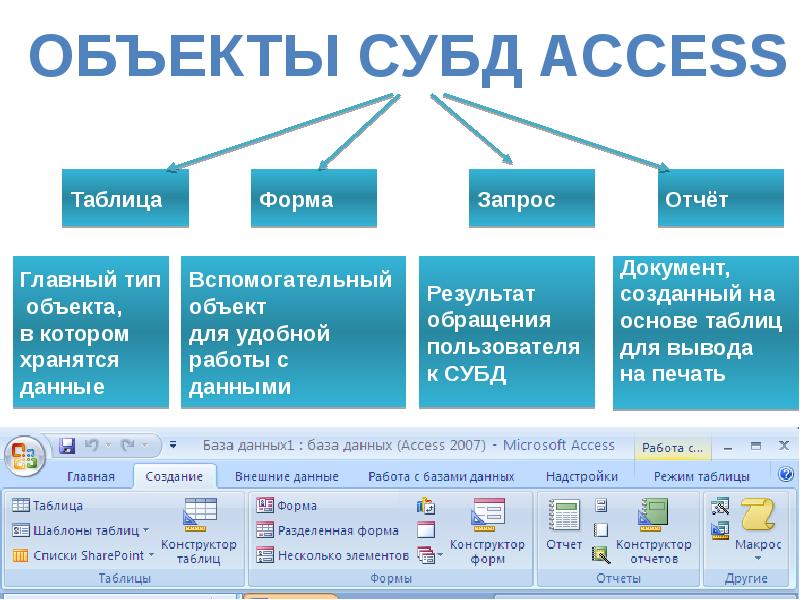
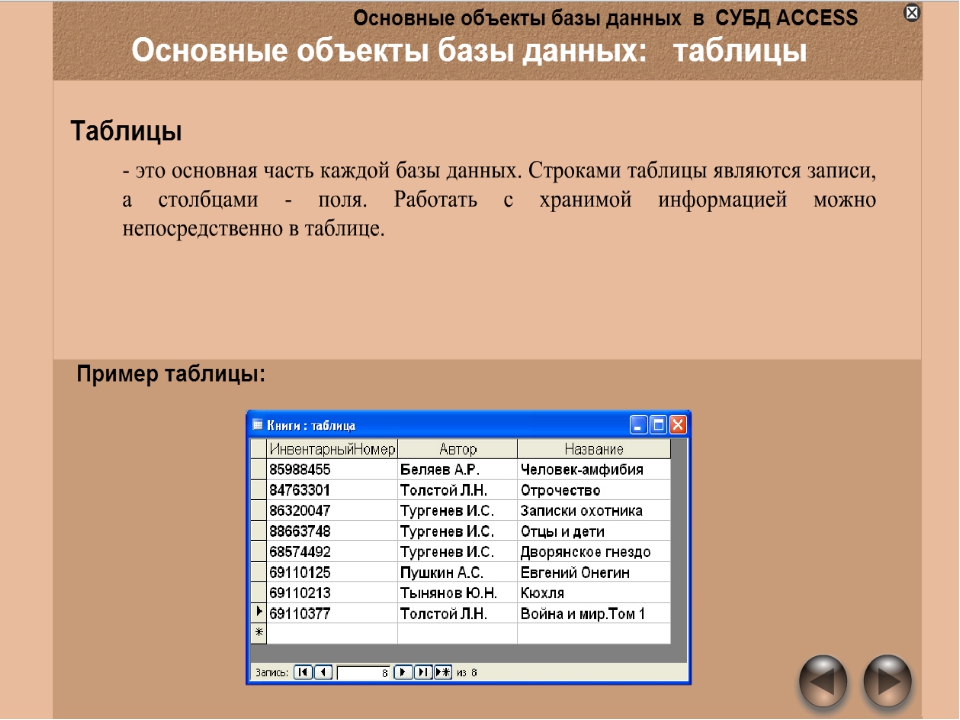
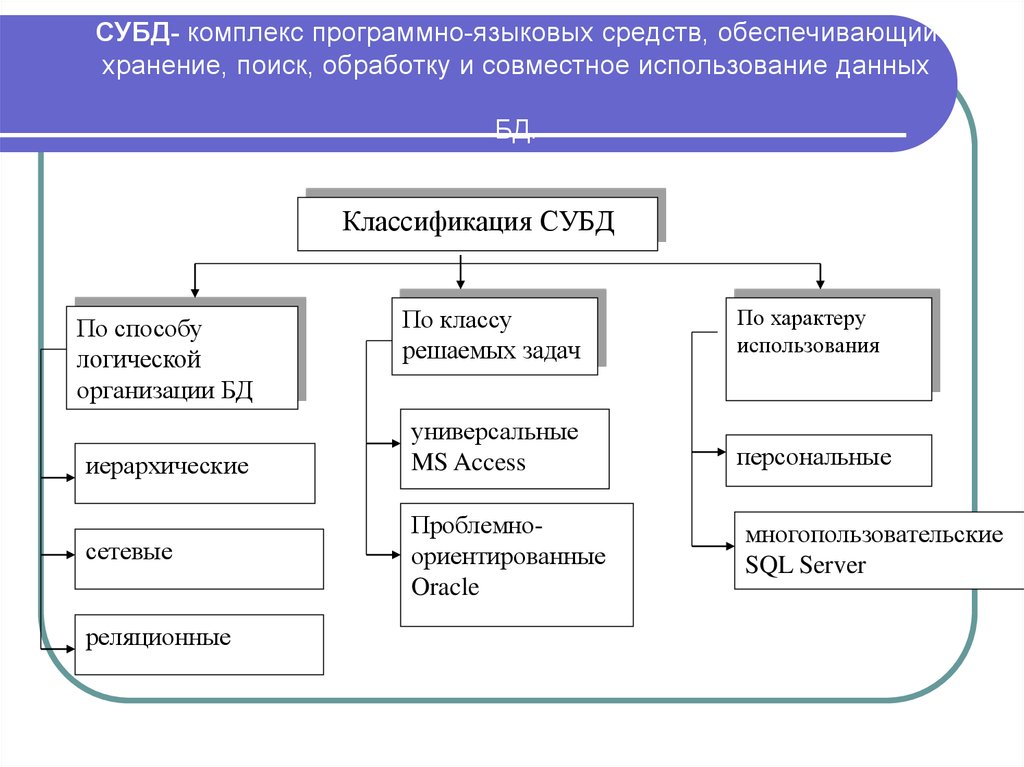
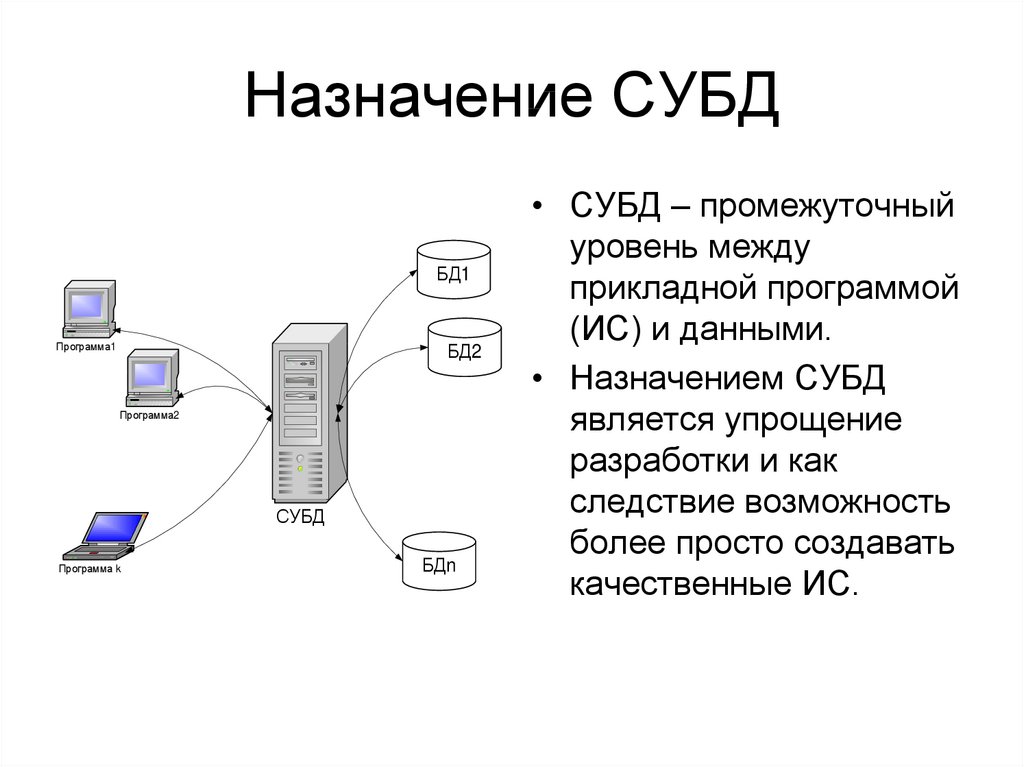
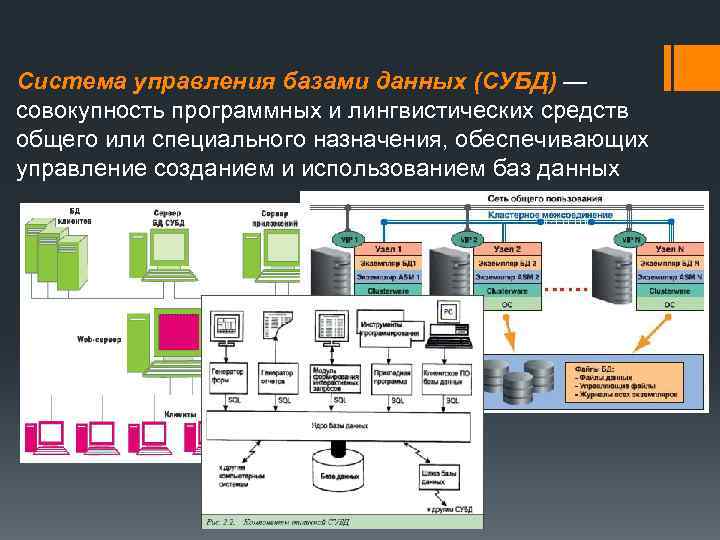
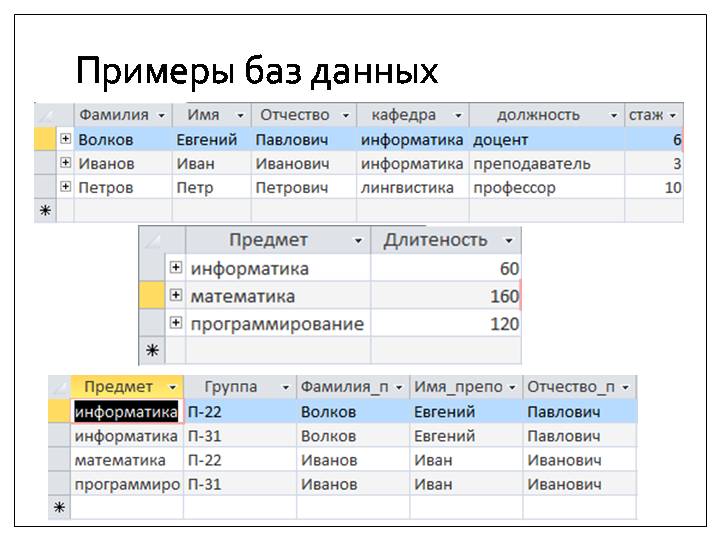
СУБД
Система управления базами данных — это термин, который не нужно расшифровывать. Она представляет собой встраивыемый модуль или полноценную программу, которая способна работать с данными и вносить изменения в базы.
