cURL и аутентификация в веб-формах (передача данных методом GET и POST)
Аутентификация в веб-формах – это тот случай, когда мы вводим логин и пароль в форму на сайте. Именно такая аутентификация используется при входе в почту, на форумы и т. д.
Использование curl для получения страницы после HTTP аутентификации очень сильно различается в зависимости от конкретного сайта и его движка. Обычно, схема действий следующая:
1) С помощью Burp Suite или Wireshark узнать, как именно происходит передача данных. Необходимо знать: адрес страницы, на которую происходит передача данных, метод передачи (GET или POST), передаваемая строка.
2) Когда информация собрана, то curl запускается дважды – в первый раз для аутентификации и получения кукиз, второй раз – с использованием полученных кукиз происходит обращение к странице, на которой содержаться нужные сведения.
Используя веб-браузер, для нас получение и использование кукиз происходит незаметно. При переходе на другую страницу или даже закрытии браузера, кукиз не стираются – они хранятся на компьютере и используются при заходе на сайт, для которого предназначены. Но curl по умолчанию кукиз не хранит. И поэтому после успешной аутентификации на сайте с помощью curl, если мы не позаботившись о кукиз вновь запустим curl, мы не сможем получить данные.
Для сохранения кукиз используется опция —cookie-jar, после которой нужно указать имя файла. Для передачи данных методом POST используется опция —data. Пример (пароль заменён на неверный):
curl --cookie-jar cookies.txt http://forum.ru-board.com/misc.cgi --data 'action=dologin&inmembername=f123gh4t6&inpassword=111222333&ref=http%3A%2F%2Fforum.ru-board.com%2Fmisc.cgi%3Faction%3Dlogout'
Далее для получения информации со страницы, доступ на которую имеют только зарегестрированные пользователи, нужно использовать опцию -b, после которой нужно указать путь до файла с ранее сохранёнными кукиз:
curl -b cookies.txt 'http://forum.ru-board.com/topic.cgi?forum=35&topic=80699&start=3040' | iconv -f windows-1251 -t UTF-8
Эта схема может не работать в некоторых случаях, поскольку веб-приложение может требовать указание кукиз при использовании первой команды (встречалось такое поведение на некоторых роутерах), также может понадобиться указать верного реферера, либо другие данные, чтобы аутентификация прошла успешно.
Правовые нормы, применяемые к парсингу
Специфика работы роботов-парсеров и в целом системы парсинга приводит к следующему вопросу: разрешено ли использовать контент, размещенный в свободном доступе на других сайтах, в своих целях? Существуют определенные законодательные нормы, касающиеся вопросов интеллектуальной собственности и размещаемой в интернете информации. Согласно им:
-
запрещен сбор данных, имеющих отношение к коммерческой и государственной тайне;
-
противозаконным является нарушение авторских и смежных прав;
-
под запретом также находится доступ к охраняемой законом информации;
-
наконец, запрещено использовать гражданские права для ограничения конкуренции.
Исходя из этого, парсинг не является противозаконной операцией, но осуществлять его можно только при соблюдении соответствующих условий:
-
исследуемая информация должна находиться в открытом доступе и не быть под защитой закона об авторских и смежных правах;
-
сбор данных не должен приводить к сбоям в работе сети интернет и проблемам с ресурсами, являющимися источниками информации (слишком активная работа парсера может быть принята за DOS-атаку);
-
сбор должен проводиться только законными способами;
-
парсинг не должен ограничивать конкуренцию.
Процесс парсинга
Чтобы понять, как развивался Хабр, нужно было обойти по все его статьи и выделить из них метаинформацию (например, даты). Обход дался легко, потому что ссылки на все статьи имеют вид «habrahabr.ru/post/337722/», причём номера задаются строго по порядку. Зная, что последний пост имеет номер чуть меньше 350 тысяч, я просто прошёлся по всем возможным id документов циклом (код на Python):
Функция пытается загружает страницу с соответствующим id и пытается вытащить из структуры html содержательную информацию.
В процессе парсинга открыл для себя несколько новых моментов.
Во-первых, говорят, что создавать больше процессов, чем ядер в процессоре, бесполезно. Но в моём случае оказалось, что лимитирующий ресурс — не процессор, а сеть, и 100 процессов отрабатывают быстрее, чем 4 или, скажем, 20.
Во-вторых, в некоторых постах встречались сочетания спецсимволов — например, эвфемизмы типа «%&#@». Оказалось, что , который я использовал сначала, реагирует на комбинацию болезненно, считая её началом html-сущности. Я уж было собирался творить чёрную магию, но на форуме подсказали, что можно просто поменять парсер.
«Живых» статей оказалась только половина от потенциального максимума — 166307 штук. Про остальные Хабр даёт варианты «страница устарела, была удалена или не существовала вовсе». Что ж, всякое бывает.
За выгрузкой статей последовала техническая работа: например, даты публикации нужно было перевести из формата «’21 декабря 2006 в 10:47» в стандартный , а «12,8k» просмотров — в 12800. На этом этапе вылезло ещё несколько казусов. Самый весёлый связан с подсчётом голосов и типами данных: в некоторых старых постах произошло переполнение инта, и они получили по 65535 голосов.
