Сколько платят на позиции Data Scientist
New.HRОксана Прутьянова, руководитель практики аналитики и Data Scientists в New.HR
- общий опыт работы по специальности;
- глубина профессиональной экспертизы;
- образование в статусном и котируемом вузе. Например, сильных аналитиков готовят в МФТИ, МГУ, ИТМО;
- локация — в Москве денег больше. Но даже в регионах можно зарабатывать сопоставимые деньги. Например, в городах с сильной академической базой, таких как Новосибирск. Также на столичный уровень зарплаты можно рассчитывать, работая над проектом дистанционно;
- знание английского языка сильно расширяет возможности и позволяет состоять в мировом профессиональном сообществе. Следить за публикациями, учиться по программам лучших мировых вузов, рассматривать вакансии за рубежом, писать статьи на английском.
Теория
По ходу изучения технических моментов вам неизбежно будет встречаться теория, которая стоит за кодом.
Например, я изучаю код, чтобы научиться применять какую-то технику (скажем, метод k-средних, KMeans), а когда она сработает, начинаю глубже разбираться с понятиями, которые с ней связаны (например, с инертностью, Inertia).
- Все сопутствующие алгоритмам математические термины есть в той же .
- Ниже я перечислю главное, что нужно изучить из теории вместе с прикладными аспектами. Почти по всем этим вещам есть бесплатные уроки на khan academy. Во время регистрации или в профиле можно выбрать нужные вам дисциплины, и сайт выдаст пошаговый план по каждому предмету.
Математика
Математический анализ (Calculus)
В этом разделе математики рассматривается связь между функцией и её производной, из-за которой изменение одной переменной величины приводит к изменению другой. Матанализ позволяет, например, выявлять паттерны, понимать, как функция меняется с течением времени.
В машинном обучении матанализ помогает оптимизировать производительность алгоритмов. Один из примеров — метод градиентного спуска. Он состоит в том, что при обучении по одному изменяют весовые коэффициенты нейросети для поиска минимального значения функции потерь.
Что нужно знать.
Производные (Derivatives)
- Геометрический смысл (Geometric definition)
- Вычисление производной функции (Calculating the derivative of a function)
- Нелинейные функции (Nonlinear functions)
Цепное правило (или Правило дифференцирования сложной функции, Chain rule)
- Сложные функции (Composite functions)
- Производные сложных функций (Composite function derivatives)
- Множественные функции (Multiple functions)
Градиенты (Gradients)
- Частные производные (Partial derivatives)
- Производные по направлению (Directional derivatives)
- Интегралы (Integrals)
Линейную алгебру (Linear Algebra)
Многие распространённые инструменты машинного обучения, в том числе XGBOOST, для хранения входных данных и обработки данных используют матрицы. Матрицы, наряду с векторными пространствами и линейными уравнениями, изучает линейная алгебра
Уверенное знание этого раздела математики очень важно для понимания механизма многих методов машинного обучения
Что нужно знать
Векторы и пространства (Vectors and spaces)
- Векторы (Vectors)
- Линейные комбинации (Linear combinations)
- Линейная зависимость и независимость (Linear dependence and independence)
- Скалярное произведение и векторное произведение (Vector dot and cross products)
Матричные преобразования (Matrix transformations)
- Функции и линейные преобразования (Functions and linear transformations)
- Умножение матриц (Matrix multiplication)
- Обратные функции (Inverse functions)
- Транспонирование матрицы (Transpose of a matrix)
Статистика для Data Scientist
Что нужно знать
Описательная/дескриптивная статистика (Descriptive/Summary statistics)
- Описание выборки данных (How to summarise a sample of data)
- Типы распределений (Different types of distributions)
- Асимметрия, эксцесс, меры центральной тенденции, например среднее арифметическое, медиана, мода (Skewness, kurtosis, central tendency, e.g. mean, median, mode)
- Меры зависимости и взаимосвязь переменных величин, например корреляция и ковариация (Measures of dependence, and relationships between variables such as correlation and covariance)
Планирование эксперимента (Experiment design)
- Проверка гипотез (Hypothesis testing)
- Семплирование (Sampling)
- Тесты на статистическую значимость (Significance tests)
- Случайность (Randomness)
- Вероятность (Probability)
- Доверительные интервалы и статистический вывод по двум выборкам (Confidence intervals and two-sample inference)

11 курсов по Data Science для новичков и профессионалов
По теме
11 курсов по Data Science для новичков и профессионалов
Машинное обучение (Machine learning)
- Вывод о наклоне линии регрессии (Inference about slope)
- Линейная и нелинейная регрессия (Linear and non-linear regression)
- Классификация (Classification)
Программирование
Если вы планируете карьеру в области науки о данных, вам нужно изучить программирование на должном уровне. Именно по этой причине многие специалисты в области данных обладают бэкграундом в компьютерных науках: это большое преимущество. Однако, если вы читаете эту статью и не обладаете опытом в программировании — не волнуйтесь, как и большинству вещей, этому можно обучиться самостоятельно.