Существует две модели СУБД — реляционная и безсхемная. О том, что такое реляционные базы данных, уже рассказано выше. Безсхемные СУБД основанные на принципах неструктурированного подхода избавляют программиста от проблем реляционной модели, в число которых входит низкая производительность и трудное масштабирование данных в горизонтальном формате.
Неструктурированные базы данных (NoSQL) создают структуру по ходу и убирают необходимость в создании жёстко определённых связей между данными. Здесь можно экспериментировать с разными способами доступа к тем или иным видам данных.
К реляционным базам данных относятся:
- SQLite;
- MySQL;
- PostgreSQL.
Из них наиболее распространённой является база данных MySQL, но остальные тоже имеют популярность и с ними можно столкнуться.
Принцип работы таких систем заключается в слежении за строгой структурой данных, которая представлена в виде комплекса таблиц. В свою очередь внутри таблицы есть ячейки и поля, которыми также управляет MySQL.
По принципу NoSQL работает база данных MongoDB. Они хранят все данные как единое целое в одной базе. При этом данные могут быть и одиночным объектом, но в то же время любой запрос не останется без ответа.
Каждая NoSQL имеет собственную систему запросов, что требует дополнительного изучения данной системы.
Нормализация баз данных
Рассмотрим процесс нормализации базы данных на
примере базы данных BIBLIO.MDB. Вообще говоря, все
данные о книгах, авторах и издательствах можно
разместить в одной таблице, названной, например,
BIBLIOS. Структура этой таблицы показана на рис. 1.11. В
принципе, можно работать и с такой таблицей. С
другой стороны понятно, что такая структура
данных является неэффективной. В таблице BIBLIOS
будет достаточно много повторяющихся данных,
например сведения об издательстве или авторе
будут повторяться для каждой опубликованной
книги. Такая организация данных приведет к
следующим проблемам, с которыми столкнется
конечный пользователь вашей программы:
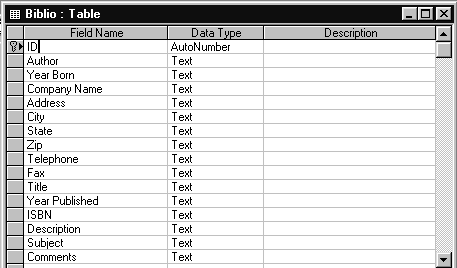 Рис.1.11. Структура таблицы BIBLIOS.
Рис.1.11. Структура таблицы BIBLIOS.Если, при проектировании приложения для работы
с базами данных, вы организуете свои данные таким
нерациональным образом, то в дальнейшем вам,
скорее всего, больше не поручат решение
аналогичных задач.
Чтобы избежать всех этих проблем, надо
стремиться максимально уменьшить количество
повторяющейся информации. Процесс уменьшения
избыточности информации в базе данных
посредством разделения ее на несколько
связанных друг с другом таблиц и называется
нормализацией данных.
Вообще говоря, существует строгая теория
нормализации данных, в рамках которой
разработаны алгоритмы уменьшения избыточности
информации, определены несколько уровней
нормализации и установлены критерии,
определяющие соответствие данных определенному
уровню нормализации. Знакомство с теорией
нормализации данных выходит за рамки этих уроков
и тем читателям, которым интересно побольше
узнать об этом, можно посоветовать обратиться к
специальной литературе.
Для того, чтобы построить достаточно
эффективную структуру данных, достаточно
придерживаться нескольких простых правил:
1. Определите таблицы таким образом, чтобы
записи в каждой таблице описывали объекты одного
и того же типа. В нашем случае библиографические
данные можно разместить в трех таблицах:
- PUBLISHERS — содержит информацию об издательствах;
- AUTHORS — содержит информацию об авторах книг;
- TITLES — содержит информацию об изданных книгах.
2. Если в вашей таблице появляются поля,
содержащие аналогичные данные, разделите
таблицу.
3. Не запоминайте в таблице данных, которые
могут быть вычислены при помощи данных из других
таблиц.
4. Используйте вспомогательные таблицы.
Например, если в вашей таблице есть поле Страна,
то может быть стоит ввести вспомогательную
таблицу Country, которая будет содержать
соответствующие записи (Россия, Украина, США и
т.п.). Этот прием также поможет уменьшить
количество ошибок при вводе данных, допускаемых
пользователями.
Сравнение SQL и NoSQL
- Если SQL-системы основаны исключительно на строгом представлении данных, то NoSQL-системы предоставляют свободу и способны работать с любым типом данных.
- SQL-системы стандартизированы, за счёт чего запросы формируются с использованием языка SQL. В то же время NoSQL-системы базируются на специфической для каждой из них технологии, что является недостатком.
- Масштабируемость. Обе СУБД способны обеспечить вертикальное масштабирование, то есть увеличить объём системных ресурсов на обработку данных. При этом NoSQL, будучи более новой разновидностью баз данных, позволяет применять простые методы горизонтального масштабирования.
- В плане надёжности SQL обладает уверенным лидерством.
- У SQL-баз есть качественная техническая поддержка за счёт их продолжительной истории, в то время как NoSQL-системы весьма молоды и и решить какую-либо проблему сложнее.
- Хранение данных и доступ к их структурам в рамках реляционных систем лучше всего происходит в SQL-системах.
Таким образом, хоть NoSQL и является стремительно развивающейся разновидностью систем управления базами данных, однако на данном этапе рекомендуется остановить свой выбор на SQL.
Надёжность SQL-систем, особенно MySQL, подтверждается временем и массовостью. Сегодня любой уважающий себя ресурс использует для хранения данных именно систему MySQL.

@ivashkevich
04.04.2018 в 19:25
22143
+177
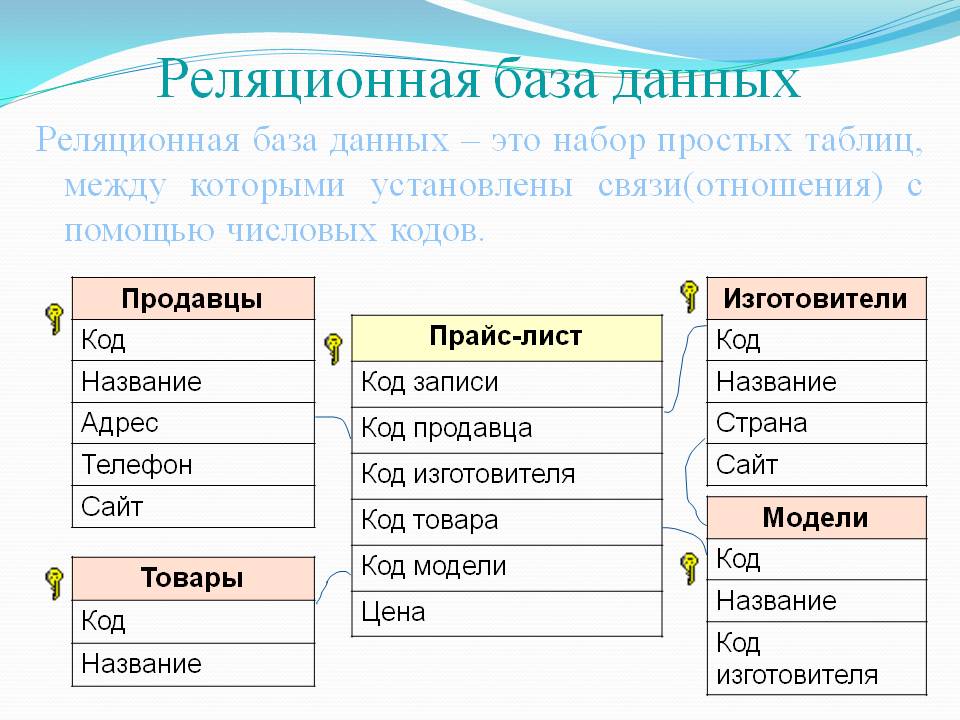
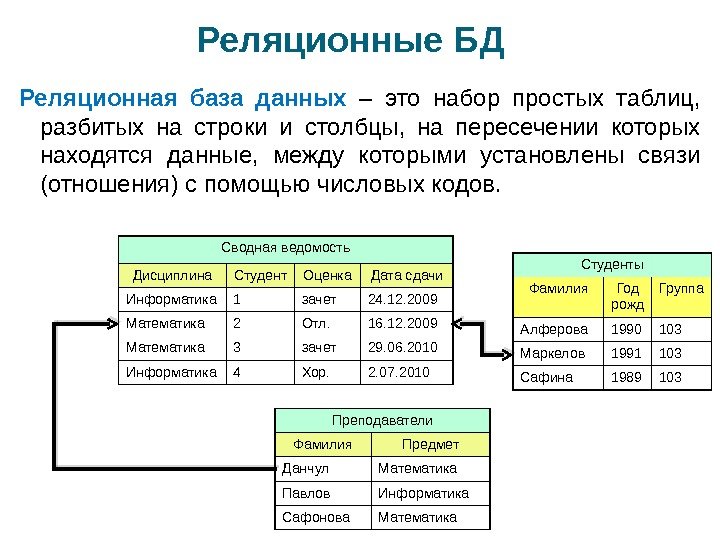
Некоторые термины реляционных баз данных
- Отношение (Relation) — информация об объектах одного типа, например, о клиентах, заказах, сотрудниках. В реляционных базах данных отношение обычно хранится в виде таблицы.