В результате тексты статей (без картинок) заняли у меня 1.5 гигабайта, комментарии с метаинформацией — ещё 3, и около сотни мегабайт — метаинформация о статьях. Такое можно полностью держать в оперативной памяти, что было для меня приятной неожиданностью.
Начал анализ статей я не с самих текстов, а с метаинформации: дат, тегов, хабов, просмотров и «лайков». Оказалось, что и она может многое поведать.





![Результаты поиска по запросу «[парсинг сайтов]» / хабр](https://rusinfo.info/wp-content/uploads/3/5/8/3584bcc7a70fa007d396512d3efb250f.jpg)

Для чего нужен
С целью создания веб-сайта и его эффективного продвижения необходимо огромное количество контента, который нужно длительно формировать в ручном порядке.
Парсеры имеют последующие возможности:
- Обновление данных для поддержки актуальности. Прослеживать перемены курса валют либо прогноза погоды в ручном порядке невозможно, по этой причине прибегают к парсингу;
- Сбор и мгновенное дублирование информации с иных веб-сайтов для размещения на своем ресурсе. Сведения, приобретенные с помощью парсинга, подвергают рерайтингу. Подобное решение применяется для наполнения киносайтов, новостных проектов, ресурсов с кулинарными рецептами и других площадок;
- Соединение потоков данных. Ведется получение значительного количества сведений с некоторых источников, обрабатывание и распределение. Это комфортно для наполнения новостных площадок;
- Парсинг значительно ускоряет ход работы с ключевыми словами. Настроив работу, допустимо немедленно выбрать требуемые для продвижения запросы. После кластеризации по страничкам подготавливается SEO-контент, в котором будет предусмотрено наибольшее количество ключей.
Какие бывают виды
Приобретение сведений в интернете – сложная, обыденная, забирающая большое количество времени деятельность. Парсеры могут в сутки рассортировать значительную долю веб-ресурсов в поисках необходимых сведений, автоматизируют её.
Более стремительно «парсят» всеобщую сеть роботы поисковых концепций. Однако, сведения накапливаются парсерами и в индивидуальных интересах. На её базе, н-р, возможно писать диссертацию. Парсинг применяют программы автоматичного контроля уникальности текстовый данных, стремительно сопоставляя содержимое сотен веб-страничек с предоставленным текстом.
Выделяют 2 более распространенных разновидности парсинга в интернете:
- парсинг контента;
- парсинг итого в экстрадации поисковых концепций.
Некоторые программы объединяют данные функции, плюс затягивают добавочные функции и полномочия.
Парсинг в командной строке RSS, XML, JSON и других сложных форматов
RSS, XML, JSON и т.п. – это текстовые файлы, в которых данные структурированы определённым образом. Для разбора этих файлов можно, конечно, использовать средства Bash, но можно сильно упростить себе задачу, если задействовать PHP.
Если в системе установлен PHP, то необязательно использовать веб-сервер, чтобы запустить PHP скрипт. Это можно сделать прямо из командной строки. Например, имеется задача из файла по адресу https://hackware.ru/?feed=rss2 извлечь имена всех статей. Для этого создадим файл parseXML.php со следующим содержимым:
<?php
$t = $argv;
$str = new SimpleXMLElement($t);
foreach ($str->channel->item as $new_articles) {
echo $new_articles->title . PHP_EOL . PHP_EOL;
}
Запустить файл можно так:
php parseXML.php "`curl -s https://hackware.ru/?feed=rss2`"

В данном примере для получения файла с веб-сервера используется команда curl -s https://hackware.ru/?feed=rss2, полученный текстовый файл (строка) передаётся в качестве аргумента PHP скрипту, который обрабатывает эти данные.
Кстати, cURL можно было бы использовать прямо из PHP скрипта. Поэтому можно парсить в PHP не прибегая к услугам Bash. В качестве примера, создайте файл parseXML2.php со следующем содержимым:
<?php
$target_url = "https://hackware.ru/?feed=rss2";
$ch = curl_init($target_url);
curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1);
$response_data = curl_exec($ch);
if (curl_errno($ch) > 0) {
echo 'Ошибка curl: ' . curl_error($ch);
}
curl_close($ch);
$str = new SimpleXMLElement($response_data);
foreach ($str->channel->item as $new_articles) {
echo $new_articles->title . PHP_EOL . PHP_EOL;
}
И запустите его следующим образом из командной строки:
php parseXML2.php
Этот же самый файл parseXML2.php можно поместить в директорию веб-сервера и открыть в браузере.
Какие функции выполняют парсеры? Что с их помощью можно парсить?

Для того чтобы понять, для чего нужен парсинг, что это такое простыми словами, давайте рассмотрим области применения. Для сбора какой непосредственно информации нужно писать или покупать специальную программу?
Итак, я выделил следующие задачи для парсера (на самом деле их куда больше):
Парсер и публикатор для автозаполнения сайтов.Специально созданные парсеры с определенной частотой «проходят» по вэб-ресурсам из заданного списка. Если на них появились новые статьи, то они сразу перекопируются на свой ресурс.Подобное использование информации несколько граничит с воровством и в некотором роде является нарушением авторским прав. Почему только несколько? Потому что ни в какой стране нет такого закона, по которому запрещается использовать данные, находящиеся в свободном доступе. Раз не запрещено, значит, разрешено. Чего не скажешь о других данных, личных. Их собирать и использовать без разрешения владельцев запрещено.