Программа обучения: «Профессия Python-разработчик»
Мы выяснили, что программирование — важный навык для специалистов в области данных независимо от того, в какой сфере вы находитесь. Однако программирование в целом — не совсем то, что нужно науке о данных. А вот если вы сможете писать программы для автоматизации задач, то не только сэкономите драгоценное время, но и значительно упростите использование кода в будущем.
Перейдем к некоторым ключевым навыкам. В списке я уделил больше внимания практическим навыкам.
Что надо знать
Разработка. Специалисты в области данных, знакомые с практикой разработки программного обеспечения, обычно чувствуют себя более комфортно, чем ученые, работая над крупными коммерческими проектами.
Базы данных. Логично, что специалисты в области данных постоянно используют базы данных, поэтому нужно иметь опыт в этой области. По мере роста баз данных NoSQL и количества облачных вычислений число традиционных SQL-баз данных резко сокращается. Однако работодатели по-прежнему ожидают, что вы будете иметь базовые знания о командах SQL и практику проектирования баз данных.
Сотрудничество. Сотрудничество — ключевой момент в разработке программного обеспечения. Вы, несомненно, знакомы с выражением: «Сила команды определяется её самым слабым звеном». Хоть это и банально, но правдиво для любой команды, специализирующейся в науке о данных. Большая часть работы ведется в группах, поэтому необходимо налаживать связь с командой, а также поддерживать хорошие отношения, чтобы эффективность сотрудничества была максимальной.
Полезные советы
Если спросить любого разработчика программного обеспечения или дата сайентиста о том, какой самый важный аспект программирования в работе, они обязательно ответят одинаково: простота технического сопровождения. Простой, поддерживаемый код почти всегда превосходит пусть и гениальный, но сложный код — он в конечном счете не будет иметь значения, если другие программисты не смогут его понять, оценить, масштабировать и поддерживать в дальнейшем. Есть несколько способов легко улучшить код. Вот они.
Не нужно хардкодить: не указывайте постоянных значений для каких-либо параметризуемых элементов кода, вместо этого используйте переменные и входные данные, они динамичны по своей природе и будут масштабироваться в будущем, в отличие от статических значений. Это небольшое изменение в коде значительно облегчит вам жизнь.
Документируйте и постоянно комментируйте свой код: самый эффективный способ сделать код понятнее — это комментировать, комментировать и комментировать. Кратко и информативно комментируя происходящее, вы убережете себя от бесконечных изменений и объяснений с коллегами.
Проводите рефакторинг: помните, что окончание разработки кода — это еще не конец. Постоянно возвращайтесь к прошлым работам и ищите способы оптимизации и повышения эффективности.
Что почитать
Навыки разработки программного обеспечения для специалистов в области данных (англ.) — отличный обзор важных навыков программирования.Пять измерений дата сайентиста (англ.) — интересный подход к различным ролям, которые может взять на себя специалист в области данных
Обратите особое внимание на «Программист-эксперт» и «Эксперт по базам данных».9 навыков, необходимых для старта карьеры в области данных (англ.) — короткая, но интересная статья
Основная работа ведётся на удалённом сервере
Большинство людей начинают своё путешествие по Data Science на персональных компьютерах. Однако в реальных проектах зачастую требуется гораздо большая вычислительная мощность, которую не сможет обеспечить ни ноутбук, ни даже игровой ПК. Поэтому исследователи Data Science используют свои компьютеры для доступа к удалённому серверу по SSH (Secure Shell). SSH позволяет безопасно подключиться к вычислительной машине. После установки соединения удалённый сервер можно использовать как командную оболочку вашего компьютера. Поэтому при работе с сервером пригодится знание основных команд для Linux и опыт использования терминала.
Kaggle: Британские спутниковые снимки. Как мы взяли третье место
Сразу оговорюсь, что данный текст — это не сухая выжимка основных идей с красивыми графиками и обилием технических терминов (такой текст называется научной статьей и я его обязательно напишу, но потом, когда нам заплатят призовые $20000, а то, не дай бог, начнутся разговоры про лицензию, авторские права и прочее.) (UPD: https://arxiv.org/abs/1706.06169). К моему сожалению, пока устаканиваются все детали, мы не можем поделиться кодом, который написали под эту задачу, так как хотим получить деньги. Как всё утрясётся — обязательно займемся этим вопросом. (UPD: https://github.com/ternaus/kaggle_dstl_submission)
Так вот, данный текст — это скорее байки по мотивам, в которых, с одной стороны, всё — правда, а с другой, обилие лирических отступлений и прочей отсебятины не позволяет рассматривать его как что-то наукоемкое, а скорее просто как полезное и увлекательное чтиво, цель которого показать, как может происходить процесс работы над задачами в дисциплине соревновательного машинного обучения. Кроме того, в тексте достаточно много лексикона, который специфичен для Kaggle и что-то я буду по ходу объяснять, а что-то оставлю так, например, вопрос про гусей раскрыт не будет.