- Атрибут (Attribute) — определенная часть информации о некотором объекте — например, адрес клиента или зарплата сотрудника. Атрибут обычно хранится в виде столбца или поля таблицы.
- Связь (Relatioship) — способ, которым связана информация в одной таблице с информацией в другой таблице. Например, у клиентов с заказами тип связи — «один-ко-многим», так как один клиент может разместить много заказов, но любой заказ соотносится только с одним клиентом.
- Объединение (Join) — процесс объединения таблиц или запросов на основе совпадающих значений определенных атрибутов. Например, информация о клиентах может быть объединена с информацией о заказах по коду данного клиента.
Таблица 1.1
| Название | Описание |
|---|---|
| Text | Строки алфавитно-цифровых символов. Например, адрес, номер телефона, почтовый индекс и т.п. Текстовое поле может содержать от 0 до 255 символов. |
| Memo | Длинные строки. Например, комментарии. Максимальный размер ограничен 1.2 Гбайт. |
| Yes/No | Yes/No, True/False, On/Off, 0 или 1. |
| Byte | Целые числа в диапазоне от 0 до 255. |
| Integer | Целые числа в диапазоне от -32768 до +32767. |
| Long | Целые числа в диапазоне от -2147483648 до 2147483647. |
| Single | Вещественные числа в диапазоне от -3.4? 1038 до 3.4? 1038. |
| Double | Вещественные числа в диапазоне от -1.8? 10308 до 1.8? 10308. |
| Date/Time | Дата и время. |
| Currency | Используется для обозначения денежных сумм. Запоминаются 11 знаков слева от десятичной точки и 4 знака справа от десятичной точки. |
| Counter | Длинные целые с автоматическим приращением. |
| OLE | OLE-объекты, созданные в других программах с использованием протокола OLE. Размер ограничен 1.2 Гбайт. |
| Binary | Любой двоичный объект размером до 1.2 Гбайт. Этот тип обычно используется для хранения рисунков и двоичных файлов. |
Таблица PUBLISHERS (Издатели) содержит информацию об
издательствах (имя компании, ее адрес, телефон,
факс и др.). На рис. 1.3 и 1.4 показаны структура
таблицы PUBLISHERS и ее содержимое в табличном виде.
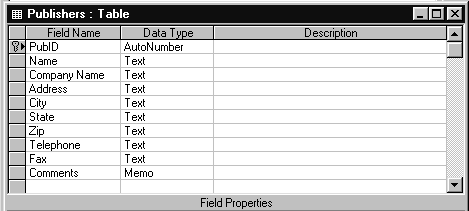 Рис.1.3. Структура таблицы PUBLISHERS
Рис.1.3. Структура таблицы PUBLISHERS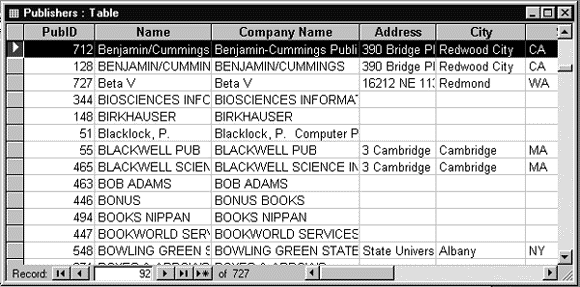
Рис.1.4. Содержимое таблицы PUBLISHERS
Таблица AUTHORS (Авторы) содержит информацию о
авторах — ФИО и год рождения. Структура этой
таблицы и ее содержимое показаны на рис.1.5 и 1.6
соответственно.
 Рис.1.5. Структура таблицы AUTHORS
Рис.1.5. Структура таблицы AUTHORS 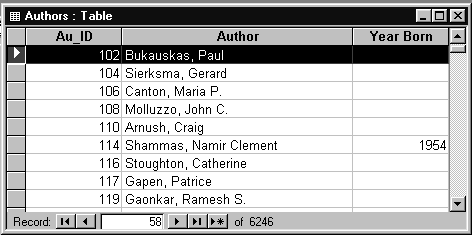 Рис.1.6. Содержимое таблицы AUTHORS
Рис.1.6. Содержимое таблицы AUTHORS Таблица TITLES (Заголовки) содержит данные о самих
книгах — название книги, год издания, код ISBN,
издатель, краткое описание и др. Структура
таблицы TITLES и ее содержимое показаны на рис.1.7 и 1.8
соответственно.
 Рис.1.7. Структура таблицы TITLES
Рис.1.7. Структура таблицы TITLES  Рис.1.8. Содержимое таблицы TITLES
Рис.1.8. Содержимое таблицы TITLES Из рис.1.2 видно, что в базе данных BIBLIO.MDB
присутствует еще и таблица TITLE AUTHOR. На первый
взгляд непонятно зачем она нужна. Ведь в базе
данных есть таблица TITLES с заголовками книг и
таблица AUTHORS с данными об авторах. Однако все же
эта таблица нужна и для чего она так необходима
станет понятно, когда в дальнейшем будем
рассматривать отношения между таблицами.
Отношение много-ко-многим
При отношении между двумя таблицами
много-ко-многим каждая запись в одной таблице
связана с несколькими записями в другой таблице
и наоборот. Иллюстрацией такого отношения может
служить отношение между таблицами PUBLISHERS и AUTHORS. С
одной стороны, каждое издательство может
публиковать книги разных авторов и с другой
стороны — каждый автор может публиковаться в
разных издательствах.
Для удобства работы с таблицами, имеющими
отношение много-ко-многим, обычно в базу данных
добавляют еще одну таблицу, которая находится в
отношении один-ко-многим и много-к-одному к
соответствующим таблицам. В случае базы данных
BIBLIO.MDB такой таблицей является TITLE AUTHOR.
