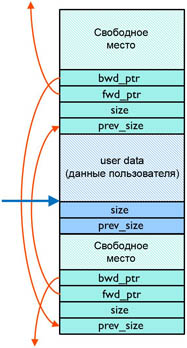
Организация в памяти
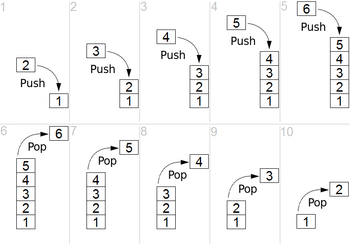
Организация стека в виде одномерного упорядоченного по адресам массива. Показаны операции вталкивания и выталкивания данных из стека операциями push и pop.
Зачастую стек реализуется в виде однонаправленного списка (каждый элемент в списке содержит помимо хранимой информации в стеке указатель на следующий элемент стека).
Но также часто стек располагается в одномерном массиве с упорядоченными адресами. Такая организация стека удобна, если элемент информации занимает в памяти фиксированное количество слов, например, 1 слово. При этом отпадает необходимость хранения в элементе стека явного указателя на следующий элемент стека, что экономит память. При этом указатель стека (Stack Pointer, — SP) обычно является регистром процессора и указывает на адрес головы стека.
Предположим для примера, что голова стека расположена по меньшему адресу, следующие элементы располагаются по нарастающим адресам. При каждом вталкивании слова в стек, SP сначала уменьшается на 1 и затем по адресу из SP производится запись в память. При каждом извлечении слова из стека (выталкивании) сначала производится чтение по текущему адресу из SP и последующее увеличение содержимого SP на 1.
При организации стека в виде однонаправленного списка значением переменной стека является указатель на его вершину — адрес вершины. Если стек пуст, то значение указателя равно NULL.
Пример реализации стека на языке С:
struct stack
{
char *data;
struct stack *next;
};
Операции со стеком
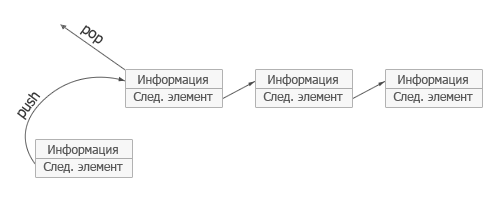
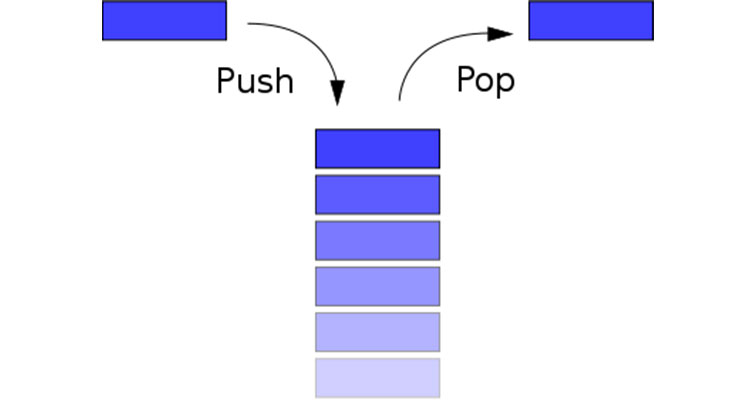
Возможны три операции со стеком: добавление элемента (иначе проталкивание, push), удаление элемента (pop) и чтение головного элемента (peek).
При проталкивании (push) добавляется новый элемент, указывающий на элемент, бывший до этого головой. Новый элемент теперь становится головным.
При удалении элемента (pop) убирается первый, а головным становится тот, на который был указатель у этого объекта (следующий элемент). При этом значение убранного элемента возвращается.
void push( STACK *ps, int x ) // Добавление в стек нового элемента
{
if ( ps->size == STACKSIZE ) // Не переполнен ли стек?
{
fputs( "Error: stack overflow\n", stderr );
abort();
}
else
{
ps->itemsps->size++ = x;
}
}
int pop( STACK *ps ) // Удаление из стека
{
if ( ps->size == ) // Не опустел ли стек?
{
fputs( "Error: stack underflow\n", stderr );
abort();
}
else
{
return ps->items--ps->size];
}
}
Область применения
Программный вид стека используется для обхода структур данных, например, дерево или граф. При использовании рекурсивных функций также будет применяться стек, но аппаратный его вид. Кроме этих назначений, стек используется для организации стековой машины, реализующей вычисления в обратной инверсной записи.
Для отслеживания точек возврата из подпрограмм используется стек вызовов.
Арифметические сопроцессоры, программируемые микрокалькуляторы и язык Forth используют стековую модель вычислений.
Идея стека используется в стековой машине среди стековых языков программирования.
Применение стека упрощает и ускоряет работу программы, так как идет обращение к нескольким данным по одному адресу.
Типы стеков
Стек в покере имеет несколько типов. Каждый из них основан прежде всего на количестве фишек, которые имеются у игрока. Соответственно для каждого из типов стеков в покере существует своя стратегия игры. На какие же типы делятся покер стеки?

Глубокий стек
Это стек, который насчитывает 200 или более Больших блайндов. Покер за столом, где у игроков глубокие стеки отличается некоей свободой. Она отражается в частом вхождении в игру, широким диапазоном стартовых рук. Это хорошо заметно в покерных телевизионных шоу, которые были в свое время очень популярны. В них играли покер-про именно с глубокими стеками. Большое количество фишек дает возможность пытаться разыгрывать даже слабые руки. От этого игра зачастую принимала интересный оборот, а раздачи не всегда завершались в пользу обладателей даже карманных топ-пар.