Добыча данных (Data Mining)
Если вы много читали о Data Science, вероятно, вы познакомились с термином «добыча данных» или Data Mining. Но что в самом деле это значит? Изучив различные источники, я думаю, что лучше всего описать это следующим образом
Глоссарий
В своей практике я столкнулся с некоторыми вопросами в области анализа данных, которые, как мне кажется, важны для понимания. Ниже список легких определений терминов из сферы анализа данных. Имейте в виду, что заметить разницу между ними может быть сложно, поскольку все они очень похожи.
Data Wrangling: это преобразование сырых данных для последующей работы над ними. Обычно состоит из нескольких важных шагов, включая очистку и разбор в предопределенные структуры.
Data Munging: то же самое, что и «Data Wrangling» выше. Почему нужно два термина для одного процесса, я, возможно, никогда не узнаю…
Data Cleaning: важный шаг, который включает в себя обнаружение и исправление (или удаление) поврежденных, неточных или отсутствующих значений из набора данных.
Data Scraping: метод, в котором компьютерная программа считывает данные, поступающие из другой программы или сайта, например, Twitter.
Значимость в Data Science
Каждый хочет делать потрясающие прогностические модели и феерические визуализации. Однако часто забывают, что ничего не выйдет, пока вы не выполните работу «санитара». В недавней статье New York Times было обнаружено, что специалисты в области данных тратят примерно 50−80% рабочего времени на сбор и подготовку данных.










Об этой суровой реальности обязательно надо сообщать будущим специалистам в области данных. За прибыльным базовым окладом и званием «Самая сексуальная работа XXI века» молодые специалисты не видят реальной сути профессии.
Что почитать
Что такое Data Mining? (англ.) — хорошее обсуждение на Quora с различными определениями анализа данных.Что такое Data Wrangling? (англ.) — краткая информация о том, что из себя представляет data wrangling.«Работа санитара» — главный барьер на пути к инсайтам (англ.) — интересная статья, в которой подробно рассматриваются важность различных методов анализа данных в области науки о данных
Распространение сферического коня в вакууме по территории РФ
Привет от ODS. Мы откликнулись на идею tutu.ru поработать с их датасетом пассажиропотока РФ. И если в посте Milfgard огромная таблица выводов и научпоп, то мы хотим рассказать что под капотом.
Что, опять очередной пост про COVID-19? Да, но нет. Нам это было интересно именно с точки зрения математических методов и работы с интересным набором данных. Прежде, чем вы увидите под катом красивые картинки и графики, я обязан сказать несколько вещей:
- любое моделирование — это очень сложный процесс, внутри которого невероятное количество ЕСЛИ и ПРЕДПОЛОЖИМ. Мы о них расскажем.
- те, кто работал над этой статьей — не эпидемиологи или вирусологи. Мы просто группа любителей теории графов, практикующих методы моделирования сложных систем. Забавно, но именно в биоинформатике сейчас происходит наиболее существенный прогресс этой узкой области математики. Поэтому мы понимаем язык биологов, хоть и не умеем правильно обосновывать эпидемиологические модели и делать медицинские заключения.
- наша симуляция всего лишь распространение сферического коня в вакууме по территории РФ. Не стоит относиться к этому серьезно, но стоит задуматься об общей картине. Она определенно интересная.
- эта статья не существовала бы без датасета tutu.ru, за что им огромное спасибо.
Под катом — результаты нашего марш-броска на датасет.
Эксперименты с нейронными сетями на данных сейсморазведки
Сложность интерпретации данных сейсмической разведки связана с тем, что к каждой задаче необходимо искать индивидуальный подход, поскольку каждый набор таких данных уникален. Ручная обработка требует значительных трудозатрат, а результат часто содержит ошибки, связанные с человеческим фактором. Использование нейронных сетей для интерпретации может существенно сократить ручной труд, но уникальность данных накладывает ограничения на автоматизацию этой работы.
Данная статья описывает эксперимент по анализу применимости нейронных сетей для автоматизации выделения геологических слоев на 2D-изображениях на примере полностью размеченных данных из акватории Северного моря.
Рисунок 1. Проведение акваториальной сейсморазведки (источник)
Математика
- книгу Introduction to Mathematical Thinking Кейт Дэвлин;
- гайды How to Develop a Mindset for Math и Learning to Learn: Math Abstraction;
- тред на Quora How do math geniuses understand extremely hard math concepts so quickly?;
- публикацию Devlin’s Angle What is conceptual understanding?
Mathematics: the language of nature
Дополнительная теория и практика по математике
- по производным — урок Derivatives introduction от «Академии Хана»;
- по векторной алгебре — курс по линейной алгебре «Высшей школы экономики» от Coursera (седьмая неделя), уроки Vectors в «Академия Хана»;
- по матричной алгебре — курс по линейной алгебре «Высшей школы экономики» от Coursera (шестая неделя), уроки из раздела Matrices в «Академия Хана»;
- по тригонометрии — задания из раздела Trigonometry в «Академии Хана»;
- по теории вероятностей — курс по теории вероятности для начинающих от МФТИ на Coursera, задания из раздела Probability в «Академии Хана».
Задание со звездочкой. Чтобы еще больше прокачать знания по матричной алгебре, пройдите сложный курс Linear Algebra от MIT.