Парсеры для обновления ленты новостей.Новостные интернет-ресурсы содержат много динамической информации, которая меняется очень быстро. Автоматическое отслеживание погоды, ситуации на дорогах, курса валют поручают парсеру.
Для составления семантического ядра.В этом случае программа ищет ключевые слова (запросы), относящиеся к заданной теме, определяет их частотность. Затем собранные ключевые слова объединяют в классы (кластеризация запросов). В дальнейшем на основе семантического ядра (СЯ) пишутся статьи, способствующие продвижению вашего ресурса в поисковой выдачиЯ очень часто использую такой парсер, называется он Key Collector. Если кому интересно, сбор ключевых слов для продвижения сайта выглядит так:

Парсер для аудита сайтаПрограмма-парсер находит заголовки и подзаголовки страниц, вплоть до 5-6 уровня, описания, изображения с их свойствами и другие данные, которые «возвращает» в виде необходимой таблицы. Такой анализ помогает проверить сайт на соответствие требованиям поисковых систем (такая проверка напрямую связана с продвижением ресурса в интернете, ведь чем лучше настроен сайт, тем больше у него шансов занять верхние строчки в поисковой выдаче)
Определение перспективных ключевых фраз
Когда денег на SEO мало (в случае с МСБ это почти всегда так), продвигаться по ядру из тысяч запросов не получится. Придется выбирать самые «жирные» из них, а остальные откладывать до лучших времен.
Один из способов — выбрать фразы, по которым страницы сайта находятся с 5 по 20 позицию в Google. По ним можно быстрее и с меньшими затратами выйти в ТОП-5. Ну и скачок позиций, скажем, с двенадцатой на третью даст намного больше трафика, чем с 100-й на 12-ю (узнать точный прирост трафика вы можете с помощью сценарного прогноза в Data Studio).
Позиции по ключевым фразам в Google доступны в Search Console. Для их выгрузки есть шаблон, описанный в Codingisforlosers.
Для выгрузки ключей из ТОП-20 необходимо:
- создать копию шаблона Quick Wins Keyword Finder (все шаблоны в статье закрыты от редактирования, просьба не запрашивать права доступа — просто создайте копию и используйте ее);
- установить дополнение для Google Sheets Search Analytics for Sheets (для настройки экспорта отчетов из Search Console в Google Sheets);
- иметь доступ к аккаунту в Search Console и накопленную статистику по запросам (хотя бы за пару месяцев).
Открываем шаблон и настраиваем выгрузку данных из Search Console (меню «Дополнения» / «Search Analytics for Sheets» / «Open Sidebar»).
Для автоматической выгрузки на вкладке «Requests»:
- в поле «Verified Site» выбираем сайт (после подтверждения доступа к аккаунту в появится список сайтов);
- в поле «Group By» выбираем «Query» и «Page» (то есть мы будем извлекать данные по запросам и страницам);
- в поле «Results Sheet» обязательно задаем «RAW Data», иначе шаблон работать не будет.
Нажимаем кнопку «Request Data». После экспорт данных на листе «Quick Wins» указаны запросы, страницы, количество кликов, показов, средний CTR и позиция за период. Эти ключи подходят для приоритетного продвижения.





Помимо автоматической выгрузки в шаблоне есть ручной режим. Перейдите на вкладку «MANUAL» и введите данные (ключи, URL и позиции). На вкладке «Quick Wins » будет выборка перспективных запросов.
Определение «скрытых» данных на уровне ключевых слов
В Google Analytics есть возможность подгрузить данные из Search Console. Но вы не увидите ничего нового — все те же страницы, CTR, позиции и показы. А было бы интересно посмотреть, какой процент отказов при переходе по тем или иным ключевым словам и, что еще интересней, сколько достигнуто целей по ним.
Тут поможет шаблон от Sarah Lively, который описан в статье для MOZ.
Для начала работы установите дополнения для Google Sheets:
- Google Analytics Spreadsheet Add-on;
- Search Analytics for Sheets (если вы использовали первые два шаблона, то это дополнение у вас уже есть).
Шаг 1. Настраиваем выгрузку данных из Google Analytics
Создайте новую таблицу, откройте меню «Дополнения» / «Google Analytics» и выберите пункт «Create new report».
Заполняем параметры отчета:
- Name — «Organic Landing Pages Last Year»;
- Account — выбираем аккаунт;
- Property — выбираем ресурс;
- View — выбираем представление.