Полный стек
Этот тип стека содержит, как правило, 100 ББ. Понятно, что по ходу игры эта сумма фишек может быть увеличена и доходить до 140-150 ББ. В этом случае это будет уже увеличенный стек. Если же говорить об обратном — 80-90 ББ, то такой стек называется укороченным.
Большинство покерных стратегий рассчитаны как раз на полный стек, с ним играть комфортно. Поэтому, если покерист несколько потерял от своего полного стека, то при первой же возможности ему стоит докупиться.
Неполный
Спектр такого типа — 30-70 ББ. Играть с таким количеством фишек непросто, прежде всего потому что нет возможности в полной мере применять базовые стратегии и тактики, рассчитанные на полный стек.
Следует докупаться, тем более, что игрок, играющий долгое время с неполным стеком, выдает в себе непрофессионала.
Короткий стек
Этот тип отличается наличием у игрока фишек в районе 25 ББ. В покере, а именно в Техасском Холдеме есть специальные стратегии игры с коротким стеком. Эти тактики отличаются агрессивным вхождением в раздачу. Однако и здесь есть свои нюансы: многое зависит от позиции, силы карманки и так далее.
Ультракороткий стек
Это 10 ББ или менее. Самая оптимальная игра — выставление в олл-ин уже на префлопе. Во многом такая манера может напоминать игру по принципу «пан или пропал», но в определенных случаях она оправдана. Во всяком случае сторонником такой стратегии выступает один из лучших покерных аналитиков Дэвид Склански и математик Висконсинского университета Андрей Чубуков.
Стек на массиве:
class ArrayStack(object): def __init__(self, iterable=None): """Инициализация стека и добавление в него элементов, если они есть.""" self.list = list() # Инициализация списка (встроенного в Python динамического массива) для хранения элементов if iterable is not None: for item in iterable: self.push(item) def push(self, item): """"Добавление элементов на вершину стека Сложность: O(1), пока мы не заполним всю выделенную память, затем O(n)""" self.list.append(item) def peek(self): """Возвращает верхний элемент стека, не удаляя его, или None, если стек пустой.""" last_item_idx = len(self.list) - 1 return None if last_item_idx < 0 else self.list def pop(self): """Удаляет и возвращает верхний элемент, если он есть, иначе выдаёт ValueError Сложность: O(1), так как нужно удалить лишь последний элемент""" if self.peek() == None: raise ValueError("list is empty") else: return self.list.pop()
Что лучше?
В коде я указал сложность каждой из операций, используя “О” большое. Как видите, имплементации мало чем отличаются.
Однако есть некоторые нюансы, которые стоит учесть.
Стек и стратегия кэш-игры
То количество денег, которое игрок берет с собой за кэш-стол, должно опираться прежде всего на планы по его стратегии на игру. Если у покериста от 20 до 40 ББ, то он вынужден играть по стратегии короткого стека. То есть его активность предполагает агрессивную игру на префлопе, так как на улицах постфлопа, имея малое количество средств, он уже не того маневра, который предполагает игра с полным стеком.
Поэтому бывалые игроки берут с собой за стол полный или даже глубокий стек. 100 ББ и больше помогут грамотно и квалифицированно проводить в игре тактические приемы, которые в конечном итоге оборачиваются прибылью.
Можно прийти к мнению, что игра с полным и глубоким стеком может привести к скорой потере части банкролла. Ведь, если кто-либо из оппонентов за столом выставиться и игрок с полным стеком ответит на олл-ин и проиграет ва-банк, его банкролл заметно просядет. Такое суждение справедливо, но только с точки зрения новичка в покере, для которого потеря стека в 100 ББ и больше видится катастрофой. Мы же говорим об опытных покеристах, которые придерживаются стратегии долгосрочной перспективы. Даже пара проигрышей полного стека в долгосрочной перспективе с высокой вероятностью окупится и в ровно такой же ситуации с олл-ином.

Поэтому важно докупать фишки между раздачами до полного стека. Этим игрок развязывает себе руки для осуществления покерных приемов и проведения собственной тактики
Если на каком-то этапе у вас стек снизился до уровня в 40 ББ, то лучше докупиться до полного. Тем более, что в онлайн покер-румах всегда есть функция автоматической докупки. Старайтесь играть правильно с первых дней. Пусть вы будете играть на низких бай-инах, но с полным стеком, чем на высоких с коротким. Поверьте, во втором случае банкролл будет таять намного быстрее, а опыта игры и навыков хорошего покериста вы не приобретете.
Но в некоторых ситуациях фишки необходимо сбрасывать. Это обязательно необходимо делать, если количество фишек в вашем стеке значительно превышает первоначальный показатель. Предположим, в игру на $0,1/$0,2 вы взяли с собой в качестве стека фишек на $20. То есть у вас полный стек. На каком-то этапе у вас скопилось $100.
В этой ситуации стоит быть осмотрительнее. Если у всех остальных игроков за столом стек по-прежнему в районе $20, можно продолжать играть. Если же у кого-либо из оппонентов стек также перешел из разряда полного в глубокий и более, то рекомендуем вам прерваться на время и скинуть излишек фишек, доведя стек до первоначального размера в $20.
Объясняется это довольно просто. Судите сами, если в ответ на агрессивный олл-ин оппонента со стеком в $120 вы ответите и проиграете свою сотню, то вы не сможете за один раз докупить проигранные фишки на $100. В игре стоит ограничение по докупке – $20. Следовательно, вы не сможете в полной мере реализовать математические ожидания от ситуации. Другими словами, впоследствии ваши $20 против его уже $220 на лимите $0,1/$0,2 так или иначе превратятся в пыль. К проигранным $100 добавятся еще $20.
А если вы вовремя сбросите выигранные $80, и останетесь в раздаче с $20, то, во-первых, сохраните выигрыш, к которому всегда можно будет вернуться, во-вторых, вернетесь в раздачу с полным стеком, который предоставляет вам все возможности реализовывать задуманные тактики. То есть не спешите переходить из разряда лидера в разряд догоняющего.