Визуализация данных
Визуализация данных может показаться чуть более понятной, чем другие темы. Тем не менее, в ней скрыто больше, чем кажется на первый взгляд. Давайте начнем с определения.
Распространено заблуждение, что привлекательный вид — наиболее важная часть визуализации
Это очень важно, но это не главная цель. Цель же в том, чтобы представить информацию, извлеченную из данных, наиболее доступным для восприятия способом
Согласно NeoMam Studios, цветные изображения на 80% увеличивают готовность читателя воспринимать информацию.
Распространенные типы визуализации
Посмотрим на некоторые часто используемые типы визуализации. Помните, что это далеко не полный список. Скорее это просто некоторые из наиболее распространенных двумерных визуализаций, которые мне встречались. Итак, пожалуйста:
Многомерные: это графики и диаграммы, оперирующие несколькими переменными; самая распространенная форма визуализации.Примеры: круговые диаграммы, гистограммы и диаграммы рассеяния.
Временные: используют время в качестве базовой линии для эффективного сообщения данных. Любая из них может быть мощным инструментом для представления изменений в течение определенного периода времени.Примеры: временные ряды, диаграммы Ганта и дуговые диаграммы.
Геопространственный: как можно предположить, геопространственные визуализации касаются местоположения. Они обычно используются для передачи информации о конкретной области или регионе.Примеры: карты распределения точек, карты пропорций символов и контурные карты.
Читать ещё: «Как визуализировать данные: типы графиков»
Ключевые моменты
Есть несколько ключевых моментов, которые относятся ко всем наиболее часто используемым типам визуализации данных. Ниже вы найдете список тех, что я считаю наиболее значимыми.