Нажимаем «Create report». Появляется лист «Report Configuration». Вначале он выглядит так:
Но нам нужно, чтобы он выглядел так (параметры выгрузки вводим вручную):
Просто скопируйте и вставьте параметры отчетов (и удалите в поле Limit значение 1000):
| Report Name | Organic Landing Pages Last Year | Organic Landing Pages This Year |
| View ID | //здесь будет ваш ID в GA!!! | //здесь будет ваш ID в GA!!! |
| Start Date | 395daysAgo | 30daysAgo |
| End Date | 365daysAgo | yesterday |
| Metrics | ga:sessions, ga:bounces, ga:goalCompletionsAll | ga:sessions, ga:bounces, ga:goalCompletionsAll |
| Dimensions | ga:landingPagePath | ga:landingPagePath |
| Order | -ga:sessions | -ga:sessions |
| Filters | ||
| Segments | sessions::condition::ga:medium==organic | sessions::condition::ga:medium==organic |
После этого в меню «Дополнения» / «Google Analytics» нажмите «Run reports». Если все хорошо, вы увидите такое сообщение:
Также появится два новых листа с названиями отчетов.
Шаг 2. Выгрузка данных из Search Console
Работаем в том же файле. Переходим на новый лист и запускаем дополнение Search Analytics for Sheets.
Параметры выгрузки:
- Verified Site — указываем сайт;
- Date Range — задаем тот же период, что и в отчете «Organic Landing Pages This Year» (в нашем случае — последний месяц);
- Group By — «Query», «Page»;
- Aggregation Type — «By Page»;
- Results Sheet — выбираем текущий «Лист 1».
Выгружаем данные и переименовываем «Лист 1» на «Search Console Data». Получаем такую таблицу:
Для приведения данных в сопоставимый с Google Analytics вид меняем URL на относительные — удаляем название домена (через функцию замены меняем домен на пустой символ).
После изменения URL должны иметь такой вид:
Шаг 3. Сводим данные из Google Analytics и Search Console
Копируем шаблон Keyword Level Data. Открываем его и копируем лист «Keyword Data» в наш рабочий файл. В столбцы «Page URL #1» и «Page URL #2» вставляем относительные URL страниц, по которым хотим сравнить статистику.
По каждой странице подтягивается статистика из Google Analytics, а также 6 самых популярных ключей, по которым были переходы. Конечно, это не детальная статистика по каждому ключу, но все же это лучше, чем ничего.






При необходимости вы можете доработать шаблон — изменить показатели, количество выгружаемых ключей и т. п. Как это сделать, детально описано в оригинальной статье.
Как видите, для работы с ключами не обязательно сразу доставать кошелек. Есть немало простых решений. Следите за нашими публикациями — мы еще не раз поделимся полезностями.
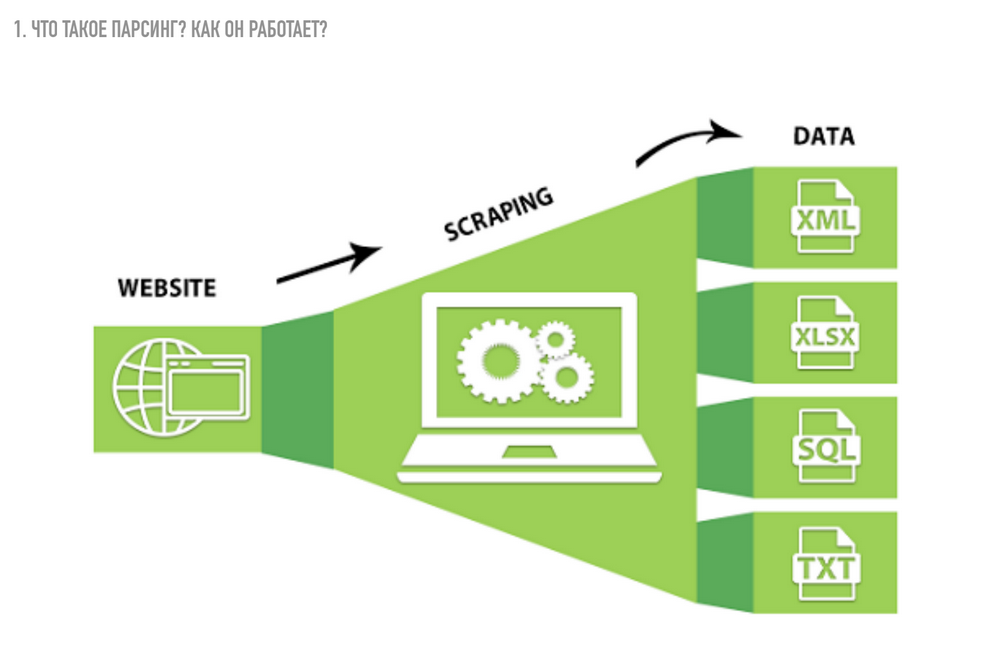
Что такое парсер и как он работает

Парсер – это некое программное обеспечение или алгоритм с определенной последовательностью действий, цель работы которого получить заданную информацию.
Сбор информации происходит в 3 этапа:
- Сканирование
- Выделение заданных параметров
- Составление отчета
Чаще всего парсер — это платная или бесплатная программа или сервис, созданный под ваши требования или выбранный вами для определенных целей. Подобных программ и сервисов очень много. Чаще всего языком написания является Python или PHP.
Но также есть и отдельные программы, которые позволяют писать парсеры. Например я пользуюсь программой ZennoPoster и пишу парсеры в ней — она позволяет собирать парсер как конструктор, но работать он будет по тому же принципу, что и платные/бесплатные сервисы парсинга.