Технологии, которые потеряли былую привлекательность
Adobe Photoshop и Illustrator. Это — два замечательных приложения, которые многие годы удовлетворяли все мои потребности в работе с графикой. Я с грустью говорю им «прощайте» и благодарю их за то, что они были со мной. Теперь всё, что мне нужно, дают их бесплатные опенсорсные заменители.
jQuery. Эта библиотека стала ненужной тогда, когда закончились войны кросс-браузерной совместимости. Единственной ценнейшей для меня возможностью jQuery был синтаксис селекторов. Он оказался настолько востребованным, что в 2009 году был добавлен в DOM в виде .
AJAX. Этот прародитель Web 2.0. теперь превратился в пережиток прошлого. API заменяется современным и более простым API , а JSON приходит на замену XML.
SASS/SCSS. Я признаю то, что написание CSS-кода без переменных было неэффективным, в результате SASS многим пришёлся по душе
И модули тоже были весьма важной возможностью. Но в итоге для того, чтобы всё это использовать в JavaScript, нужно было потратить слишком много времени и сил
При этом, наряду с развитием вспомогательных инструментов для работы со стилями, стандарт CSS тоже не стоял на месте. В результате различные средства для преобразования CSS-кода постепенно уходят в прошлое.
БЭМ. Схема именования сущностей БЭМ (Блок, Элемент, Модификатор), используемая при формировании имён CSS-классов, решает проблему глобального пространства имён. Но за это приходится платить использованием очень длинных конструкций. Я перешёл к родительским/дочерним селекторам в семантических элементах, предпочтя более лёгкий подход идентификаторам и именам классов.
Например:
Шрифты Georgia и Verdana. Эти два шрифта многие годы занимали верхнюю позицию моего рейтинга шрифтов. Я мог положиться на их доступность и на их читабельность. Но после того, как появилось правило , и после того, как начали распространяться опенсорсные шрифты, я стал пользоваться подобными шрифтами.
Babel, Grunt, Gulp, Browserify, WebPack. Первые четыре пункта в этом списке вряд ли кого удивят. Но почему мой стек веб-технологий покинул Webpack? У того, что этот бандлер потерял для меня актуальность, есть некоторые причины, на которых я остановлюсь подробнее:До появления HTTP/2 с поддержкой постоянных соединений и мультиплексирования потоков мы находились в зависимости от возможностей этих инструментов по сборке бандлов ресурсов приложений. Но бандлинг ничего нам не даёт в мире, где есть HTTP/2.
Стандарт ECMAScript 2015 был новым словом в JavaScript-разработке, все бросились использовать новые возможности языка в тот самый момент, когда они увидели свет. Однако тут была одна проблема. Код, написанный с использованием новых возможностей, не поддерживался браузерами. Поэтому его приходилось транспилировать в ECMAScript 5-код. В этом деле мы полагались на Babel, его применение стало стандартным шагом подготовки веб-проектов к публикации. Сегодня же все необходимые мне новые возможности языка доступны буквально повсюду. В результате Babel мне больше не нужен.
До появления в браузерах возможности динамического импорта модулей код приходилось транспилировать в формат CommonJS. Теперь же большинство основных браузеров поддерживает (да и Edge 76+ скоро подтянется). В результате скоро мы сможем поздороваться с ECMAScript-модулями и попрощаться со всем остальным.
JSX. Я не понимаю тех, кто полагает, что JSX — это хорошо. И «Но вы же к этому привыкли» для меня — не аргумент.
Функциональное программирование. Я ограничил применение функционального программирования в своём коде до простых однострочных конструкций вроде . Для всего остального я использую объектно-ориентированное программирование.







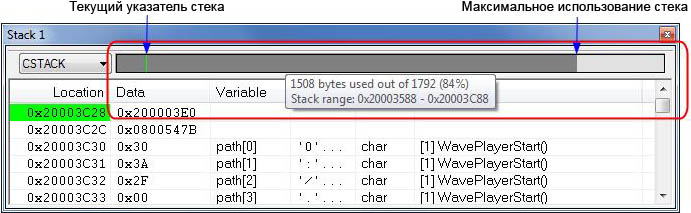
Работа со стеком
При формировании стека нужно понять, скольким блайндам (минимальным ставкам) он будет равняться. Определяется это число по формуле: размер стека в покере делится на размер большого блайнда. Пример: если у вас $50 на руках, а размер блайнда – $1, значит у вас 50 минимальных ставок.
За обычным игровым столом блайнды не поднимаются, остаются всегда одного размера. За турнирным столом минимальные ставки растут через определенный промежуток времени. Если не увеличивать свой стек в покере, количество блайндов в нем будет постепенно уменьшаться даже без особых проигрышей.
Перед началом игры, нужно определиться, с каким стеком заходить за стол
Важно, чтобы у вас и у соперников было приблизительно одинаковое количество фишек. Если у вас за столом $20, а у оппонентов по $40, тогда при игре ва-банк вы не сможете получить максимальную сумму
Массивы, коллекции, списки, очереди … Стек!
Часто люди задают вопрос: «Стек — что это такое?». «Программирование» и «систематизация» — интересные понятия: они не синонимы, но так тесно связаны. Программирование прошло очень быстро такой длительный путь, что достигнутые вершины кажутся идеальными. Скорее всего, это не так. Но очевидно другое.
Идея стека стала привычной не только на уровне различных языков программирования, но и на уровне их конструкций и возможностей по созданию типов данных. Любой массив имеет push и pop, а понятия «первый и последний элементы массива» стали традиционными. Раньше были просто элементы массива, а сегодня есть:
- элементы массива;
- первый элемент массива;
- последний элемент массива.