Информация: она должна быть точной и последовательной. Конечный результат не имеет значения, если данные неверны.
История: визуализация должна иметь смысл, отношение к проекту или обществу. Зачем делать визуализацию, если никто не захочет её видеть?
Польза: независимо от того, насколько сложна информация, с которой вы работаете, ваша задача — сделать ее краткой и понятной
Важно, чтобы данными могли пользоваться даже люди без технического бекграунда. На работе это особенно актуально
Привлекательность: наконец, визуализация должна быть в целом привлекательной
Она должна нравится и привлекать внимание. Для этого нужно принимать во внимание такие вещи, как баланс, цвет, согласованность, размер и многое другое
Значимость в Data Science
Навыки визуализации чрезвычайно полезны для специалистов в области данных, независимо от сферы. Возможность эффективно представлять данные в виде изображений, а не слов делает ваше сообщение более понятным и дает больше шансов произвести впечатление своей работой.
Что почитать
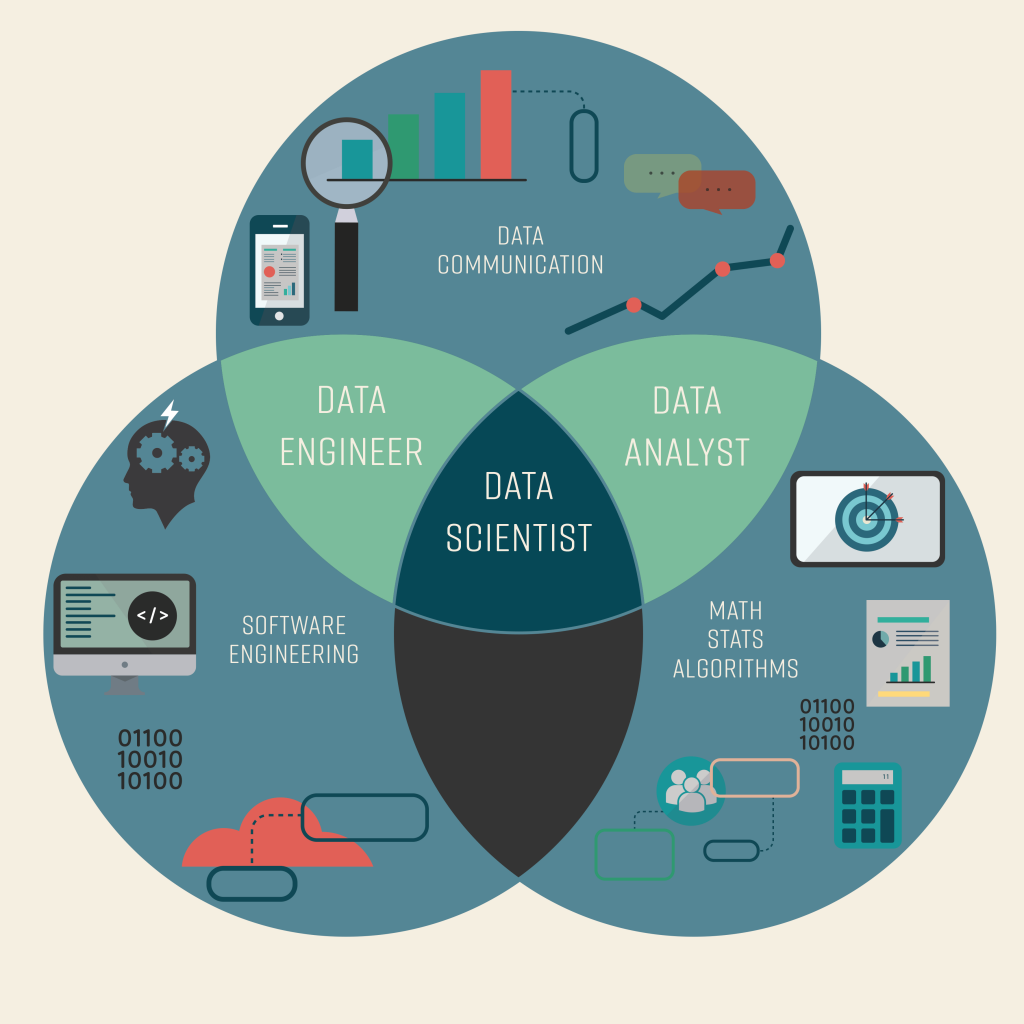
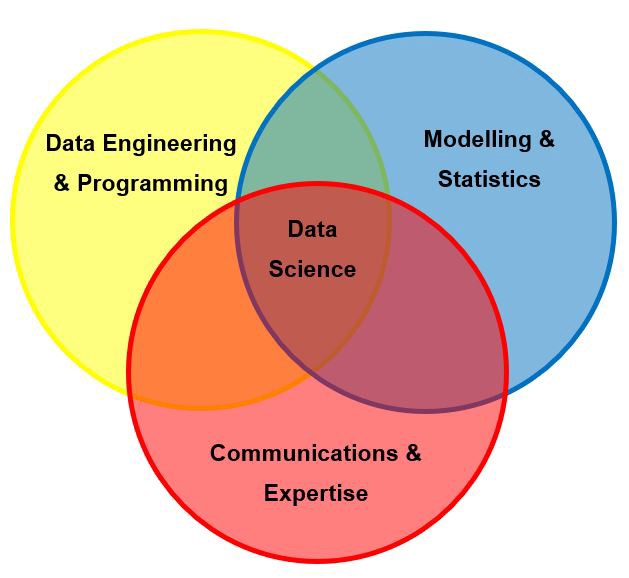
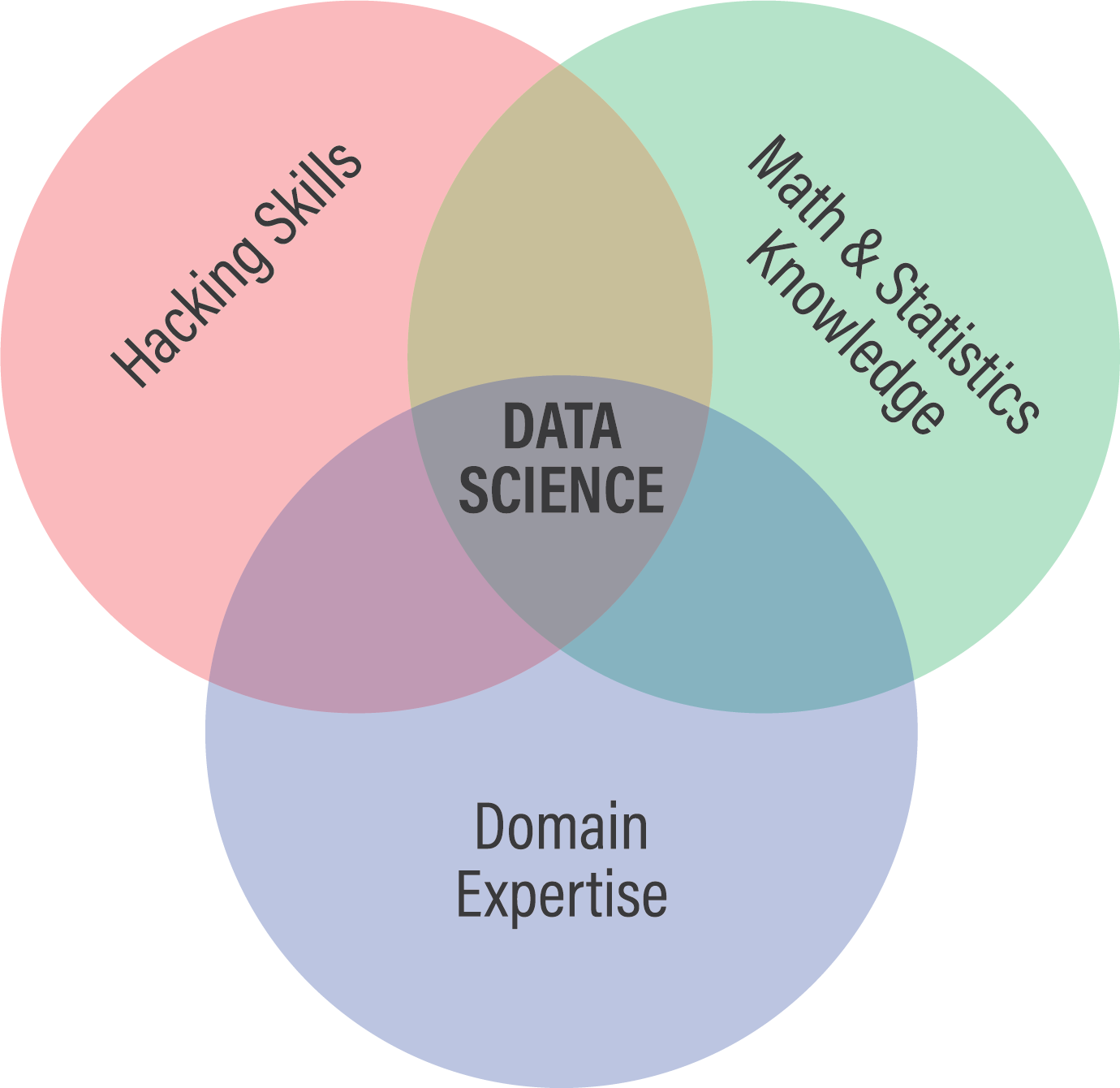
Из чего складывается хорошая визуализация данных (англ.) — отличная диаграмма Венна, объясняющая компоненты превосходной визуализации данных. Мы затрагивали некоторые из них выше, но я все же очень рекомендую посмотреть статью.Duke, введение в визуализацию (англ.): пройдитесь по всем типам визуализации данных на примере библиотек Университета Дьюка.Обсуждение визуализация данных на Quora (англ.): несколько хороших вопросов о визуализации данных для дополнительного чтения.