Для примера можете посмотреть это видео в котором я показываю, как я создавал парсер для сбора информации с сервиса spravker.ru.
https://vk.com/video_ext.php
Чтобы было понятнее, давайте разберем каких типов и видов бывают парсеры:
Не следует забывать о том, что парсинг имеет определенные минусы. Недостатком использования считаются технические сложности, которые парсер может создать. Так, подключения к сайту создают нагрузку на сервер. Каждое подключение программы фиксируется. Если подключаться часто, то сайт может вас заблокировать по IP (но это легко можно обойти с помощью прокси).
Парсинг: что это такое простыми словами
Парсинг — это процесс автоматического сбора информации по заданным нами критериям. Для лучшего понимания давайте разберем пример:
Грубо говоря парсинг позволяет автоматизировать сбор любой информации по заданным нами критериям. Думаю понятно, что использовать ручной способ сбора информации малоэффективно (особенно в наше время, когда информации слишком много).
Для наглядности хочу сразу показать главные преимущества парсинга:
Преимущество №1 — Скорость. За одну единицу времени автомат может выдавать в разы больше деталей или в нашем случае информации, чем, если бы мы с лупой в руках отыскивали ее на страницах сайта. Поэтому компьютерные технологии в обработке информации превосходят ручной сбор данных.
Преимущество №2 — Структура или «скелет» будущего отчета. Мы собираем лишь те данные, которые заинтересованы получить. Это может быть что угодно. Например, цифры (цена, количество), картинки, текстовое описание, электронные адреса, ФИО, никнеймы, ссылки и прочее. Нам нужно только заранее обдумать, какую информацию мы хотим получить.
Преимущество №3 — Подходящий вид отчета. Мы получаем итоговый файл с массивом данных в требуемом формате (XLSX, CSV, XML, JSON) и можем даже сразу использовать его, вставив в нужное место на своем сайте.
Если говорить о наличие минусов, то это, разумеется, отсутствие у полученных данных уникальности. Прежде всего, это относится к контенту, мы ведь собираем все из открытых источников и парсер не уникализирует собранную информацию.
Думаю, что с понятием парсинга мы разобрались, теперь давайте разберемся со специальными программами и сервисами для парсинга.
Классификация программ и инструментов для парсинга
По использованию ресурсов
Это
важный момент, если парсер будет использоваться для бизнес задач и регулярно, вам нужно решить на чьей стороне будет работать алгоритм, на стороне исполнителя или вашей. С одной стороны, для развертывания облачного решения у себя, потребуется специалист для установки и поддержки софта, выделенное место на сервере, и работа программы будет отъедать серверные мощности. И это дорого. С другой, если вы можете себе
это позволить, возможно такое решение обойдется дешевле (если масштабы сбора данных действительно промышленные), нужно изучать тарифные сетки.
Есть
еще момент с приватностью, политики некоторых компаний не позволяют хранить данные на чужих серверах и тут нужно смотреть на конкретный сервис, во-первых, собранные парсером данные могут передаваться сразу по
API, во-вторых, этот момент решается дополнительным пунктом в соглашении.
Удаленные решения
Сюда
отнесем облачные программы (SaaS-решения), главное преимущество таких решений в том, что они установлены на удаленном сервере и не используют ресурсы вашего компьютера. Вы подключаетесь к серверу через браузер (в этом случае возможна работа с любой ОС) или приложение и берете нужные вам данные.
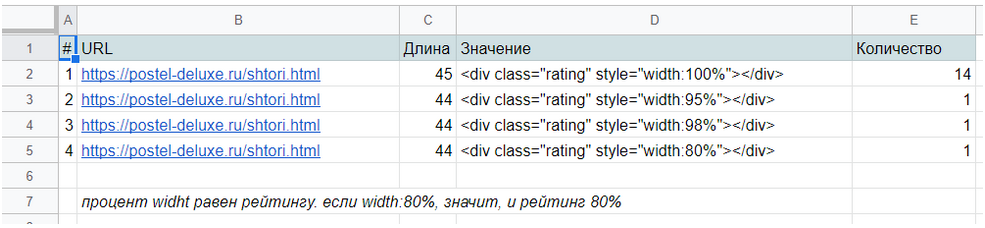
Облачные сервисы, как и все готовые решения в этой статье, не гарантируют, что вы сможете парсить любой сайт. Вы можете столкнуться со сложной структурой, технологией сайта, которую «не понимает» сервис, защитой, которая окажется «не по зубам» или невозможностью интерпретировать данные (например, вывод текстовых данных
не текстом, а картинками).
Плюсы:
- Не требуют установки на компьютер;
- Данные хранятся удаленно и не расходуют место, вы скачиваете только нужные результаты;
- Могут работать с большими объемами данных;
- Возможность работы по API и последующей автоматизации визуализации данных;
Минусы:
- Как правило, дороже десктоп решений;
- Требуют настройки и обслуживания;
- Невозможность парсить сайты со сложной защитой и/или интерпретировать данные.
Рассмотрим популярные сервисы и условия работы.
Octoparse — один из популярных облачных сервисов.
Извлечение информации из заголовков при использовании cURL
Иногда необходимо извлечь информацию из заголовка, либо просто узнать, куда делается перенаправление.