Операция помещения элемента в массив сдвигает указатель, а извлечение элемента с начала массива или с его конца имеет значение. По сути это тот же стек, но в применении к другим типам данных.

Особенно примечательно, что популярные языки программирования не имеют конструкции stack. Но они предоставляют его идею разработчику в полном объеме.
Стек: что это такое и применение на News4Auto.ru.
Наша жизнь состоит из будничных мелочей, которые так или иначе влияют на наше самочувствие, настроение и продуктивность. Не выспался — болит голова; выпил кофе, чтобы поправить ситуацию и взбодриться — стал раздражительным. Предусмотреть всё очень хочется, но никак не получается. Да ещё и вокруг все, как заведённые, дают советы: глютен в хлебе — не подходи, убьёт; шоколадка в кармане — прямой путь к выпадению зубов. Мы собираем самые популярные вопросов о здоровье, питании, заболеваниях и даем на них ответы, которые позволят чуть лучше понимать, что полезно для здоровья.
Какой способ создания стека использовать
Сегодня мы изучили два способа реализации стека:
- С помощью шаблона C++.
- При помощи массива.
Если вы используете стек в вашей программе и вам лучше чтобы она работа как можно быстрее, то используйте первый способ реализации стека.
Если же вам все равно на быстродействие программы, то можете использовать создание стека через массив. Лично мы всегда используем первый способ реализации стека. Он быстр и прост для использования и объявления.
В следующем уроке мы изучим еще одну очень важную структуру данных — очередь. Эту структуру данных используют во многих мессенджерах (например, telegram).
Стек вызовов на практике
Давайте рассмотрим детально, как работает стек вызовов. Ниже приведена последовательность шагов, выполняемых при вызове функции:
Программа сталкивается с вызовом функции.
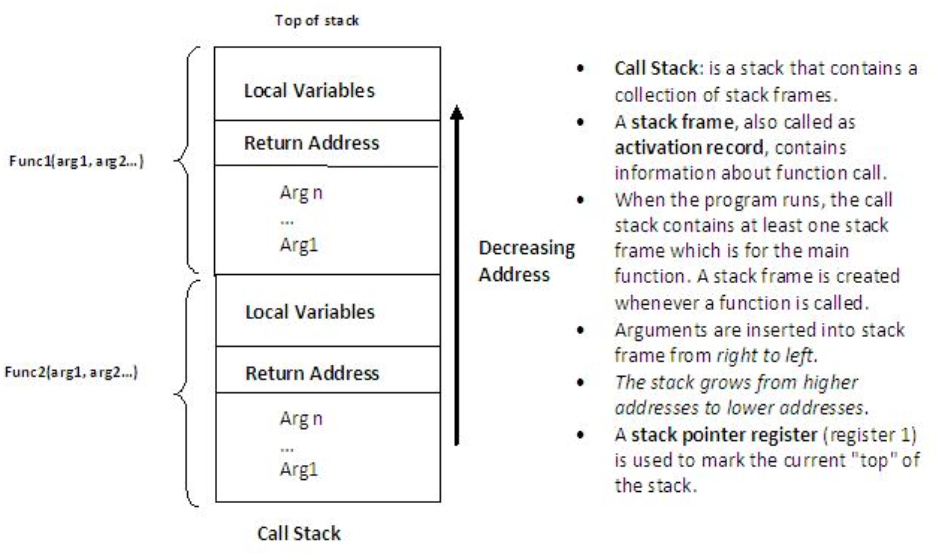
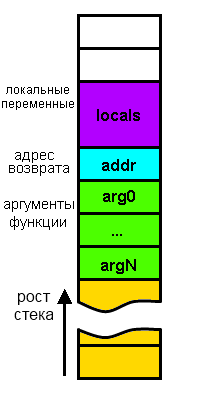
Создается фрейм стека, который помещается в стек. Он состоит из:
адреса инструкции, который находится за вызовом функции (так называемый «обратный адрес»). Так процессор запоминает, куда ему возвращаться после выполнения функции;
аргументов функции;
памяти для локальных переменных;
сохраненных копий всех регистров, модифицированных функцией, которые необходимо будет восстановить после того, как функция завершит свое выполнение.
Процессор переходит к точке начала выполнения функции.
Инструкции внутри функции начинают выполняться.
После завершения функции, выполняются следующие шаги:
Регистры восстанавливаются из стека вызовов.
Фрейм стека вытягивается из стека. Освобождается память, которая была выделена для всех локальных переменных и аргументов.





Обрабатывается возвращаемое значение.
ЦП возобновляет выполнение кода (исходя из обратного адреса).
Возвращаемые значения могут обрабатываться разными способами, в зависимости от архитектуры компьютера. Некоторые архитектуры считают возвращаемое значение частью фрейма стека, другие используют регистры процессора.