Коммуникация
Специалист по данным проводит много времени на встречах, отвечает на письма как и большинство людей в корпоративном мире, но тут умение общаться может быть ещё более важным навыком. Во время таких встреч и переписок нужно уметь объяснять принципы DS и ML таким образом, чтобы даже дилетант мог понять наши проблемы, а мы могли понять его потребности.
Коммуникация с людьми, не погруженными в ML
Вопреки распространённому мнению, важные инструменты специалиста по данным — Word, Outlook и PowerPoint. Со стороны кажется, что ML-разработка — плавание по волнам кода и данных, но значительную часть твоего дня составляет общение: с коллегами, с заказчиком, с менеджером проекта. В конечном счёте наша работа заключается в решении проблем, а не в построении моделей.
Хакатон PhotoHack Mobile
12–13 сентября, онлайн, беcплатно
tproger.ru
События и курсы на tproger.ru
Если общение внутри коллектива программистов может идти неформально, то с заказчиком необходимо выстраивать как можно более конструктивный диалог. Самое сложное тут — донести, что некоторые пожелания неосуществимы по объективным причинам, а не потому что ты не умеешь: недостаточно данных, задача неосуществима на данном процессе/железе/фреймворке, её невозможно решить физически (например отследить определённый объект, заваленный кучей других объектов).
Был случай, когда заказчик хотел модель прогнозирования перевозок на несколько лет вперед, хотя больше половины трафика приходилось на редкие перевозки, происходившие раз в год — проще попасть пальцем в небо, чем пытаться построить модель с такими исходными.
Коммуникация с командой
Каждое утро с командой мы собираемся, чтобы распределить задачи на день. У нас горизонтальная иерархия, но так органически вышло, что я — неформальный team-lead, поэтому ко мне часто приходят за советом или просят помочь. Нужно сразу оговориться, что процесс разработки у нас не всегда идёт по Agile-методикам: для DS, особенно на ранних этапах разработки, Agile может оказаться недостаточно гибок, поэтому мы выделяем некие реперные точки, на которых собираемся и сверяем часы, например раз в неделю.
Образование. Шесть шагов на пути к Data Scientist
Путь к этой профессии труден: невозможно овладеть всеми инструментами за месяц или даже год. Придётся постоянно учиться, делать маленькие шаги каждый день, ошибаться и пытаться вновь.
Шаг 1. Статистика, математика, линейная алгебра
Для серьезного понимания Data Science понадобится фундаментальный курс по теории вероятностей (математический анализ как необходимый инструмент в теории вероятностей), линейной алгебре и математической статистике.
Фундаментальные математические знания важны, чтобы анализировать результаты применения алгоритмов обработки данных. Сильные инженеры в машинном обучении без такого образования есть, но это скорее исключение.
Что почитать
«Элементы статистического обучения», Тревор Хасти, Роберт Тибширани и Джером Фридман — если после учебы в университете осталось много пробелов. Классические разделы машинного обучения представлены в терминах математической статистики со строгими математическими вычислениями.









«Глубокое обучение», Ян Гудфеллоу. Лучшая книга о математических принципах, лежащих в основе нейронных сетей.
«Нейронные сети и глубокое обучение», Майкл Нильсен. Для знакомства с основными принципами.
Полное руководство по математике и статистике для Data Science. Крутое и нескучное пошаговое руководство, которое поможет сориентироваться в математике и статистике.
Введение в статистику для Data Science поможет понять центральную предельную теорему. Оно охватывает генеральные совокупности, выборки и их распределение, содержит полезные видеоматериалы.
Полное руководство для начинающих по линейной алгебре для специалистов по анализу данных. Всё, что необходимо знать о линейной алгебре.