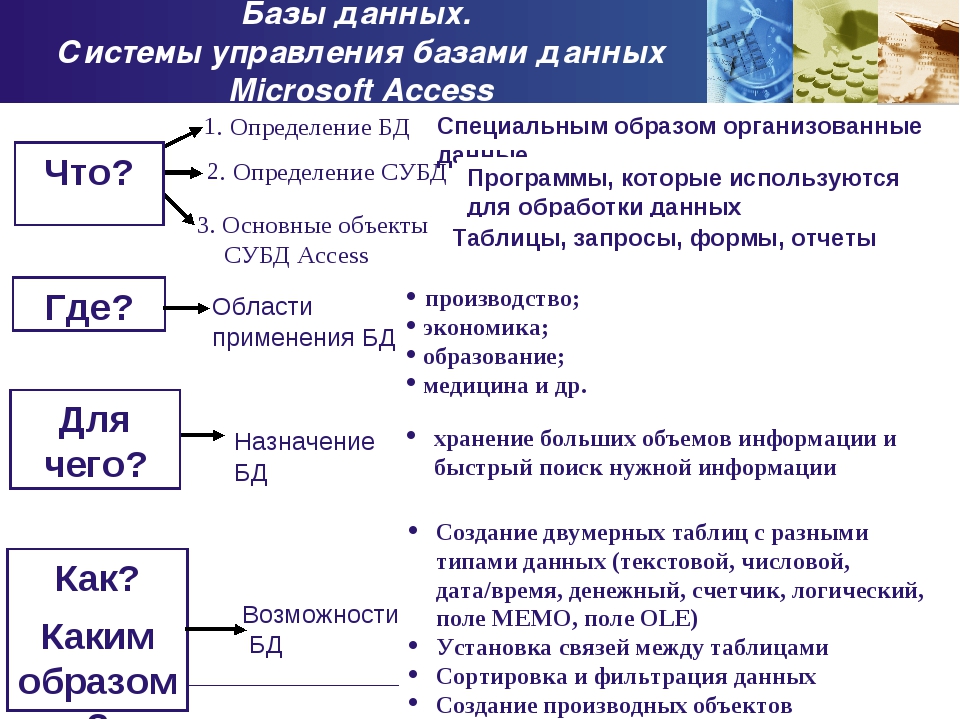
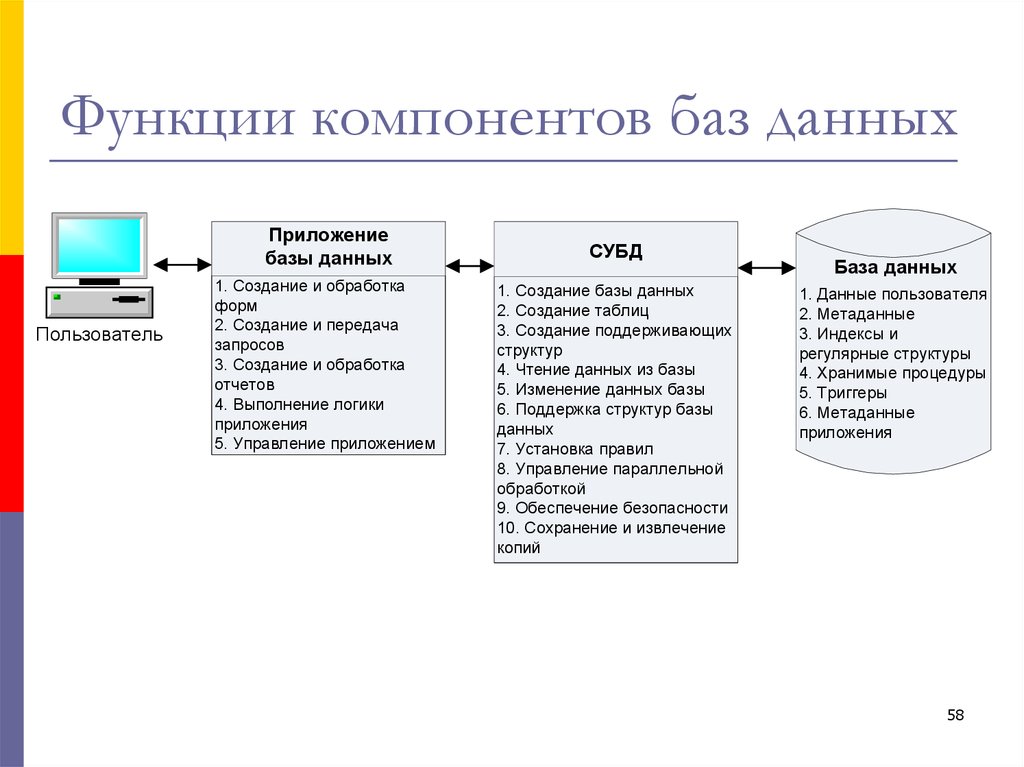
Возможности СУБД
- Определение данных (Data definition) — вы можете определить, какая именно информация будет храниться в вашей базе данных, задать структуру данных и их тип (например, количество цифр или символов), а также указать, как эти данные связаны между собой. В некоторых случаях вы можете также задать форматы и критерии проверки данных.
- Обработка данных (Data manipulation) ~ данные можно обрабатывать самыми различными способами. Можно выбирать любые поля, фильтровать и сортировать данные. Можно объединять данные с другой связанной с ними информацией и вычислять итоговые значения.
- Управление данными (Data control) — вы можете указать, кому
разрешено знакомиться с данными, корректировать их или добавлять новую информацию. Можно также определить правила коллективного пользования данными.
Причины целесообразности перехода к использованию СУБД:
- Причина 1. У вас имеется слишком много отдельных файлов или какие-то из файлов содержат большой объем информации, что затрудняет работу с данными. К тому же работать с такими объемами данных могут вам не позволить ограничения по памяти программы или системы.
- Причина 2. Вы используете данные различными способами: для информации по конкретным сделкам (например, счета-фактуры), для итогового анализа (например, по ежеквартальным объемам продаж), или вы используете эти данные для прогнозирования тех или иных ситуаций. Поэтому вы должны быть в состоянии рассматривать эти данные с разных сторон, что существенно затрудняет создание удовлетворяющей все ваши нужды единой структуры представления данных.
- Причина 3. Имеется необходимость в использовании одних и тех же данных разными специалистами. Например, их вводом, обновлением и анализом занимаются самые разные люди. Если в электронную таблицу или документ вносить изменения может только один человек, то с базой данных могут взаимодействовать в одно и то же время несколько пользователей, модифицируя содержимое одной и той же таблицы. При этом в базах данных гарантируется, что пользователи всегда работают с последними модификациями данных.
- Причина 4. Вы должны обеспечить защиту данных от несанкционированного доступа, контролировать их значения и поддерживать целостность базы данных — ведь к данным имеют доступ много пользователей, эти данные используются в работе вашей фирмы и взаимосвязаны (например, клиенты и заказы).
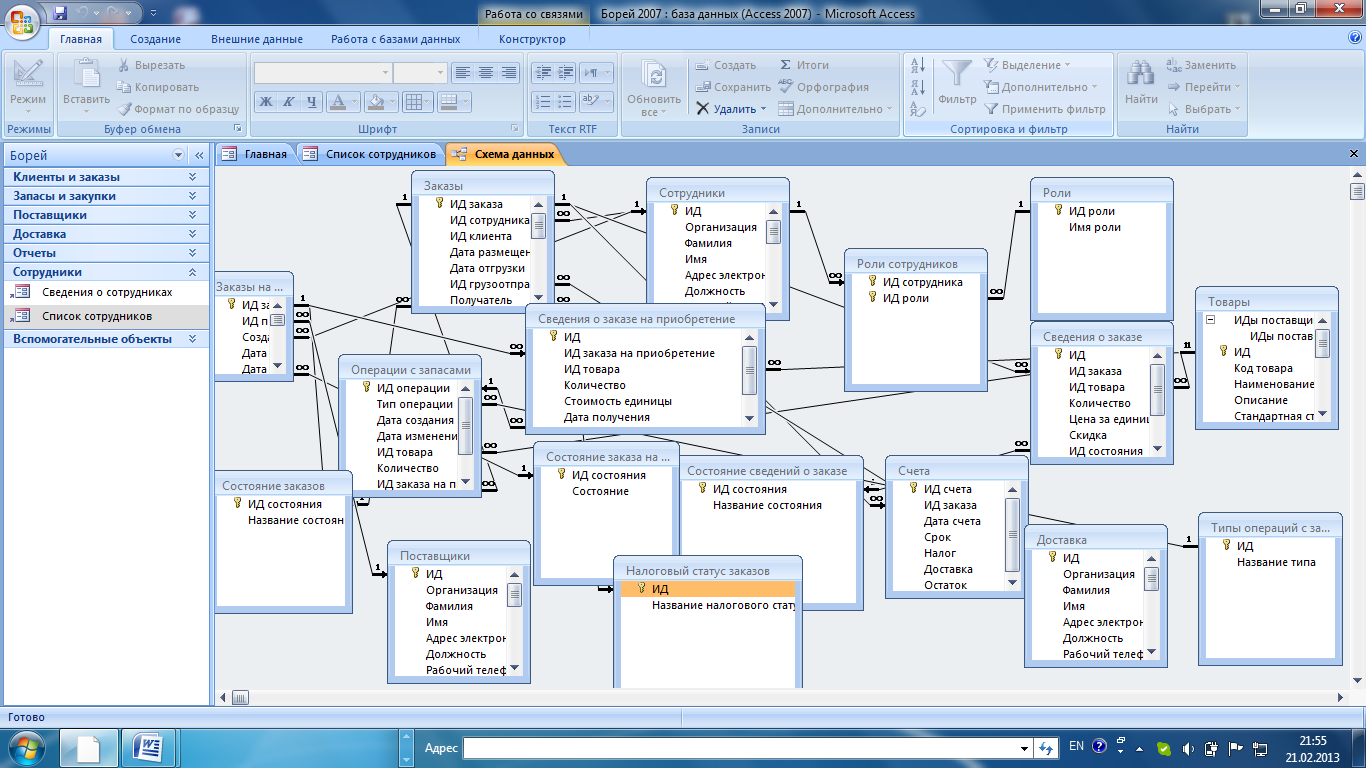
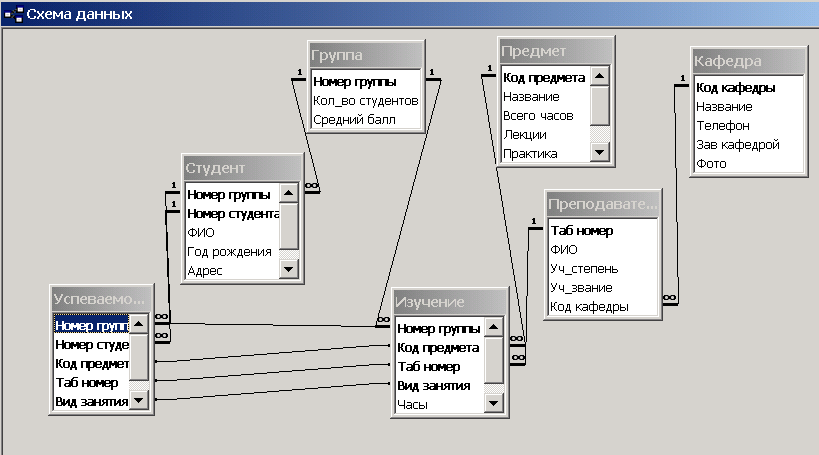
Отношения между таблицами
Отношения между таблицами устанавливают связь
между данными находящимися в разных таблицах
базы данных.