Знать все детали работы стека вызовов не так уж и важно. Однако понимание того, что функции при вызове добавляются в стек, а при завершении выполнения — удаляются из стека, дает основы, необходимые для понимания рекурсии, а также некоторых других концепций, которые полезны при отладке программ
Ссылки
Ссылки
- Жиро, Жан (1966), Cohomologie non abélienne de degré 2 , диссертация, Париж
- Жиро, Жан (1971), Cohomologie non abélienne , Springer , ISBN 3-540-05307-7
- Лаумон, Жерар; Морет-Байи, Лоран (2000), Champs algébriques , Ergebnisse der Mathematik и ихрер Grenzgebiete. 3. Фольге. Серия современных исследований по математике, 39 , Берлин, Нью-Йорк: Springer-Verlag , ISBN 978-3-540-65761-3, MR К сожалению, в этой книге используется неверное утверждение, что морфизмы алгебраических стеков индуцируют морфизмы lisse-étale topoi. Некоторые из этих ошибок были исправлены .ошибка harvtxt: несколько целей (2 ×): CITEREFOlsson2007 ( справка )
- Олссон, Мартин (2016), Алгебраические пространства и стеки , Публикации коллоквиума, 62 , Американское математическое общество, ISBN 978-1470427986
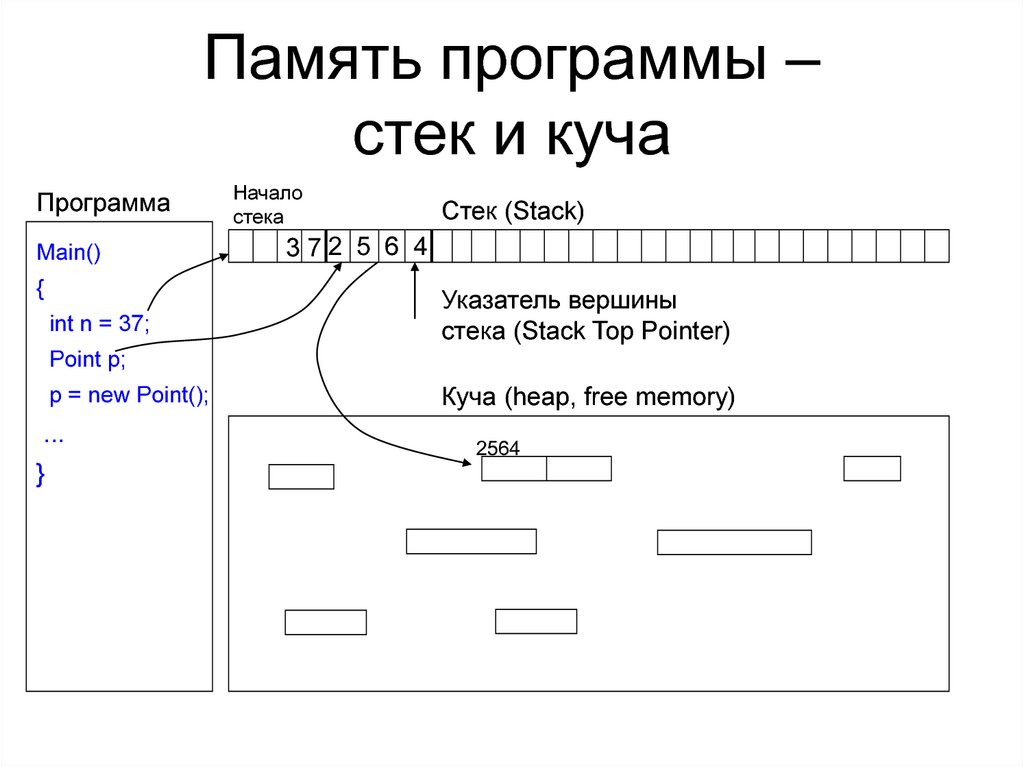
На заре начала: процессор, память и стек
Идеальная память обеспечивает адресацию прямо к значению — это уровни машины и языка высокой степени. В первом случае процессор последовательно перебирает адреса памяти и выполняет команды. Во втором случае программист манипулирует массивами. В обоих эпизодах есть:
- адрес = значение;
- индекс = значение.
Адрес может быть абсолютным и относительным, индекс может быть цифровым и ассоциативным. По адресу и индексу может находиться другой адрес, а не значение, но это детали косвенной адресации. Без памяти процессор работать не может, а без стека команд и данных — он, как лодка без весел.
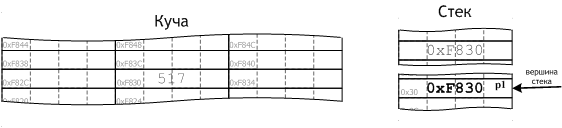
Стопка тарелок — традиционная новелла о сути стека: понятие stack и перевод в общебытовом сознании. Нельзя взять тарелку снизу, можно брать только сверху, и тогда все тарелки будут целы.

Все, что последним приходит в стек, уходит первым. Идеальное решение. По сути, stack, как перевод одного действия в другое, трансформирует представления об алгоритме как последовательности операций.
RemarksRemarks
Элементы класса, оговоренные в первом параметре шаблона объекта Stack, являются синонимами и должны соответствовать типу элемента в базовом классе контейнера, указанном вторым параметром-шаблоном.The elements of class stipulated in the first template parameter of a stack object are synonymous with and must match the type of element in the underlying container class stipulated by the second template parameter. Объект должен быть назначаемым, чтобы можно было скопировать объекты этого типа и присвоить значения переменным этого типа.The must be assignable, so that it is possible to copy objects of that type and to assign values to variables of that type.
Подходящие базовые классы контейнеров для Stack включают deque, класс Listи класс Vector, а также любой другой контейнер последовательности, который поддерживает операции , и .Suitable underlying container classes for stack include deque, list class, and vector class, or any other sequence container that supports the operations of , , and . Класс базового контейнера инкапсулирован в адаптер контейнера, который предоставляет только ограниченный набор функций-членов контейнера последовательностей в виде открытого интерфейса.The underlying container class is encapsulated within the container adaptor, which exposes only the limited set of the sequence container member functions as a public interface.
Объекты стека сравнимы по равенству только в том случае, если элементы класса сравнимы по равенству и меньше, чем сравнимы, только если элементы класса менее сравнимы.The stack objects are equality comparable if and only if the elements of class are equality comparable and are less-than comparable if and only if the elements of class are less-than comparable.
-
Класс стека поддерживает структуру данных «последним поступил — первым обслужен» (LIFO).The stack class supports a last-in, first-out (LIFO) data structure. Хороший аналог такого подхода — стопка тарелок.A good analogue to keep in mind would be a stack of plates. Элементы (тарелки) можно вставлять, проверять или удалять только из верхней части стека, которая является последним элементом в конце базового контейнера.Elements (plates) may be inserted, inspected, or removed only from the top of the stack, which is the last element at the end of the base container. Ограничение на доступ только к верхнему элементу является причиной использования класса стека.The restriction to accessing only the top element is the reason for using the stack class.
-
Класс queue поддерживает структуру данных «первым поступил — первым обслужен» (FIFO).The queue class supports a first-in, first-out (FIFO) data structure. Хороший аналог такого подхода — очередь из людей к банковскому служащему.A good analogue to keep in mind would be people lining up for a bank teller. Элементы (люди) можно добавлять в конец очереди и удалять из начала очереди.Elements (people) may be added to the back of the line and are removed from the front of the line. Проверять можно как начало, так и конец очереди.Both the front and the back of a line may be inspected. Ограничение на доступ только к переднему и заднему элементам в таком подходе является причиной использования класса очереди.The restriction to accessing only the front and back elements in this way is the reason fur using the queue class.
-
Класс priority_queue упорядочивает элементы, чтобы наибольший элемент всегда находился сверху.The priority_queue class orders its elements so that the largest element is always at the top position. Он поддерживает вставку элемента, а также проверку и удаление верхнего элемента.It supports insertion of an element and the inspection and removal of the top element. Хороший аналог такого подхода — очередь из людей, упорядоченная по возрасту, росту или любому другому критерию.A good analogue to keep in mind would be people lining up where they are arranged by age, height, or some other criterion.
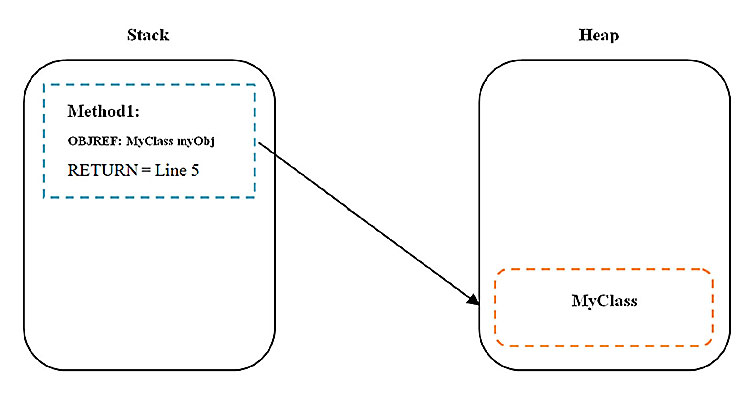
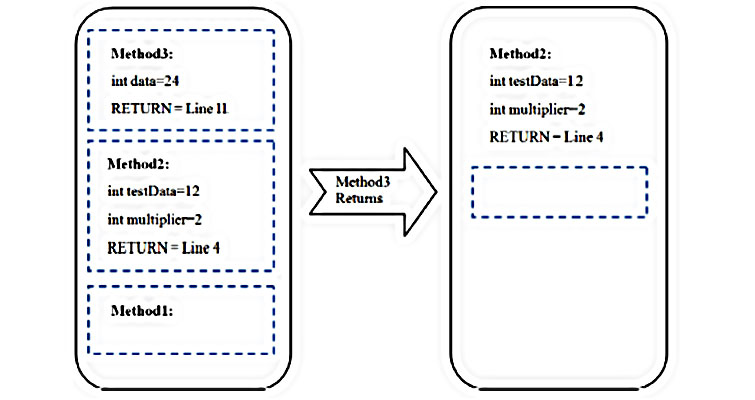
Стек вызовов
В программировании есть два вида стека — стек вызовов и стек данных.
Когда в программе есть подпрограммы — процедуры и функции, — то компьютеру нужно помнить, где он прервался в основном коде, чтобы выполнить подпрограмму. После выполнения он должен вернуться обратно и продолжить выполнять основной код. При этом если подпрограмма возвращает какие-то данные, то их тоже нужно запомнить и передать в основной код.
Чтобы это реализовать, компьютер использует стек вызовов — специальную область памяти, где хранит данные о точках перехода между фрагментами кода.
Допустим, у нас есть программа, внутри которой есть три функции, причём одна из них внутри вызывает другую. Нарисуем, чтобы было понятнее:

Программа запускается, потом идёт вызов синей функции. Она выполняется, и программа продолжает с того места, где остановилась. Потом выполняется зелёная функция, которая вызывает красную. Пока красная не закончит работу, все остальные ждут. Как только красная закончилась — продолжается зелёная, а после её окончания программа продолжает свою работу с того же места.


А вот как стек помогает это реализовать на практике:

Программа дошла до синей функции, сохранила точку, куда ей вернуться после того, как закончится функция, и если функция вернёт какие-то данные, то программа тоже их получит. Когда синяя функция закончится и программа получит верхний элемент стека, он автоматически исчезнет. Стек снова пустой.

С зелёной функцией всё то же самое — в стек заносится точка возврата, и программа начинает выполнять зелёную функцию. Но внутри неё мы вызываем красную, и вот что происходит:

При вызове красной функции в стек помещается новый элемент с информацией о данных, точке возврата и указанием на следующий элемент. Это значит, что когда красная функция закончит работу, то компьютер возьмёт из стека адрес возврата и вернёт управление снова зелёной функции, а красный элемент исчезнет. Когда и зелёная закончит работу, то компьютер из стека возьмёт новый адрес возврата и продолжит работу со старого места.
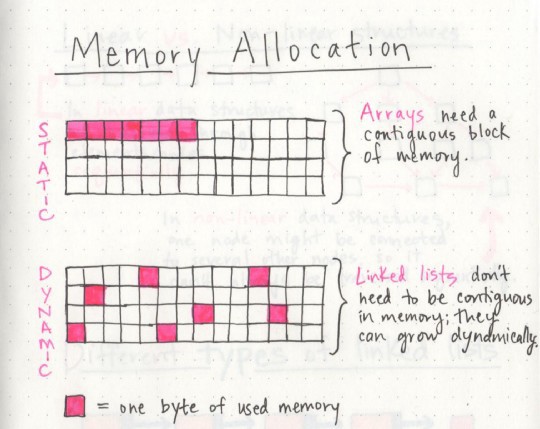
Динамически растущий стек на массиве
Динамически растущий стек используется в том случае, когда число элементов может быть значительным и не
известно на момент решения задачи. Максимальный размер стека может быть ограничен каким-то числом, либо размером оперативной памяти.
Стек будет состоять из указателя на данные, размера массива (максимального), и числа элементов в массиве. Это число также будет и указывать на вершину.
typedef struct Stack_tag {
T *data;
size_t size;
size_t top;
} Stack_t;
Для начала понадобится некоторый начальный размер массива, пусть он будет равен 10
#define INIT_SIZE 10
Алгоритм работы такой: мы проверяем, не превысило ли значение top значение size. Если значение превышено, то увеличиваем размер массива. Здесь возможно несколько вариантов того, как увеличивать массив. Можно прибавлять число, можно умножать на какое-то значение. Какой из вариантов лучше, зависит от специфики задачи. В нашем случае будем умножать размер на число MULTIPLIER
#define MULTIPLIER 2
Максимального размера задавать не будем. Программа будет выпадать при stack overflow или stack underflow. Будем реализовывать тот же интерфейс (pop, push, peek). Кроме того, так как массив динамический, сделаем некоторые вспомогательные функции, чтобы создавать стек, удалять его и чистить.
Во-первых, функции для создания и удаления стека и несколько ошибок
#define STACK_OVERFLOW -100
#define STACK_UNDERFLOW -101
#define OUT_OF_MEMORY -102
Stack_t* createStack() {
Stack_t *out = NULL;
out = malloc(sizeof(Stack_t));
if (out == NULL) {
exit(OUT_OF_MEMORY);
}
out->size = INIT_SIZE;
out->data = malloc(out->size * sizeof(T));
if (out->data == NULL) {
free(out);
exit(OUT_OF_MEMORY);
}
out->top = 0;
return out;
}
void deleteStack(Stack_t **stack) {
free((*stack)->data);
free(*stack);
*stack = NULL;
}
Всё крайне просто и понятно, нет никаких подвохов. Создаём стек с начальной длиной и обнуляем значения.
Теперь напишем вспомогательную функцию изменения размера.
void resize(Stack_t *stack) {
stack->size *= MULTIPLIER;
stack->data = realloc(stack->data, stack->size * sizeof(T));
if (stack->data == NULL) {
exit(STACK_OVERFLOW);
}
}
Здесь, заметим, в случае, если не удалось выделить достаточно памяти, будет произведён выход с STACK_OVERFLOW.
Функция push проверяет, вышли ли мы за пределы массива. Если да, то увеличиваем его размер
void push(Stack_t *stack, T value) {
if (stack->top >= stack->size) {
resize(stack);
}
stack->data = value;
stack->top++;
}
Функции pop и peek аналогичны тем, которые использовались для массива фиксированного размера
T pop(Stack_t *stack) {
if (stack->top == 0) {
exit(STACK_UNDERFLOW);
}
stack->top--;
return stack->data;
}
T peek(const Stack_t *stack) {
if (stack->top <= 0) {
exit(STACK_UNDERFLOW);
}
return stack->data;
}
Проверим
void main() {
int i;
Stack_t *s = createStack();
for (i = 0; i < 300; i++) {
push(s, i);
}
for (i = 0; i < 300; i++) {
printf("%d ", peek(s));
printf("%d ", pop(s));
}
deleteStack(&s);
_getch();
}
Напишем ещё одну функцию, implode, которая уменьшает массив до размера, равного числу элементов в массиве. Она может быть использована тогда, когда уже известно, что больше элементов вставлено не будет, и память может быть частично освобождена.
void implode(Stack_t *stack) {
stack->size = stack->top;
stack->data = realloc(stack->data, stack->size * sizeof(T));
}
Можем использовать в нашем случае
for (i = 0; i < 300; i++) {
push(s, i);
}
implode(s);
for (i = 0; i < 300; i++) {
printf("%d ", peek(s));
printf("%d ", pop(s));
}
Эта однопоточная реализация стека использует мало обращений к памяти, достаточно проста и универсальна, работает
быстро и может быть реализована, при необходимости, за несколько минут. Она используется
всегда в дальнейшем, если не указано иное.


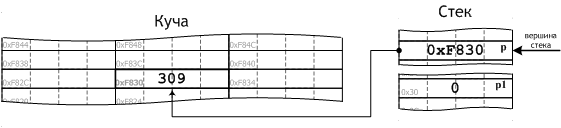



У неё есть недостаток, связанный с методом увеличения потребляемой
памяти. При умножении в 2 раза (в нашем случае) требуется мало обращений к памяти, но при этом каждое последующее увеличение может привести
к ошибке, особенно при маленьком количестве памяти в системе. Если же использовать более щадящий способ выделения памяти (например,
каждый раз прибавлять по 10), то число обращений увеличится и скорость упадёт. На сегодня, проблем с размером памяти обычно
нет, а менеджеры памяти и сборщики мусора (которых нет в си) работают быстро, так что агрессивное изменение преобладает
(на примере, скажем, реализации всей стандартной библиотеки языка Java).
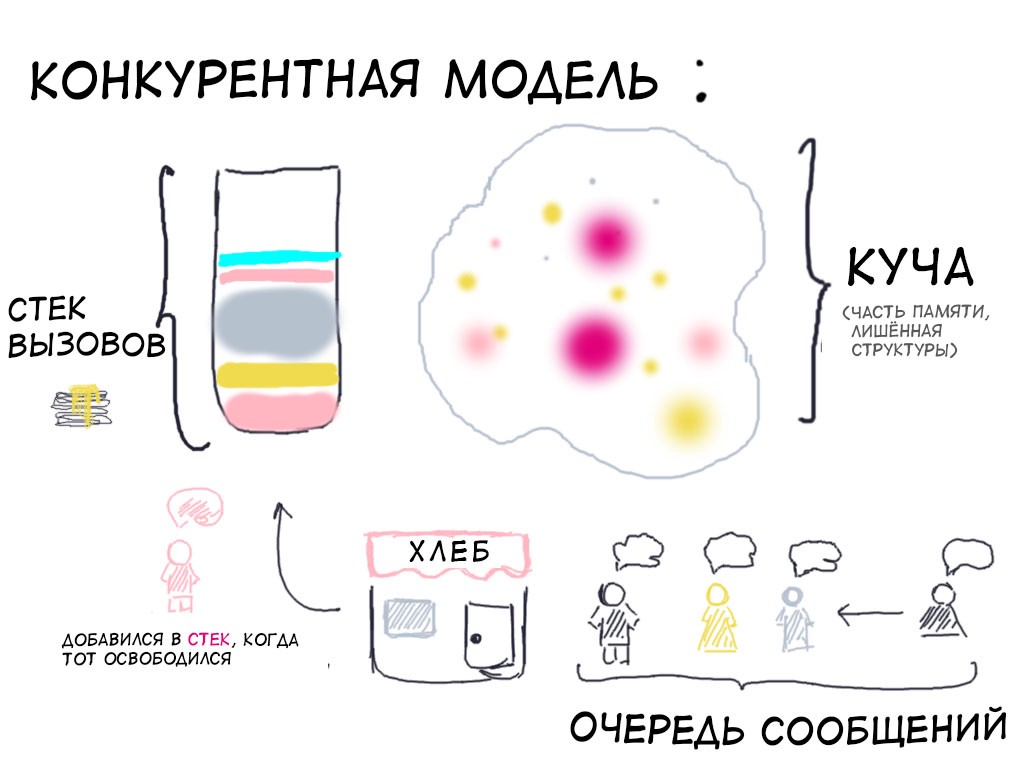
Сегменты
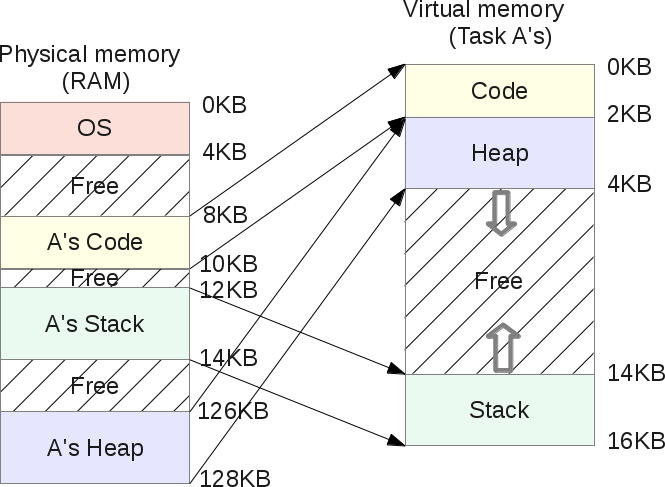
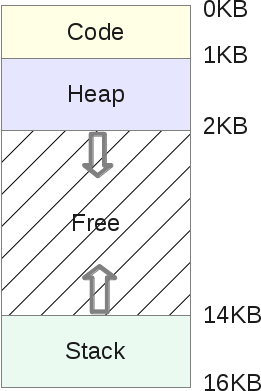
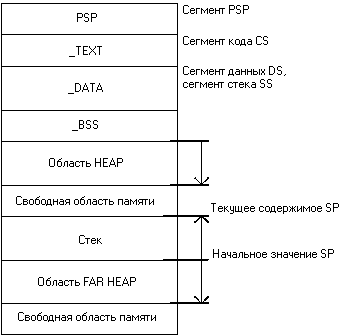
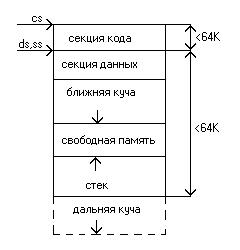
Память, которую используют программы, состоит из нескольких частей — сегментов:
Сегмент кода (или «текстовый сегмент»), где находится скомпилированная программа. Обычно доступен только для чтения.
Сегмент bss (или «неинициализированный сегмент данных»), где хранятся глобальные и статические переменные, инициализированные нулем.
Сегмент данных (или «сегмент инициализированных данных»), где хранятся инициализированные глобальные и статические переменные.
Куча, откуда выделяются динамические переменные.
Стек вызовов, где хранятся параметры функции, локальные переменные и другая информация, связанная с функциями.
Игра со средним стеком
Средний стек в покере – менее 35 больших блайндов. С ним нужно играть более осторожнее, чем с большим
Для такого количества фишек есть важное правило покера. На ранних позициях играйте пассивно, на поздних – максимально агрессивно
Средний стек опасен для многих оппонентов. Даже лидеры за столом боятся заходить против игрока со средним стеком, так как один неверный ва-банк способен выбить их из позиции лидерства. Многие играют тайтово против соперников со средними стеками, то есть повышают ставки только с сильной комбинацией в покере. Этим нужно пользоваться для победы. Можно чаще блефовать и стараться «украсть» банк до флопа. Благодаря быстрому получению блайндов на префлопе, можно за 3-4 раздачи подняться до большого стека в покере.