Линейная алгебра для Data Scientists. Интересная статья, знакомящая с основами линейной алгебры.
Шаг 2. Программирование
Большим преимуществом будет знакомство с основами программирования. Вы можете немного упростить себе задачу: начните изучать один язык и сосредоточьтесь на всех нюансах его синтаксиса.
При выборе языка обратите внимание на Python. Во-первых, он идеален для новичков, его синтаксис относительно прост. Во-вторых, Python многофункционален и востребован на рынке труда.
Что почитать
«Автоматизация рутинных задач с помощью Python: практическое руководство для начинающих». Практическое руководство для тех, кто учится с нуля. Достаточно прочесть главу «Манипулирование строками» и выполнить практические задания из нее.
Codecademy — здесь вы научитесь хорошему общему синтаксису.
Легкий способ выучить Python 3 — блестящий мануал, в котором объясняются основы.
Dataquest поможет освоить синтаксис.
The Python Tutorial — официальная документация.
После того, как изучите основы Python, познакомьтесь с основными библиотеками:
- Numpy : документация — руководство
- Scipy : документация — руководство
- Pandas : документация — руководство
Визуализация:
- Matplotlib : документация — руководство
- Seaborn : документация — руководство
Машинное обучение и глубокое обучение:
- SciKit-Learn: документация — руководство
- TensorFlow : документация — руководство
- Theano : документация — руководство
- Keras: документация — руководство
Обработка естественного языка:
NLTK — документация — руководство
Web scraping (Работа с web):
BeautifulSoup 4 — документация — руководство
Заключение:
Предполагая, что в момент «развилки» не все прочитали часть 5, поэтому поделю свои впечатления на две части.
Пройдена только Data Science Fundamentals:
Ну в целом достаточно, для того, чтобы в самых общих чертах понять, что такое Data Science. Подготовки никакой не требуется, ни мат. анализом ни статистикой, ни программированием можно не владеть, главное «шпрейхать по-аглицки».