Заголовки – это некоторая техническая информация, которой обмениваются клиент (веб-браузер или программа curl) с веб-приложением (веб-сервером). Обычно нам не видна эта информация, она включает в себя такие данные как кукиз, перенаправления (редиректы), данные о User Agent, кодировка, наличие сжатия, информация о рукопожатии при использовании HTTPS, версия HTTP и т.д.









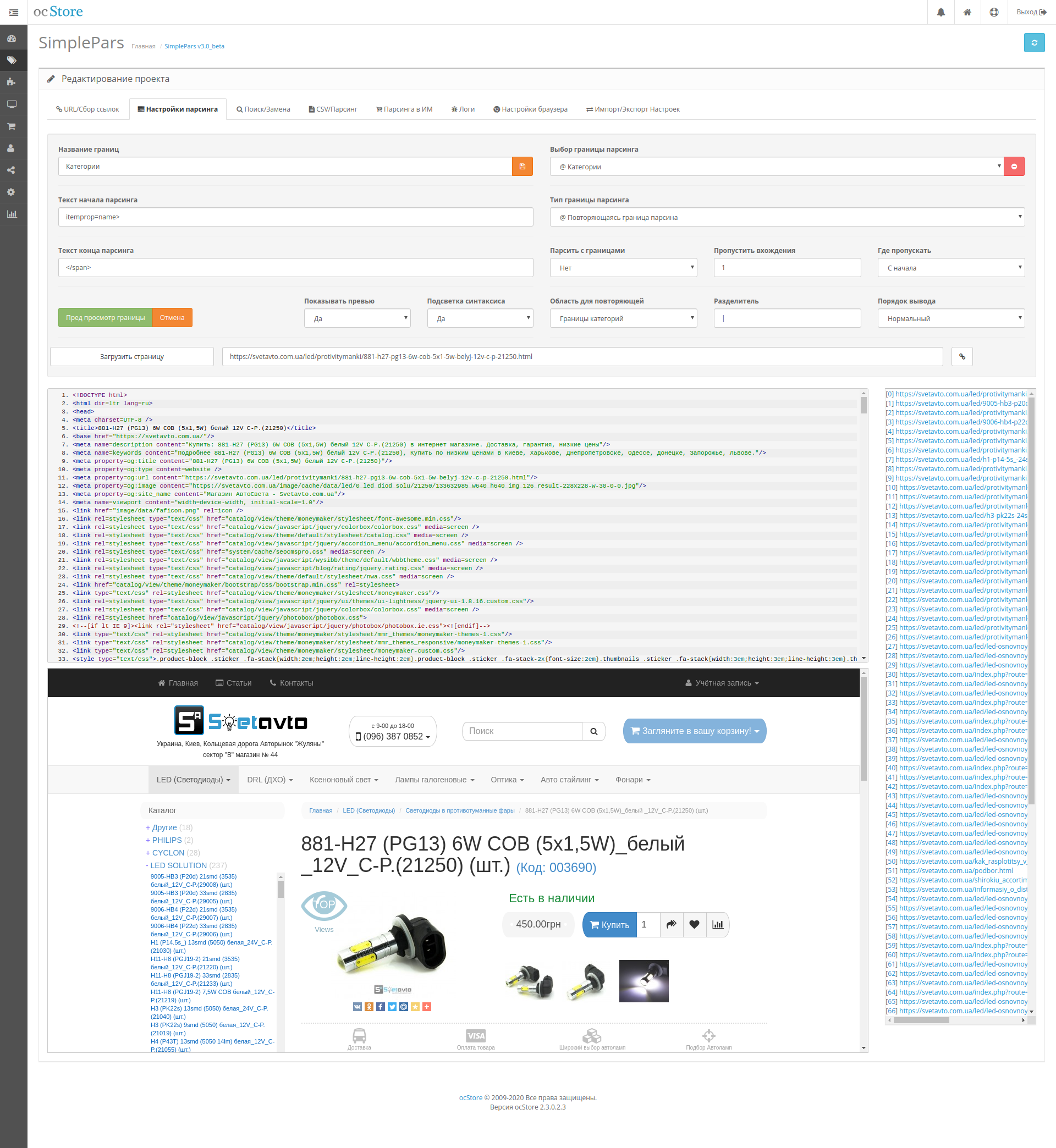
Пример команды:
curl -s -I -A 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/64.0.3282.140 Safari/537.36' https://www.acrylicwifi.com/AcrylicWifi/UpdateCheckerFree.php?download | grep -i '^location'
Получаемый результат:
location: https://tarlogiccdn.s3.amazonaws.com/AcrylicWiFi/Home/Acrylic_WiFi_Home_v3.3.6569.32648-Setup.exe
В этой команде имеются уже знакомые нам опции -s (подавление вывода) и -A (для указания своего пользовательского агента).
Новой опцией является -I, которая означает показывать только заголовки. Т.е. не будет показываться HTML код, поскольку он нам не нужен.
На этом скриншоте видно, в какой именно момент отправляется информация о новой ссылке для перехода:

curl -s -v http://www.paterva.com/web7/downloadPaths41.php -d 'fileType=exe&os=Windows' 2>&1 | grep -i 'Location:'
Обратите внимание, что в этой команде не использовалась опция -I, поскольку она вызывает ошибку:
Warning: You can only select one HTTP request method! You asked for both POST Warning: (-d, --data) and HEAD (-I, --head).
Суть ошибки в том, что можно выбрать только один метод запроса HTTP, а используются сразу два: POST и HEAD.
Кстати, опция -d (её псевдоним упоминался выше (—data), когда мы говорили про HTML аутентификацию через формы на веб-сайтах), передаёт данные методом POST, т.е. будто бы нажали на кнопку «Отправить» на веб-странице.
В последней команде используется новая для нас опция -v, которая увеличивает вербальность, т.е. количество показываемой информации. Но особенностью опции -v является то, что она дополнительные сведения (заголовки и прочее) выводит не в стандартный вывод (stdout), а в стандартный вывод ошибок (stderr). Хотя в консоли всё это выглядит одинаково, но команда grep перестаёт анализировать заголовки (как это происходит в случае с -I, которая выводит заголовки в стандартный вывод). В этом можно убедиться используя предыдущую команду без 2>&1:
curl -s -v http://www.paterva.com/web7/downloadPaths41.php -d 'fileType=exe&os=Windows' | grep -i 'Location:'
Строка с Location никогда не будет найдена, хотя на экране она явно присутствует.
Конструкция 2>&1 перенаправляет стандартный вывод ошибок в стандартный вывод, в результате внешне ничего не меняется, но теперь grep может обрабатывать эти строки.
Более сложная команда для предыдущего обработчика форм (попробуйте в ней разобраться самостоятельно):
timeout 10 curl -s -L -v http://www.paterva.com/web7/downloadPaths.php -d 'fileType=exe&client=ce&os=Windows' -e 'www.paterva.com/web7/downloads.php' 2>&1 >/dev/null | grep -E 'Location:'
Парсинг вопросов-ответов в результатах поиска
Вопросы/ответы можно извлекать и вручную из результатов поиска. Но зачем, если есть шаблон от Hannah Rampton?
Это один из шаблонов, который мы используем при поиске идей для контента и постановке ТЗ копирайтерам. Анализ вопросов, связанных с основным запросом, позволяет углубиться в тему и создать интент-ориентированный контент (подробнее — в нашей статье об алгоритме Neural Matching).
Для выгрузки вопросов/ответов:
- создайте копию шаблона Google Q&A Extraction_v2;
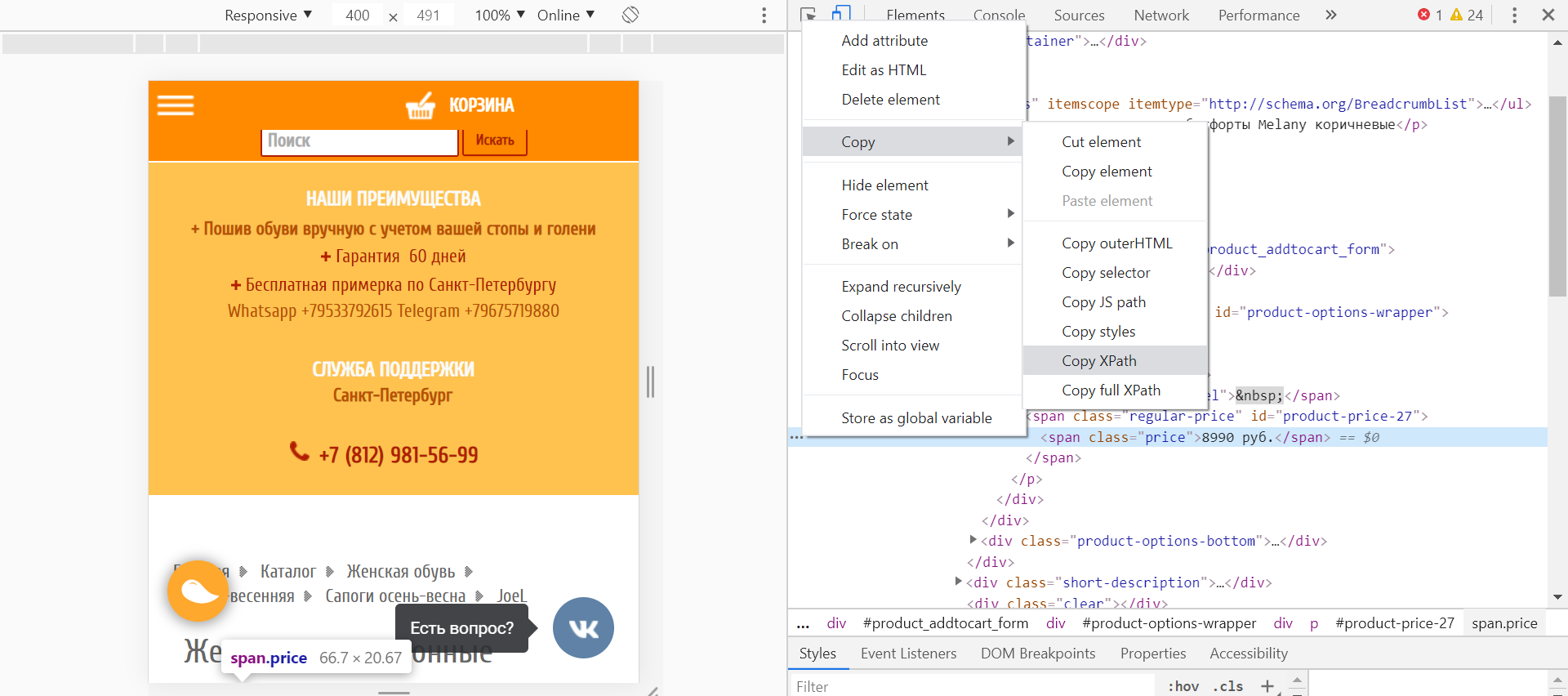
- установите бесплатное расширение Scraper для Chrome (оно парсит данные с веб-страниц с помощью XPath);
- измените в настройках поисковика язык с русского на английский (это нужно для корректной работы формул в шаблоне).
Приступаем к парсингу вопросов/ответов:
в открывшемся окне в блоке «Selector» выбираем «XPath», вводим в поле запрос для парсинга раскрывающихся списков с вопросами/ответами: //g-accordion-expander (обратите внимание, чтобы блок Columns был заполнен так же, как на скриншоте);
нажимаем «Scrape»;
- после парсинга нажимаем «Copy to clipboard»;
- открываем шаблон, переходим на лист «Google Questions and Answers», наводим курсор на ячейку А10 и нажимаем Ctrl+Shift+V.
Если все сделано верно, то поля с вопросами, ответами и URL заполнятся автоматически.
На листе «Clean Data» та же информация представлена в юзабельном текстовом формате (кроме того, здесь исключены дубли).
На листе «Search by Keyword» вы можете найти вопросы по заданному ключевому слову (или его части).
Также вы можете выбрать вопросы по домену — для этого на листе «Search by Domain» введите полный URL или его часть.
Таким образом, вы быстро и бесплатно найдете релевантные вопросы по вашей тематике.
Как правильно выбрать парсер
- Сначала определите ваши задачи: мониторинг цен, продуктовая аналитика, машинное обучение, SEO данные, автоматизация процессов;
- Определите источники сбора данных: сайты конкурентов, источники данных для обучения, ваш сайт и т.д.;
- Определите
объем данных, который вы планируете собирать, от этого напрямую зависит
какие ресурсы потребуются на реализацию проекта; - Определите частоту сбора данных.
Если
у вас стандартная задача с небольшим объемом данных и есть отдельный человек для выполнения задачи, то вам подойдет готовое решение в виде программы или расширения для браузера.
Для парсинга сложных сайтов
с определенной регулярностью обратите внимание на облачные решения. Вам
потребуется отдельный сотрудник для ведения этого проекта
Если задача завязана на увеличение прибыли или даже жизнеспособность проекта стоит обратить внимание на облачный сервис с возможностью программировать или библиотеки для парсинга, выделить отдельного программиста для этой задачи и серверные мощности. Если нужно получить решение быстро и нужно быть уверенным в качестве результата, стоить выбрать компанию реализующую проект под ключ
Если нужно получить решение быстро и нужно быть уверенным в качестве результата, стоить выбрать компанию реализующую проект под ключ.
Защита от парсинга
Нормальным желанием любого владельца интернет-ресурса станет защита информации, размещенной на сайте. При наполнении сайта контентом, разработанным собственными силами, его заимствование может быть крайне неприятным. Существует несколько способов борьбы с нежелательным парсингом.




Разграничение прав доступа. Информация о структуре сайта скрывается от роботов и остается доступной только для администрации. Это наиболее простой способ защиты информации.
Черные и белые списки. Пользователи, которые пытаются украсть контент, отправляются в списки нежелательных, в соответствии с чем к ним применяются установленные санкции.

Временная задержка между запросами. Парсинг отличается направлением постоянных хаотических запросов. Установка временной задержки для обращений, отправляемых с одного компьютера, позволит ограничить доступ к информации.
Различные методы защиты от роботов. Установка на сайте авторизации, которую может пройти только человек (ввод капчи, подтверждение регистрации и другие способы).

Особенности парсинга веб-сайтов
Одной из особенностей парсинга веб-сайтов является то, что как правило мы работаем с исходным кодом страницы, т.е. HTML кодом, а не тем текстом, который показывается пользователю. Т.е. при создании регулярного выражения grep нужно основываться на исходном коде, а не на результатах рендеринга. Хотя имеются инструменты и для работы с текстом, получающимся в результате рендеринга веб-страницы – об этом также будет рассказано ниже.
В этом разделе основной упор сделан на парсинг из командной строки Linux, поскольку это самая обычная (и привычная) среда работы для тестера на проникновение веб-приложений. Будут показаны примеры использования разных инструментов, доступных из консоли Linux. Тем не менее, описанные здесь приёмы можно использовать в других операционных системах (например, cURL доступна и в Windows), а также в качестве библиотеки для использования в разных языках программирования.
Подразумевается, что вы понимаете принципы работы командной строки Linux. Если это не так, то рекомендуется ознакомиться с циклом:
- Азы работы в командной строке Linux (часть 1)
- Азы работы в командной строке Linux (часть 2)
- Азы работы в командной строке Linux (часть 3)