Отношения между таблицами определяются
отношением между группами объектов
соответствующего типа. Например, один автор
может написать несколько книг и издать их в
разных издательствах. Или издательство может
опубликовать несколько книг разных авторов.
Таким образом, между авторами и названиями книг
существует отношение один-ко-многим, а между
издательствами и авторами существует отношение
много-ко-многим.
Отношения между таблицами базы данных BIBLIO.MDB
показаны на рис.1.9.
 Рис.1.9. Отношения между таблицами базы данных BIBLIO.MDB.
Рис.1.9. Отношения между таблицами базы данных BIBLIO.MDB.Отношение один-к-одному
Если между двумя таблицами существует
отношение один-к-одному, то это означает, что
каждая запись в одной таблице соответствует
только одной записи в другой таблице.
Примером такого отношения может служить
отношение между таблицами. Таблица AUTHORS (Авторы)
рассмотрена выше (рис. 1.5 и 1.6) и содержит краткую
информацию о авторах (ФИО и год рождения). Таблица
PERSON (Личность) содержит персональную информацию
о авторах (домашний адрес, телефон, образование и
др.) Структура таблицы PERSON показана на рис.1.10.
Следует отметить, что в базе данных BIBLIO.MDB никакой
таблицы PERSON нет и мы упоминаем о ней только как о
иллюстрации отношения между таблицами —
один-к-одному.
 Рис.1.10. Структура таблицы PERSON
Рис.1.10. Структура таблицы PERSONМежду таблицами AUTHORS и PERSON существует отношение
один-к-одному, так как одна запись,
идентифицирующая автора, однозначно
соответствует только одной записи в таблице PERSON,
содержащей персональные данные об авторе.
Связь между таблицами определяется с помощью
совпадающих полей: Au_ID в таблице AUTHORS и в таблице
PERSON.
Базы данных по РФ
Финансовые показатели
Что здесь есть: официальная статистика Центробанка РФ. В базе собраны макроэкономические показатели, показатели банковского сектора, финансового рынка, национальной платежной системы и операций денежно-кредитной политики.
Язык: русский.
Форматы файлов: DOC, XLS, PDF, ARJ. Формат архива ARJ можно открыть архиваторами для ZIP.




Кому пригодится: инвест-банкирам, стратегам, консультантам, GR-специалистам.
Лайфхаки: данные до 2008–2012 годов лежат в Архиве.
Показатели развитости индустрий в стране
Что здесь есть: исследования, аналитика и прогнозы по разным темам (финансы, социальное развитие, предпринимательство, IT и телеком, строительство, рынок труда и HR, бренд и реклама, PR и GR-проекты).
Язык: русский.
Форматы файлов: DOC, XLS, PDF.
Кому пригодится: маркетологам, рекламщикам, GR- и PR-специалистам, бренд-менеджерам, продакт-менеджерам, проджект-менеджерам, HR-специалистам, инвест-банкирам, стратегам и консультантам.
Лайфхаки: часть данных находится в открытом доступе. Можно бесплатно подписаться на рассылку и получать новые исследования. Есть возможность заказать свое исследование.
Что здесь есть: исследования преимущественно по техническим тематикам. В базе можно найти данные об интернете вещей, цифровизации, блокчейне, искусственном интеллекте, телекоме, а также рекламе, онлайн-играх, образовании и многом другом.
Языки: русский, английский.
Форматы файлов: DOC, XLS, PDF.
Кому пригодится: Продакт-менеджерам, проджект-менеджерам, стратегам и консультантам.
Лайфхаки: после регистрации доступна краткая версия исследований. За полную нужно заплатить.
Социологические исследования
Что здесь есть: социологические исследования, рейтинги политиков, индексы одобрения государственных и общественных институтов и другие опросы общественного мнения.
Язык: русский.
Форматы файлов: DOC, XLS, PDF.
Кому пригодится: маркетологам, рекламщикам, GR- и PR-специалистам, бренд-менеджерам, HR-специалистам.
Лайфхаки: можно заказать свое исследование.
Что здесь есть: результаты опросов общественного мнениях на разные темы начиная с 1988 года.
Языки: русский, английский.
Форматы файлов: DOC, XLS, PDF.
Кому пригодится: GR- и PR-специалистам.
Лайфхаки: можно оформить бесплатную подписку и получать новые исследования.
Что здесь есть: социологические и маркетинговые данные, собранные в результате опросов разных групп населения. Исследования и аналитика по темам: образ жизни, ценности, работа и дом, экономика, СМИ и интернет.





Язык: русский.
Форматы файлов: DOC, XLS, PDF.
Кому пригодится: маркетологам, рекламщикам, GR- и PR-специалистам, бренд-менеджерам, продакт-менеджерам, проджект-менеджерам, HR-специалистам.
Лайфхаки: можно заказать исследование.
Уровни работы с данными
- Слой доступа к данным, который удобно использовать из языков программирования;
- Слой хранения. Это отдельный слой, потому что обычно хранить данные удобно другими способами, чем использовать: эффективно по памяти, выравнивать, складывать на диск. Это к вопросу о schemaless: схема, которая удобна для хранения, не удобна для доступа.
- «Железо» — слой, где лежат данные, причем там они организованы еще третьим способом, потому что дисками управляет операционная система, и общаются они только через драйвер. В этот уровень мы не будем сильно вникать.
Для слоя доступатребования
- Универсальность, чтобы возможно было с помощью любой технологии запрашивать данные.
- Оптимальность этого запроса. Метод доступа должен быть такой, чтобы хорошо и удобно доставать данные из базы.
- Параллелизм, потому что сейчас все масштабируются, разные серверы одновременно обращаются к базу за одними и теми же данными. Надо сделать так, чтобы максимально использовать преимущества параллелизма и быстрее обрабатывать данные таким способом.
Для слоя храненияизначального параллелизманадежноДля «железа»доступ к даннымSQLSQL не нуженSQL опять возвращаетсяВся математика оптимизации завязана вокруг реляционной алгебрыВ слое храненияДля «железа»
Что такое база данных
Можно с большой степенью достоверности
утверждать, что большинство приложений, которые
предназначены для выполнения хотя бы
какой-нибудь полезной работы, тем или иным
образом используют структурированную
информацию или, другими словами, упорядоченные
данные. Такими данными могут быть, например,
списки заказов на тот или иной товар, списки
предъявленных и оплаченных счетов или список
телефонных номеров ваших знакомых. Обычное
расписание движения автобусов в вашем городе —
это тоже пример упорядоченных данных.
При компьютерной обработке информации
упорядоченные каким либо образом данные принято
хранить в базах данных — особых файлах,
использование которых вместе со специальными
программными средствами позволяет пользователю
как просматривать необходимую информацию, так и,
по мере необходимости, манипулировать ею,
например, добавлять, изменять, копировать,
удалять, сортировать и т.д.
Таким образом, дать простое определение базы
данных можно следующим образом. База данных — это
набор информации, организованной тем, или иным
способом. Пожалуй, одним из самых банальных
примеров баз данных может быть записная книжка с
телефонами ваших знакомых. Наверное, у вас есть
сейчас или когда-либо была эта полезная вещь.
Этот список фамилий владельцев телефонов и их
телефонных номеров, представленный в вашей
записной книжке в алфавитном порядке,
представляет собой, вообще говоря,
проиндексированную базу данных. Использование
индекса — в данном случае фамилии (или имени)
позволяет вам достаточно быстро отыскать
требуемый номер телефона.
MVCC — MultiVersion Concurrency Control
zr1(y)yyy
Как это работает?
- Когда мы пошли исполнять транзакцию t1, имеется чтение x, т.е. самой изначальной версии.
- Дальше в t2 мы начинаем записывать y другой версии, потому что он был изменен.
- В транзакции t1, которая началась раньше, чем мы начали записывать y, до сих пор видно предыдущую версию y, поскольку t2 еще не завершилась, и мы и спокойно начать с ней работать.
- Поскольку транзакция t1 заканчивается раньше, чем w2(y2), то произойдет перечитываниеy,и после этого в транзакции t 2 выполнится нормальная работа, а другая транзакция просто нормально завершится.
yw2yt1xy
- В MySQL он внутри InnoDB,
- В PostgreSQL это отдельная директория, которая наконец в версии 10 стала называться WAL вместо PGX-Log;
- В Oracle это называется Redo Log;
- В DB2 — WAL.
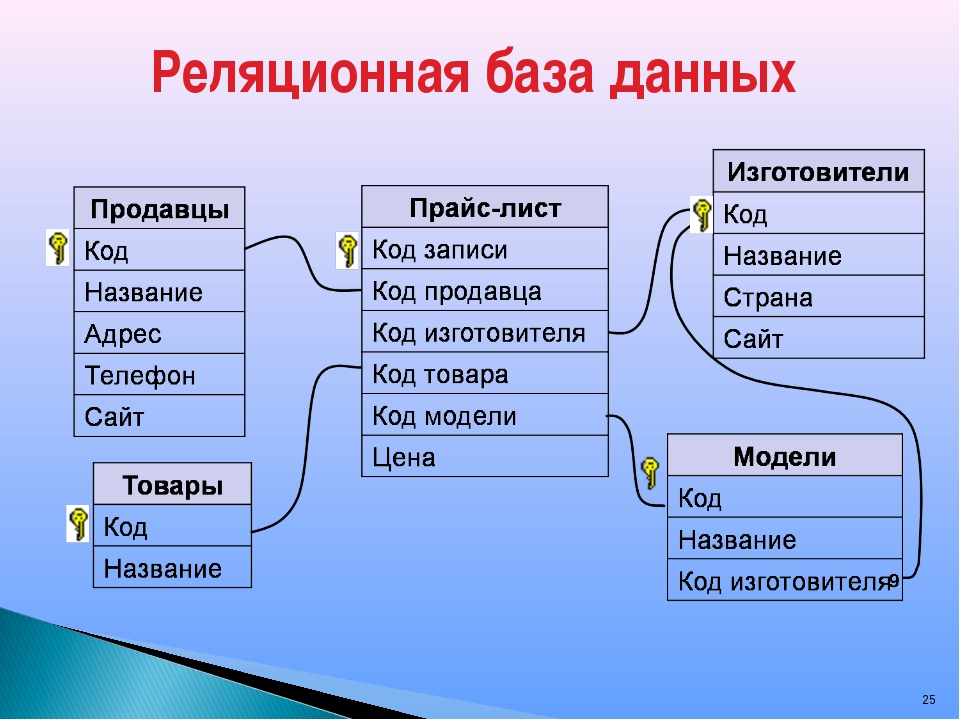
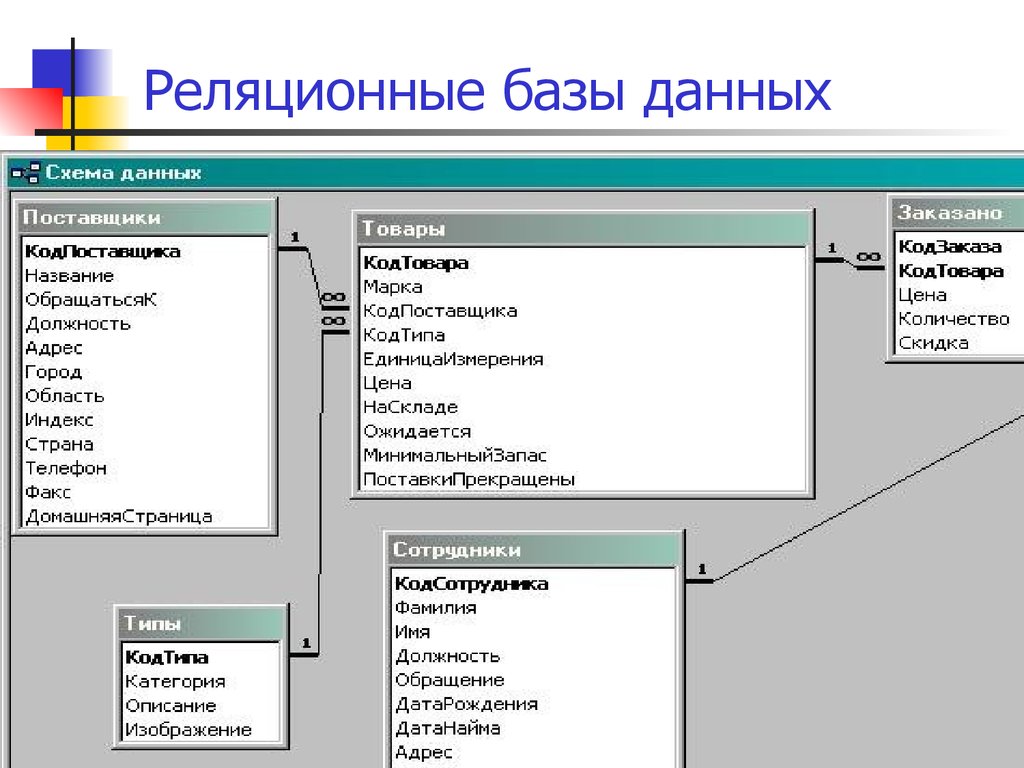
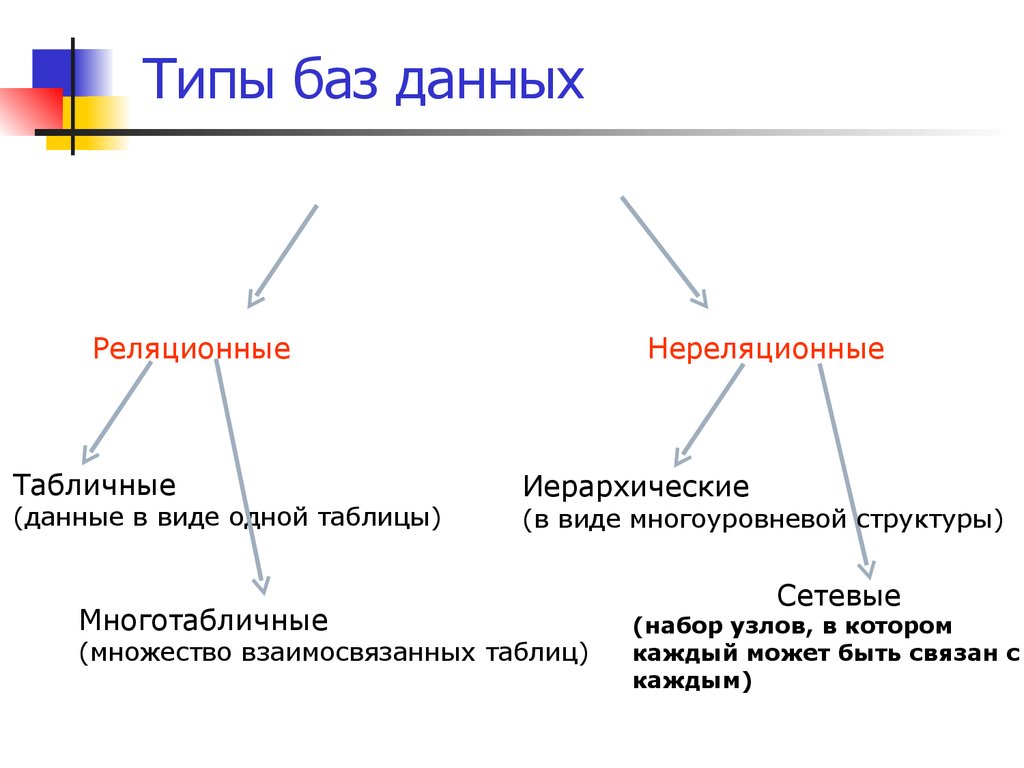
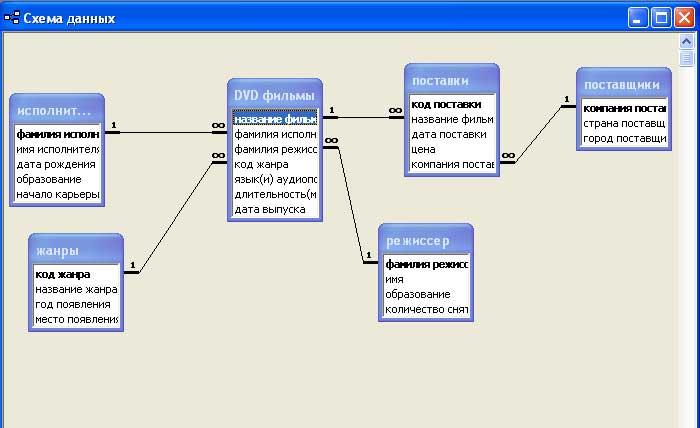
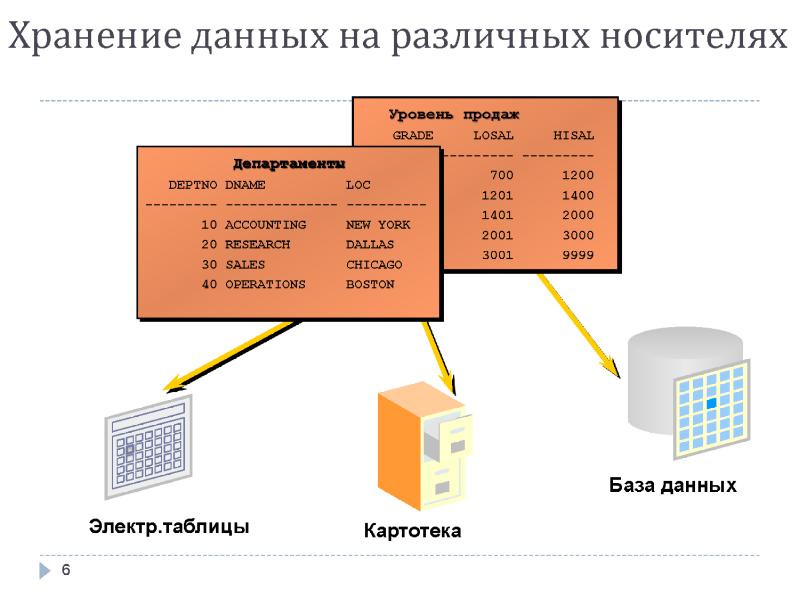
Реляционная база данных
Под данным типом баз данных понимается их представление в рамках двумерной таблицы. Она имеет несколько столбцов, в которых устанавливаются такие параметры, как, например, тип вводимых данных (текст, число, дата и др.).
Таблица здесь является способом хранения введённых в неё данных и способна реагировать на любые обращения со стороны СУБД. Главная проблема в работе с реляционными базами данных состоит в их правильном проектировании.
Во время проектирования базы данных следует учесть следующие два фактора:
Уроки программирования на PHP
Обучение с полного нуля до уровня джуниора!
Начать бесплатно
- база данных должна быть компактной и не содержать избыточных компонентов;
- обработка базы данных должны происходить просто.
Проблема в том, что эти факторы друг другу противоречат. А ведь проектирование — важнейший момент при составлении базы данных и дальнейшей работе с ней. Заниматься им рекомендуется администратору сервера, обладающему определённым опытом.
В крупных проектах задействовано множество таблиц, которых может быть более сотни. При этом обойтись без них невозможно, если человек имеет дело с важным и сложным проектом.



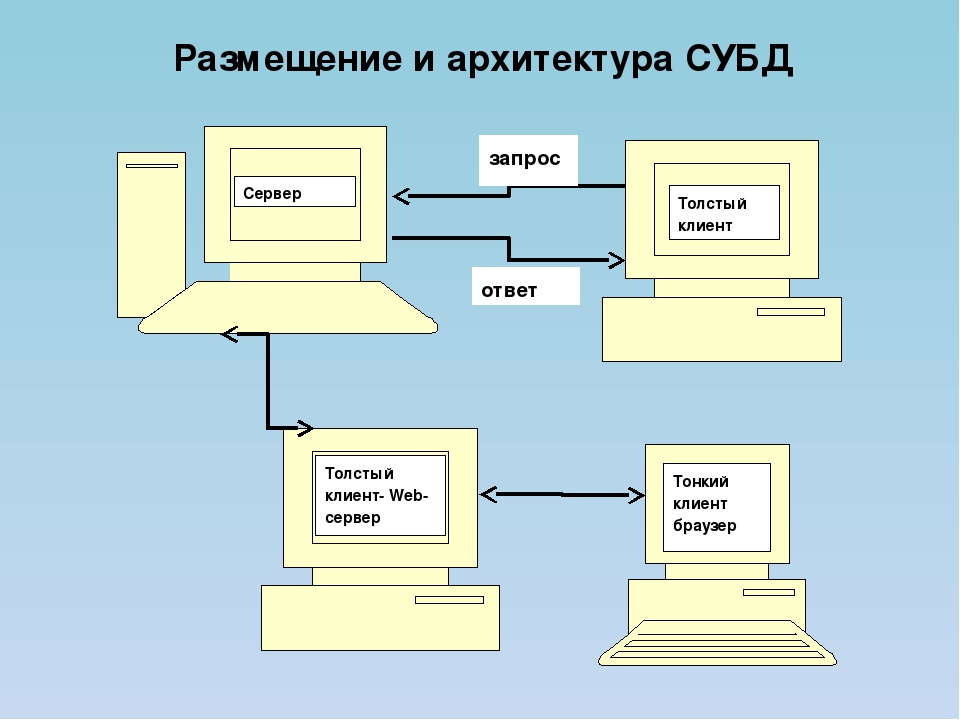



Перед составлением таблицы следует составить диаграмму или схему, в которой содержится информация о видах хранимой информации, а также о типе данных, который лучше всего подойдёт для таких целей.
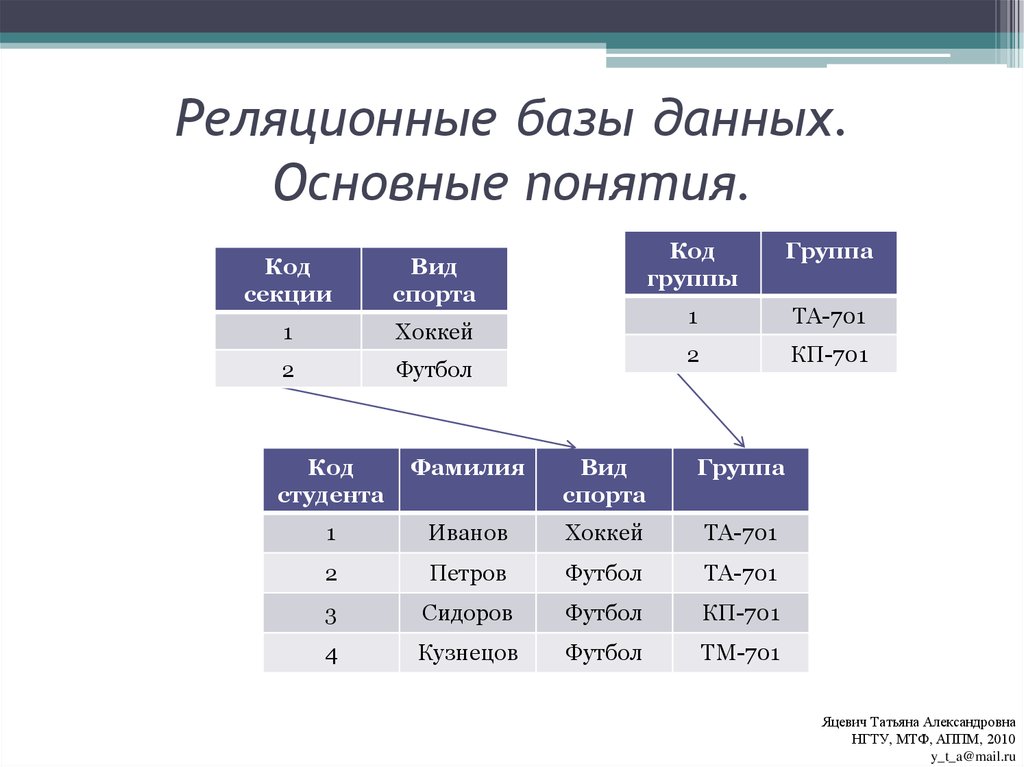
Отношение один-ко-многим
Хорошим примером отношения между таблицами
один-ко-многим является отношение между авторами
и названиями книг (таблицы AUTHORS и TITLES), так как
каждый автор может иметь отношение к созданию
нескольких книг. Связь между таблицами AUTHORS и TITLES
осуществляется с помощью совпадающих полей Au_ID в
обеих таблицах.
Аналогичное отношение существует между
издательствами и названиями изданных книг,
организацией и работающими в ней сотрудниками,
автомобилем и деталями, из которых он состоит и
т.п. Понятно, что подобный тип отношения между
таблицами наиболее часто встречается при
проектировании структуры баз данных.
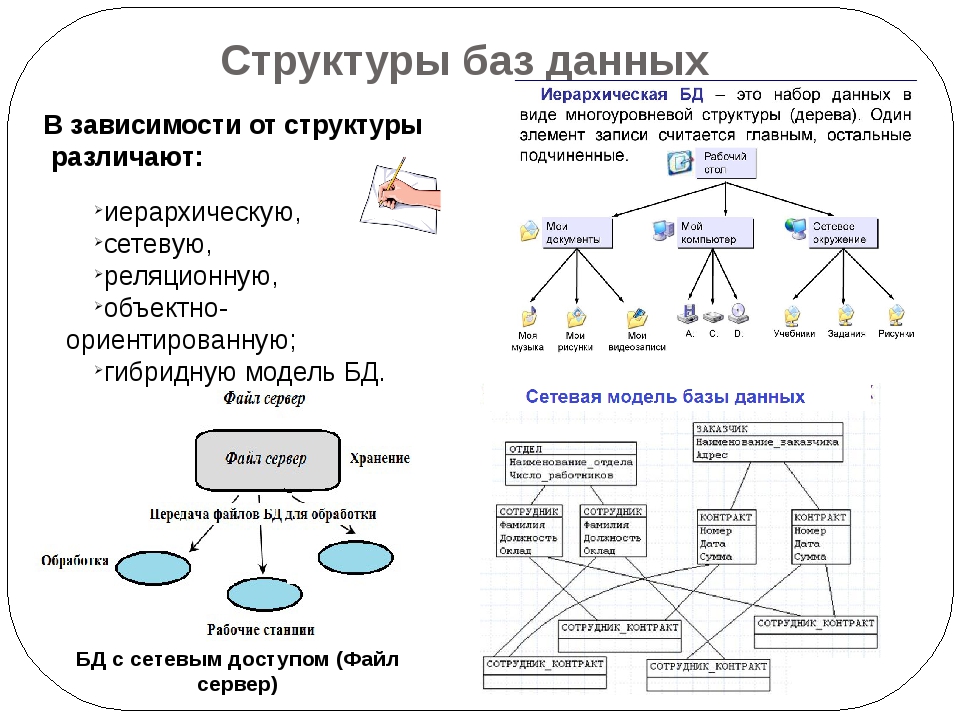
Иерархическая база данных
Под иерархической понимается такая база данных, в которой хранение данных и их структурирование осуществляется по принципу разделения элементов на родительские и дочерние. Преимуществом таких баз является лёгкость в чтении запрашиваемой информации и её быстрое предоставление пользователю.
Компьютер способен быстро ориентироваться в ней. Иерархический принцип взят за основу в структурировании файлов и папок в операционной системе Windows, а реестр хранит информацию о параметрах работы тех или иных приложений в структурированном иерархическим способом виде.
Все интернет-ресурсы также построены по иерархическому принципу, так как при его использовании ориентироваться в рамках сайта очень легко.
В качестве примера можно привести базу данных на языке XML, содержащую в себе очерки о состоянии сельского хозяйства в регионах России. В этом случае родительским элементом выступит государство, далее пойдёт разделение на субъекты, а в рамках субъектов будет своё разветвление. В данном случае от верхнего элемента к нижнему идёт строго одно обращение.
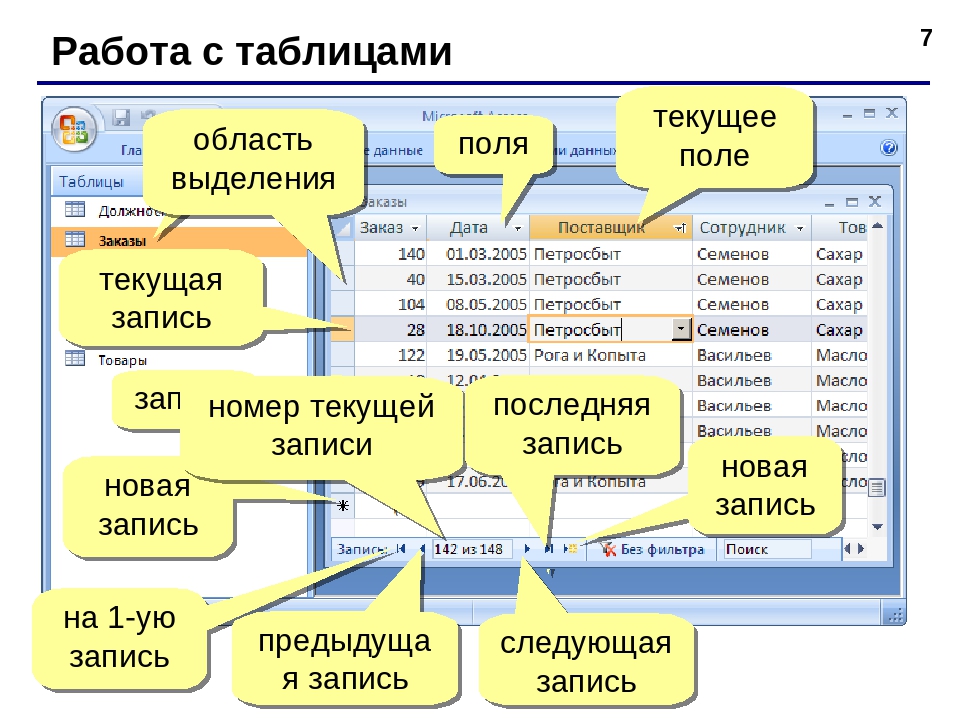
Структура базы данных
Телефонный справочник представляет собой так
называемую “плоскую” базу данных, в которой вся
информация располагается в единственной
таблице. Каждая запись в этой таблице содержит
идентификатор конкретного человека — имя и
фамилию и его номер телефона. Таким образом
таблица состоит из записей, информация в которых
разделена на несколько частей — полей. В данном
случае полями являются “ФИО” и “Номер
телефона”, как показано на рис.1.1.
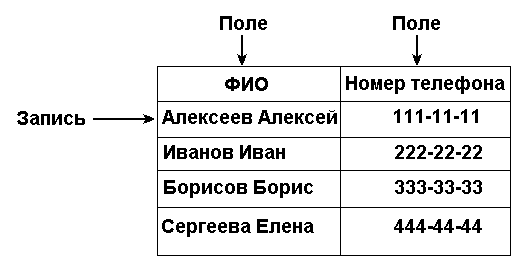 Рис.1.1. Таблица, запись и поле.
Рис.1.1. Таблица, запись и поле.В отличие от плоских, реляционные базы данных
состоят из нескольких таблиц, связь между
которыми устанавливается с помощью совпадающих
значений одноименных полей.
Здесь следует отметить, что использование
реляционной модели баз данных не является
единственно возможным способом представления
информации. В настоящее время существует
несколько различных моделей представления
данных, которые, однако, пока не получили такого
широкого распространения среди разработчиков и
пользователей, как реляционная модель. То есть
при разработке систем управления базами данных
реляционная модель практически является
стандартом.
В качестве примера реляционной базы данных
можно привести поставляемую вместе с Visual Basic базу
данных BIBLIO.MDB, содержащую библиографическую
информацию о книгах по программированию, их
авторах и издательствах, эти книги
опубликовавших.
Так как Visual Basic использует ту же систему
управления базами данных (MS Jet Engine), что и MS Access, то
несмотря на наличие в Visual Basic средств работы со
многими форматами БД, все таки в приложениях
предпочтительно использовать файлы баз данных в
формате MS Access. Эти файлы имеют расширение MDB и
здесь в основном будут описаны приемы работы с
файлами именно такого формата.
Перейдем теперь к исследованию базы данных с
библиографией. Для этого откройте файл BIBLIO.MDB при
помощи MS Access или VisData.
Содержимое файла базы данных BIBLIO.MDB показано на
рис.1.2. В базу данных входят таблицы (Tables), запросы
(Queries), формы (Forms), отчеты (Reports), макросы (Macros) и
модули (Modules). Макросы, формы и модули нам не
интересны, так как это вотчина разработчиков,
применяющих Visual Basic for Applications или, сокращенно, VBA.
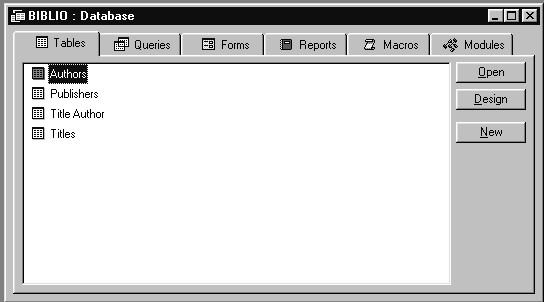 Рис.1.2. Содержимое файла BIBLIO.MDB
Рис.1.2. Содержимое файла BIBLIO.MDBИз рисунка видно, что база данных состоит из
таблиц: PUBLISHERS, AUTHORS и TITLES. Каждая из таблиц
содержит информацию об объектах одного типа. Из
названий таблиц становиться понятно, что данные
в каждой таблице принадлежат одной и той же
группе объектов. Каждая строка в этих таблицах
однозначно определяет один объект из
соответствующей группы. Вообще, база данных
может состоять из одной или нескольких таблиц.
Запись, в свою очередь, состоит из нескольких
полей, каждое из которых содержит элемент данных
об объекте.
Типы данных, которые можно поместить в таблицу,
зависят от формата файла базы данных. В таблице 1.1
приведены некоторые типы данных, которые
поддерживаются системой управления базами
данных Visual Basic для файлов MS Access.
Чем хороши и плохи нереляционные базы данных: главные достоинства и недостатки
По сравнению с классическими SQL-базами, нереляционные СУБД обладают следующими преимуществами:
- линейная масштабируемость – добавление новых узлов в кластер увеличивает общую производительность системы ;
- гибкость, позволяющая оперировать полуструктирированные данные, реализуя, в. т.ч. полнотекстовый поиск по базе ;
- возможность работать с разными представлениями информации, в т.ч. без задания схемы данных ;
- высокая доступность за счет репликации данных и других механизмов отказоустойчивости, в частности, шаринга – автоматического разделения данных по разным узлам сети, когда каждый сервер кластера отвечает только за определенный набор информации, обрабатывая запросы на его чтение и запись. Это увеличивает скорость обработки данных и пропускную способность приложения .
- производительность за счет оптимизации для конкретных видов моделей данных (документной, графовой, колоночной или «ключ‑значение») и шаблонов доступа ;
- широкие функциональные возможности – собственные SQL-подобные языки запросов, RESTful-интерфейсы, API и сложные типы данных, например, map, list и struct, позволяющие обрабатывать сразу множество значений .
Обратной стороной вышеуказанных достоинств являются следующие недостатки:
- ограниченная емкость встроенного языка запросов . Например, HBase предоставляет всего 4 функции работы с данными (Put, Get, Scan, Delete), в Cassandra отсутствуют операции Insert и Join, несмотря на наличие SQL-подобного языка запросов. Для решения этой проблемы используются сторонние средства трансляции классических SQL-выражений в исполнительный код для конкретной нереляционной базы. Например, Apache Phoenix для HBase или универсальный Drill.
- сложности в поддержке всех ACID-требований к транзакциям (атомарность, консистентность, изоляция, долговечность) из-за того, что NoSQL-СУБД вместо CAP-модели (согласованность, доступность, устойчивость к разделению) скорее соответствуют модели BASE (базовая доступность, гибкое состояние и итоговая согласованность) . Впрочем, некоторые нереляционные СУБД пытаются обойти это ограничение с помощью настраиваемых уровней согласованности, о чем мы рассказывали на примере Cassandra. Аналогичным образом Riak позволяет настраивать требуемые характеристики доступности-согласованности даже для отдельных запросов за счет задания количества узлов, необходимых для подтверждения успешного завершения транзакции . Подробнее о CAP-и BASE-моделях мы расскажем в отдельной статье.
- сильная привязка приложения к конкретной СУБД из-за специфики внутреннего языка запросов и гибкой модели данных, ориентированной на конкретный случай ;
- недостаток специалистов по NoSQL-базам по сравнению с реляционными аналогами .
Подводя итог описанию основных аспектов нереляционных СУБД, стоит отметить некоторую некорректность запроса «NoSQL vs SQL» в связи с разными архитектурными подходами и прикладными задачами, на которые ориентированы эти ИТ-средства. Традиционные SQL-базы отлично справляются с обработкой строго типизированной информации не слишком большого объема. Например, локальная ERP-система или облачная CRM. Однако, в случае обработки большого объема полуструктурированных и неструктурированных данных, т.е. Big Data, в распределенной системе следует выбирать из множества NoSQL-хранилищ, учитывая специфику самой задачи. В частности, для самостоятельных решений интернета вещей (Internet of Things), в т.ч. промышленного, отлично подходит Cassandra, о чем мы рассказывали здесь





А в случае многоуровневой ИТ-инфраструктуры на базе Apache Hadoop стоит обратить внимание на HBase, которая позволяет оперативно, практически в режиме реального времени, работать с данными, хранящимися в HDFS
Нереляционные СУБД находят больше областей приложений, чем традиционные SQL-решения
Источники
- https://ru.wikipedia.org/wiki/NoSQL
- https://aws.amazon.com/ru/nosql/
- https://ru.bmstu.wiki/NoSQL
- https://tproger.ru/translations/types-of-nosql-db/
- https://habr.com/ru/sandbox/113232/