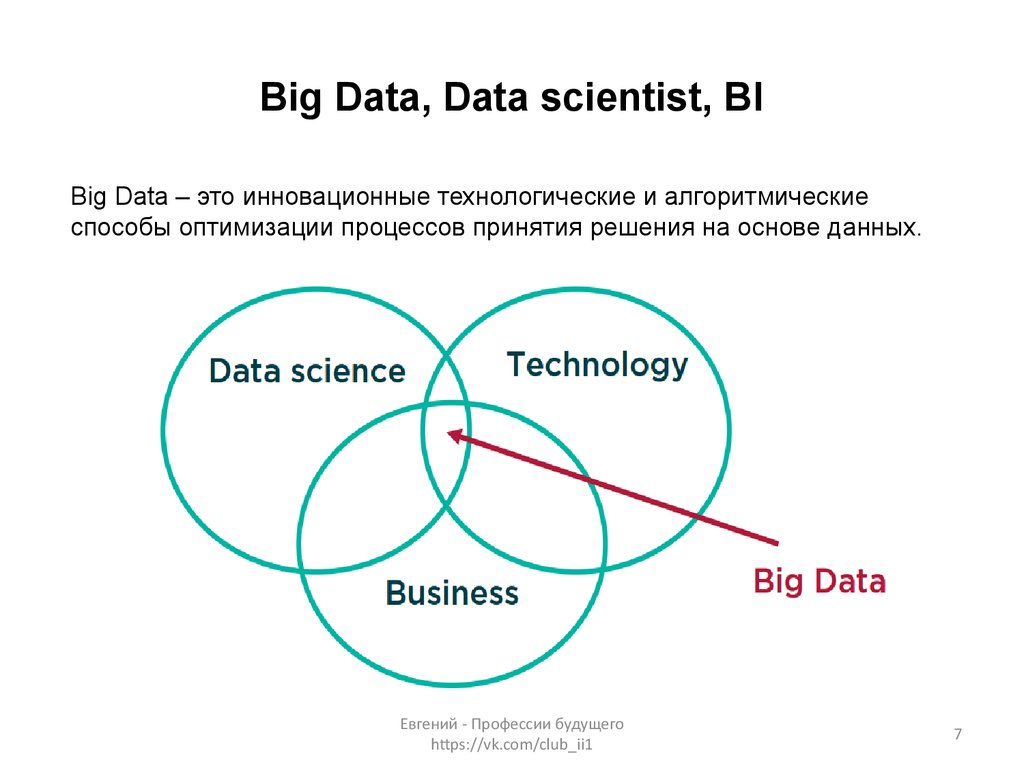






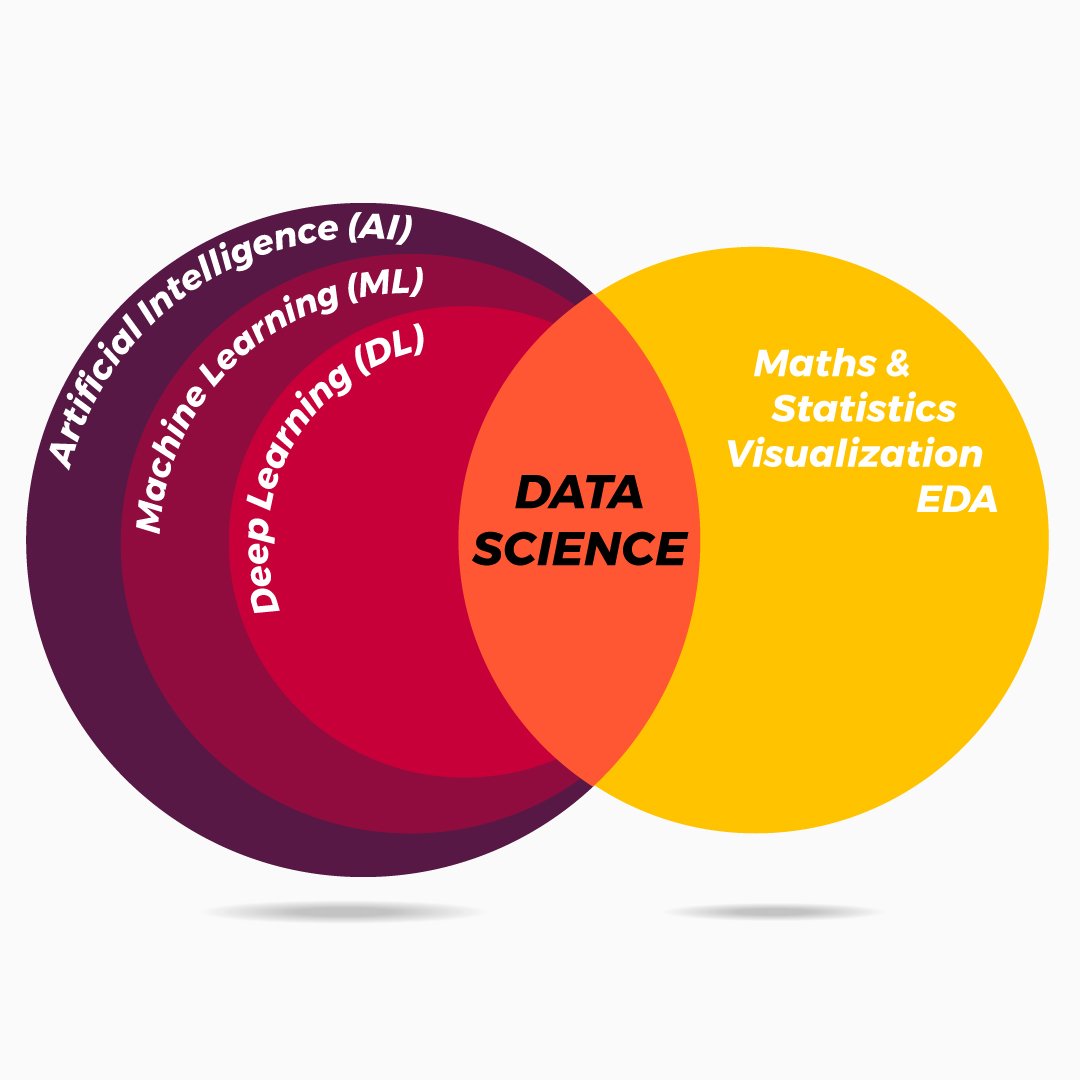
Думаю, итак очевидно, что за один день вы ничего толком не выучите и на 1500000 млн. рублей зарплату рассчитывать не стоит (я надеюсь вы еще не успели открыть «Хантер» и создать резюме?)
По идее этот курс должен развить у вас интерес к предмету и не напугать, в принципе разработчикам это удалось.
Пройдена Data Science Fundamentals + Data Science for Business + Statistics 101:
Рушит все надежды, потому что по-настоящему толковая практика так и не попалась, а курсы Data Science for Business + Statistics 101 выполнены несколько хуже по качеству чем Data Science Fundamentals, да еще и требуют установки триал версий программ от IBM.
Примеры в задачках не абы какие и оторваны во многом от реальности.
Наверное, пройдя все это, вы возможно, сдлаете для себя вывод — Data Science это ваше или нет, было ли вам до ужаса скучно или вы в восторге от колдовства над данными.
Подводя итог: Представленные курсы по пользе напоминают ситуацию, как если бы вас не умеющего водить машину, посадили бы за руль нормального автомобиля с автоматической коробкой передач, показали бы вам где газ и тормоз, как заводить машину и заливать бензин, как включить фары и дворники, ну и в конце под контролем дали бы проехать пару километров по проселочной дороге. С одной стороны водителем вы точно после этого не станете, с другой стороны если вы будете спасаться от маньяка с бензопилой возможно эти знания сохранят вашу жизнь. Ровно также и с этими курсами.
В любом случае, всем кто потратил время на обучение по программе от Cognitive class, советую не останавливаться на достигнутом. В конце концов даже у них там еще много чего интересного (Big Data, Hadoop, Scala и т.п.)
Спасибо за внимание, всем удачной недели!
UPD: Последующие статьи цикла ниже под спойлером:







