Техники и методы анализа и обработки больших данных
К основным методам анализа и обработки данных можно отнести следующие:
Методы класса или глубинный анализ (Data Mining)
Данные методы достаточно многочисленны, но их объединяет одно: используемый математический инструментарий в совокупности с достижениями из сферы информационных технологий.
Краудсорсинг
Данная методика позволяет получать данные одновременно из нескольких источников, причем количество последних практически не ограничено.
А/В-тестирование
Из всего объема данных выбирается контрольная совокупность элементов, которую поочередно сравнивают с другими подобными совокупностями, где был изменен один из элементов. Проведение подобных тестов помогает определить, колебания какого из параметров оказывают наибольшее влияние на контрольную совокупность. Благодаря объемам Big Data можно проводить огромное число итераций, с каждой из них приближаясь к максимально достоверному результату.
Прогнозная аналитика
Специалисты в данной области стараются заранее предугадать и распланировать то, как будет вести себя подконтрольный объект, чтобы принять наиболее выгодное в этой ситуации решение.
Кто живет в соцсетях?
Как бы ни гремели скандалы про PRISM, про персональные данные и их утечки, социальные сети так и манят поведать о себе всё: какие котята нравятся, с кем ты дружишь и почему с утра такой не выспавшийся.
Целая энциклопедия о поведении большинства интернет-активной публики лежит совсем рядом, и мне всегда хотелось её пощупать. С одной стороны, эти данные лежат вроде бы в открытом доступе, но просто взять и проанализировать их не так легко — всё слишком неструктурировано и разрозненно. К тому же, насколько я знаю, пригодных для машинного анализа наборов данных о соцсетях практически не существует. А для России — так и подавно.
Выбора не оставалось, и пришлось, зловеще хохоча по ночам, писать простеньких пауков для соцсетей ВКонтакте, Одноклассники, МойМир и русского сегмента Фейсбук, которые за несколько месяцев неспешно собрали более или менее статистически-корректный семпл данных. Собиралась только та информация, которую люди сами о себе рассказали. А рассказали они много.
О том, что удалось выудить из таких данных, и пойдет рассказ.
Мифы и легенды про Big Data
Один из наших кластеров для пилотных задач (Data node: 18 servers /2 CPUs, 12 Cores, 64GB RAM/, 12 Disks, 3 TB, SATA — HP DL380g)— Что такое Big Data вообще?
Все знают, что это обработка огромных массивов данных. Но, например, работа с Oracle-базой на 20 Гигабайт или 4 Петабайта — это ещё не Big Data, это просто highload-БД.— Так в чём ключевое отличие Big Data от «обычных» highload-систем?
В возможности строить гибкие запросы. Реляционная база данных, в силу своей архитектуры, предназначена для коротких быстрых запросов, идущих однотипным потоком. Если вы вдруг решите выйти за пределы таких запросов и собрать новый сложный, то базу придётся переписывать – или же она умрёт под нагрузкой.— Откуда берётся эта новая нагрузка?
Если чуть углубиться в архитектуру, то можно увидеть, что традиционные базы данных хранят информацию очень дисперсионно. Например, у нас номер абонента может быть на одном сервере в одной таблице, а его баланс — в другой таблице. Быстродействие требует максимального разбиения данных. Как только мы начинаем делать сложные join’ы, производительность резко падает.
Перспективы и тенденции развития Big data
В 2017 году, когда большие данные перестали быть чем-то новым и неизведанным, их важность не только не уменьшилась, а еще более возросла. Теперь эксперты делают ставки на то, что анализ больших объемов данных станет доступным не только для организаций-гигантов, но и для представителей малого и среднего бизнеса
Такой подход планируется реализовать с помощью следующих составляющих:
Облачные хранилища
Хранение и обработка данных становятся более быстрыми и экономичными – по сравнению с расходами на содержание собственного дата-центра и возможное расширение персонала аренда облака представляется гораздо более дешевой альтернативой.
Использование Dark Data
Так называемые «темные данные» – вся неоцифрованная информация о компании, которая не играет ключевой роли при непосредственном ее использовании, но может послужить причиной для перехода на новый формат хранения сведений.
Искусственный интеллект и Deep Learning
Технология обучения машинного интеллекта, подражающая структуре и работе человеческого мозга, как нельзя лучше подходит для обработки большого объема постоянно меняющейся информации. В этом случае машина сделает все то же самое, что должен был бы сделать человек, но при этом вероятность ошибки значительно снижается.
Blockchain
Эта технология позволяет ускорить и упростить многочисленные интернет-транзакции, в том числе международные. Еще один плюс Блокчейна в том, что благодаря ему снижаются затраты на проведение транзакций.
Самообслуживание и снижение цен
В 2017 году планируется внедрить «платформы самообслуживания» – это бесплатные площадки, где представители малого и среднего бизнеса смогут самостоятельно оценить хранящиеся у них данные и систематизировать их.
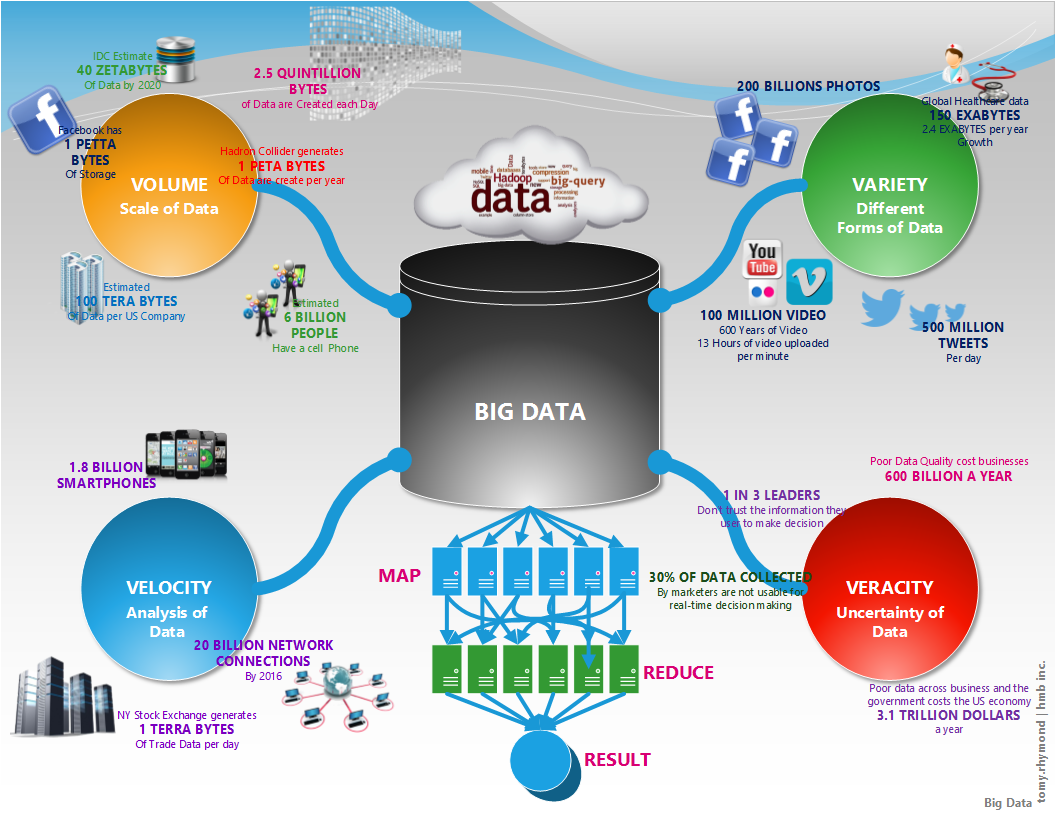
VVV — признаки больших данных

Чтобы уменьшить размытость определений в сфере Big Data, разработаны признаки, которым они должны соответствовать. Все начинаются с буквы V, поэтому система носит название VVV:
• Volume – объём. Объём информации измерим.










• Velocity – скорость. Объём информации не статичен – он постоянно увеличивается, и инструменты обработки должны это учитывать.
• Variety – многообразие. Информация не обязана иметь один формат. Она может быть неструктурированной, частично или полностью структурированной.
К этим трём принципам, с развитием отрасли, добавляются дополнительные V. Например, veracity – достоверность, value – ценность или viability – жизнеспособность.
Но для понимания достаточно первых трёх: большие данные измеримые, прирастающие и неоднообразные.
Где IT-специалисту поучиться этике цифровых технологий? Подборка курсов на русском и английском языках
Этика цифровых технологий — развивающаяся сфера прикладной этики. Например, она помогает ответить на вопрос, почему москвичи ненавидят приложение «Социальный мониторинг», но не только. На Западе этика уже является одним из краеугольных камней сферы IT. Коммерческие, некоммерческие и государственные организации пишут и даже стараются соблюдать этические кодексы с правилами разработки и использования цифровых технологий.
Мы задались вопросом, где российские IT-специалисты при желании могут получить базовые знания этики цифровых технологий. По всей видимости, это должен быть небольшой курс — не лекция на 10 минут, но и не семестр. Не в рамках обучения на бакалавриате или магистратуре в вузе, а доступное прямо сейчас и онлайн.
Мы выяснили:
- на английском языке таких курсов мало;
- на русском языке их практически нет.
Всего мы нашли 11 курсов на 8 площадках и один интересный курс от Fast.ai, пост о котором попал в умную ленту постов на Facebook после двух дней изучения темы. Полный список внутри.
PVS-Studio Visits Apache Hive
For the past ten years, the open-source movement has been one of the key drivers of the IT industry’s development, and its crucial component. The role of open-source projects is becoming more and more prominent not only in terms of quantity but also in terms of quality, which changes the very concept of how they are positioned on the IT market in general. Our courageous PVS-Studio team is not sitting idly and is taking an active part in strengthening the presence of open-source software by finding hidden bugs in the enormous depths of codebases and offering free license options to the authors of such projects. This article is just another piece of that activity! Today we are going to talk about Apache Hive. I’ve got the report — and there are things worth looking at.
На пути к индивидуальному образованию: анализ данных Яндекс.Репетитора
Наверняка почти каждый мечтает о персонализированном образовании: двигаться к своей образовательной цели максимально коротким путём, решать только те задачи, состав и сложность которых подстраиваются под тебя, с пользой проводить любой отрезок времени независимо от длительности и структуры
Неважно, будь то пятиминутный перерыв от работы или ежевечерние занятия на протяжении месяцев
Такой инструмент позволил бы экономить огромное количество времени и при этом добиваться значительно лучших результатов. Эффективность обмена знаниями значительно повысилась бы, а вслед за этим ускорился бы и прогресс.
Но пока человечество совершает лишь робкие попытки подобраться к пониманию, как создавать такой инструмент. Свою попытку осуществила и команда Яндекс.Репетитора. Сервис, запущенный менее двух лет назад, накопил данные о ста миллионах решений различных задач, и этого достаточно для интересной аналитики. Понятно, что образование состоит не только из задач, но сегодня мы сфокусируемся на них.
В статье я расскажу, какую аналитику мы научились строить на базе собранных данных и благодаря каким свойствам сервиса она оказывается возможной. В самом конце вас ждёт небольшой отчёт о нашей первой попытке построить сервис для персонализированного образования и о результатах этого эксперимента.
Яндекс открывает ClickHouse
Сегодня внутренняя разработка компании Яндекс — аналитическая СУБД ClickHouse, стала доступна каждому. Исходники опубликованы на GitHub под лицензией Apache 2.0.
ClickHouse позволяет выполнять аналитические запросы в интерактивном режиме по данным, обновляемым в реальном времени. Система способна масштабироваться до десятков триллионов записей и петабайт хранимых данных. Использование ClickHouse открывает возможности, которые раньше было даже трудно представить: вы можете сохранять весь поток данных без предварительной агрегации и быстро получать отчёты в любых разрезах. ClickHouse разработан в Яндексе для задач Яндекс.Метрики — второй по величине системы веб-аналитики в мире.
В этой статье мы расскажем, как и для чего ClickHouse появился в Яндексе и что он умеет; сравним его с другими системами и покажем, как его поднять у себя с минимальными усилиями.
Спасти рядового датасайнтиста. Как работать над компьютерным зрением, чтобы сделать проект и не потерять себя
Меня зовут Александра Царева. Я и мои коллеги работаем над проектами в сфере компьютерного зрения в Центре машинного обучения компании «Инфосистемы Джет». Мне хочется поделиться нашим опытом разработки и внедрения проектов в сфере компьютерного зрения.
В этом материале я расскажу о том, как выглядит процесс работы датасайнтиста над проектом не с «духовной» и, собственно, датасайнтистской точки зрения, а больше с организационной. И надеюсь, что за этим постом последует еще несколько и удастся написать небольшую серию.
Сразу оговорю два важных пункта:
- Эти шаги касаются практически любого датасайнс-проекта. Но некоторые моменты вызваны эффектом хайпа вокруг CV, некоторой славой «серебряной пули» у компьютерного зрения и желанием заказчика, «чтоб было с нейросетью».
- Я говорю о том, что эти шаги в первую очередь проходит сам датасайнтист, но некоторые из них хочется делегировать — менеджеру проекта, бизнес-аналитику или иному коллеге. С моей точки зрения, стоит исходить из предпосылки, что этого коллеги или нет (маленькая компания, другая структура работы и т.п.) или он в любом случае не знает так хорошо ограничения машинного обучения и нейросетей, как профильный специалист — то есть нуждается в консультации и совместном разборе каких-то вопросов.
Analyzing the Code of ROOT, Scientific Data Analysis Framework
While Stockholm was holding the 118th Nobel Week, I was sitting in our office, where we develop the PVS-Studio static analyzer, working on an analysis review of the ROOT project, a big-data processing framework used in scientific research. This code wouldn’t win a prize, of course, but the authors can definitely count on a detailed review of the most interesting defects plus a free license to thoroughly check the project on their own.










Introduction
ROOT is a modular scientific software toolkit. It provides all the functionalities needed to deal with big data processing, statistical analysis, visualisation and storage. It is mainly written in C++. ROOT was born at CERN, at the heart of the research on high-energy physics. Every day, thousands of physicists use ROOT applications to analyze their data or to perform simulations.
Архитектура
1. Region Server регионов.
- Persistent Storage — основное хранилище данных в Hbase. Данные физически хранятся на HDFS, в специальном формате HFile. Данные в HFile хранятся в отсортированном по RowKey порядке. Одной паре (регион, column family) соответствует как минимум один HFIle.
- MemStore — буфер на запись. Так как данные хранятся в HFile d отсортированном порядке — обновлять HFile на каждую запись довольно дорого. Вместо этого данные при записи попадают в специальную область памяти MemStore, где накапливаются некоторое время. При наполнении MemStore до некоторого критического значения данные записываются в новый HFile.
- BlockCache — кэш на чтение. Позволяет существенно экономить время на данных которые читаются часто.
- Write Ahead Log(WAL). Так как данные при записи попадают в memstore, существует некоторый риск потери данных из-за сбоя. Для того чтобы этого не произошло все операции перед собственно осуществление манипуляций попадают в специальный лог-файл. Это позволяет восстановить данные после любого сбоя.
2. Master ServerApache ZooKeepercompaction.
- Minor Compaction. Запускается автоматически, выполняется в фоновом режиме. Имеет низкий приоритет по сравнению с другими операциями Hbase.
- Major Compaction. Запускается руками или по наступлению срабатыванию определенных триггеров(например по таймеру). Имеет высокий приоритет и может существенно замедлить работу кластера. Major Compaction’ы лучше делать во время когда нагрузка на кластер небольшая. Во время Major Compaction также происходит физическое удаление данных, ране помеченных меткой tombstone.
Как сократить издержки на автотестах
Автотесты — модная, но довольно затратная история. Автоматизаторы стоят дороже, чем ручные тестировщики, а сами автотесты требуют больше времени на разработку, причем разрабатывается не функционал продукта, а его проверка, которая окупается не явно и не сразу. Требует затрат и поддержка автотестов. Однако каждую из этих статей расходов можно минимизировать, сделав автотестирование намного эффективнее.
Меня зовут Мария Снопок, я менеджер направления автоматизации в Отделе тестирования Департамента разработки и сопровождения продуктов больших данных X5 Retail Group. В этой статье я расскажу о нашем опыте внедрения автотестов и сокращении связанных с ними издержек. Надеюсь, эта информация окажется полезной для команд, которые сталкиваются с трудностями при переходе на автоматизированное тестирование.
Примеры big data в бизнесе
Как мы в обычной жизни сталкиваемся с большими данными, мы уже рассмотрели выше. Понятно, что за этим стоят крупные компании. А теперь ловите несколько кейсов, из которых понятно — big data полезны и нужны бизнесу намного больше, чем нам!
Банки используют big data, чтобы оптимизировать затраты и уменьшить риски. Они борются с мошенничеством, оценивают платежеспособность клиентов, управляют персоналом, прогнозируют загруженность касс, отделений и терминалов.

Производственные предприятия используют big data для оптимизации расхода материалов, формирования очереди на закупку сырья, прогнозирования скачков спроса и цены.
Маркетинговые компании прогнозируют успешность рекламных объявлений для конкретных пользователей и предлагают ту рекламу, которая их точно заинтересует и поможет решиться на покупку товара или заказ услуги.
Транспортные компании получают точные погодные прогнозы и оценивают риски простоев и задержек в пути, отслеживают состояние транспортных средств и принимаются за ремонт раньше, чем те выходят из строя. Логистические сервисы оптимизируют маршруты.
СМИ выбирают лучшее время для публикации новостей — тех, которые получат максимум внимания и отклика у читателей.

Образовательные учреждения благодаря сбору больших данных находят интересный и полезный обучающий контент. А учащиеся получают информацию в том виде — текстовом, видео, аудио, — в котором лучше ее усваивают. Так растет интерес к образованию и уровень вовлеченности в обучение.
Полиция предотвращает правонарушения в потенциально опасных районах (за счет увеличения числа патрульных) и на мероприятиях, где могут произойти столкновения. Снижается уровень преступности.
Инвесторы с помощью больших данных находят интересных и перспективных партнеров — компании и стартапы, которые принесут прибыль.
Где угодно big data используются для оптимизации затрат на энергоресурсы, логистику, привлечение новых клиентов, обслуживание и ремонт оборудования, сокращение убытков.
Как обрабатываются большие данные
Допустим, мы собрали много разнородной информации и придумали, где ее хранить. Что дальше? Существуют технологии, которые позволяют находить среди вороха данных нужную информацию. Сделать это нужно быстро, а результат должен быть максимально точным. Чем лучше это получается, тем успешнее бизнес, который эти данные собирает. По-прежнему нужны мощные вычислительные ресурсы и программные алгоритмы, которые строятся на принципах машинного обучения. Люди не работают с big data напрямую — это долго и дорого. Программа может зацепиться за один фрагмент (текст, движение, картинка, аудио и т. п. — абсолютно любые типы данных), затем за второй, третий и так далее. Она установит между ними взаимосвязь и спрогнозирует, какими будут следующие фрагменты.










MapReduce
Про MapReduce на хабре уже писали (раз, два, три), но раз уж цикл статей претендует на системное изложение вопросов Big Data – без MapReduce в первой статье не обойтись J
MapReduce предполагает, что данные организованы в виде некоторых записей. Обработка данных происходит в 3 стадии:
1. Стадия Map. На этой стадии данные предобрабатываются при помощи функции map(), которую определяет пользователь. Работа этой стадии заключается в предобработке и фильтрации данных. Работа очень похожа на операцию map в функциональных языках программирования – пользовательская функция применяется к каждой входной записи. Функция map() примененная к одной входной записи и выдаёт множество пар ключ-значение. Множество – т.е. может выдать только одну запись, может не выдать ничего, а может выдать несколько пар ключ-значение. Что будет находится в ключе и в значении – решать пользователю, но ключ – очень важная вещь, так как данные с одним ключом в будущем попадут в один экземпляр функции reduce.
2. Стадия Shuffle. Проходит незаметно для пользователя. В этой стадии вывод функции map «разбирается по корзинам» – каждая корзина соответствует одному ключу вывода стадии map. В дальнейшем эти корзины послужат входом для reduce.
3. Стадия Reduce. Каждая «корзина» со значениями, сформированная на стадии shuffle, попадает на вход функции reduce(). Функция reduce задаётся пользователем и вычисляет финальный результат для отдельной «корзины». Множество всех значений, возвращённых функцией reduce(), является финальным результатом MapReduce-задачи.
Несколько дополнительных фактов про MapReduce:
1) Все запуски функции map работают независимо и могут работать параллельно, в том числе на разных машинах кластера.
2) Все запуски функции reduce работают независимо и могут работать параллельно, в том числе на разных машинах кластера.
3) Shuffle внутри себя представляет параллельную сортировку, поэтому также может работать на разных машинах кластера. Пункты 1-3 позволяют выполнить принцип горизонтальной масштабируемости.
4) Функция map, как правило, применяется на той же машине, на которой хранятся данные – это позволяет снизить передачу данных по сети (принцип локальности данных).
5) MapReduce – это всегда полное сканирование данных, никаких индексов нет. Это означает, что MapReduce плохо применим, когда ответ требуется очень быстро.
Алгоритм MADDPG OpenAI
Перевод
Новый подход
Мультиагентное обучение с подкреплением – это развивающаяся и богатая область исследований. Тем не менее постоянное применение одноагентных алгоритмов в мультиагентных контекстах ставит нас в затруднительное положение. Обучение усложняется по многим причинам, в особенности из-за:
- Нестационарности между независимыми агентами;
- Экспоненциального роста пространств действий и состояний.
Исследователи нашли множество способов уменьшить воздействие этих факторов. Большая часть этих методов попадает под понятие «централизованного планирования с децентрализованным выполнением.»
Удивительный рост Биг-Даты
Все началось со «взрыва» в объеме данных, которые мы создали с самого начала цифровой эпохи. Это во многом связано с развитием компьютеров, Интернета и технологий, способных «выхватывать» данные из окружающего нас мира. Данные сами по себе не являются новым изобретением. Еще до эпохи компьютеров и баз данных мы использовали бумажные записи транзакций, клиентские записи и архивные файлы, которые и являются данными. Компьютеры, в особенности электронные таблицы и базы данных, позволили нам легко и просто хранить и упорядочивать данные в больших масштабах. Внезапно информация стала доступной при помощи одного щелчка мыши.









Тем не менее, мы прошли долгий путь от первоначальных таблиц и баз данных. Сегодня через каждые два дня мы создаем столько данных, сколько мы получили с самого начала вплоть до 2000 года. Правильно, через каждые два дня. И объем данных, которые мы создаем, продолжает стремительно расти; к 2020 году объем доступной цифровой информации возрастет примерно с 5 зеттабайтов до 20 зеттабайтов.
В настоящее время почти каждое действие, которое мы предпринимаем, оставляет свой след. Мы генерируем данные всякий раз, когда выходим в Интернет, когда переносим наши смартфоны, оборудованные поисковым модулем, когда разговариваем с нашими знакомыми через социальные сети или чаты и т.д. К тому же, количество данных, сгенерированных машинным способом, также быстро растет. Данные генерируются и распространяются, когда наши «умные» домашние устройства обмениваются данными друг с другом или со своими домашними серверами. Промышленное оборудование на заводах и фабриках все чаще оснащается датчиками, которые аккумулируют и передают данные.
Термин «Big-Data» относится к сбору всех этих данных и нашей способности использовать их в своих интересах в широком спектре областей, включая бизнес.
Источники больших данных
В качестве примера типичного источника больших данных можно привести социальные сети – каждый профиль или публичная страница представляет собой одну маленькую каплю в никак не структурированном океане информации. Причем независимо от количества хранящихся в том или ином профиле сведений взаимодействие с каждым из пользователей должно быть максимально быстрым.
Большие данные непрерывно накапливаются практически в любой сфере человеческой жизни. Сюда входит любая отрасль, связанная либо с человеческими взаимодействиями, либо с вычислениями. Это и социальные медиа, и медицина, и банковская сфера, а также системы устройств, получающие многочисленные результаты ежедневных вычислений. Например, астрономические наблюдения, метеорологические сведения и информация с устройств зондирования Земли.
Информация со всевозможных систем слежения в режиме реального времени также поступает на сервера той или иной компании. Телевидение и радиовещание, базы звонков операторов сотовой связи – взаимодействие каждого конкретного человека с ними минимально, но в совокупности вся эта информация становится большими данными.
Примеры задач, эффективно решаемых при помощи MapReduce
Word Count
Начнём с классической задачи – Word Count. Задача формулируется следующим образом: имеется большой корпус документов. Задача – для каждого слова, хотя бы один раз встречающегося в корпусе, посчитать суммарное количество раз, которое оно встретилось в корпусе.
Решение:
Раз имеем большой корпус документов – пусть один документ будет одной входной записью для MapRreduce–задачи. В MapReduce мы можем только задавать пользовательские функции, что мы и сделаем (будем использовать python-like псевдокод):
Функция map превращает входной документ в набор пар (слово, 1), shuffle прозрачно для нас превращает это в пары (слово, ), reduce суммирует эти единички, возвращая финальный ответ для слова.
Обработка логов рекламной системы
Второй пример взят из реальной практики Data-Centric Alliance.
Задача: имеется csv-лог рекламной системы вида:
Решение:
Функция map проверяет, нужна ли нам данная запись – и если нужна, оставляет только нужную информацию (город и размер платежа). Функция reduce вычисляет финальный ответ по городу, имея список всех платежей в этом городе.
В чем разница между Data Analytics и статистикой
Перевод
Разбираемся в ценности двух совершенно разных профессий.
Статистика и аналитика это два раздела дата сайнс, у которых было много предшественников. Люди до сих пор спорят о том, где проходит граница между ними. На практике современные программы обучения, которые содержат в названиях эти термины, разбирают совершенно разные задачи. Аналитики специализируются на изучении ваших данных, а статистики уделяют больше внимания выводам, которые можно сделать на основе этих данных.Disclaimer: Эта статья о типичных выпускниках учебных программ, в которых преподают только статистику или только аналитику. Я не хочу задеть тех, кто каким-то образом смог освоить и то и другое. На самом деле лучшие датасаентисты должны иметь отличные знания и в статистике, и в аналитике (и в машинном обучении само собой). Вы удивитесь, но такие специалисты встречаются, правда очень редко.
Человеческие поисковые системы
Когда вы располагаете всеми фактами касательно вашей деятельности, единственная квалификация, которая вам нужна, это здравый смысл. Он позволяет вам задавать вопросы о данных и отвечать на них. Просто поищите ответ.
Хотите прямо сейчас увидеть базовую аналитику в действии? Попробуйте загуглить прогноз погоды. Каждый раз, когда вы пользуетесь поисковой системой, вы занимаетесь базовой аналитикой. Вы получаете данные о погоде и смотрите на них.








Contextual Emotion Detection in Textual Conversations Using Neural Networks
Nowadays, talking to conversational agents is becoming a daily routine, and it is crucial for dialogue systems to generate responses as human-like as possible. As one of the main aspects, primary attention should be given to providing emotionally aware responses to users. In this article, we are going to describe the recurrent neural network architecture for emotion detection in textual conversations, that participated in SemEval-2019 Task 3 “EmoContext”, that is, an annual workshop on semantic evaluation. The task objective is to classify emotion (i.e. happy, sad, angry, and others) in a 3-turn conversational data set.
Нейросетевые языковые модели как многоцелевой медицинский ИИ
Нейросетевые языковые модели — это большие нейронные сети, которые обучаются предсказывать следующее слово (или часть слова) в тексте с учетом предыдущего контекста. Несмотря на кажущуюся простоту задачи, оказалось, что такая постановка задачи приводит к появлению весьма многофункциональной нейронной сети.
Некоторые исследователи даже предположили, что языковые модели могут стать путем к AGI — сильному искусственному интеллекту человеческого уровня. Предположение это исходит из того, что сама задача предсказания следующего слова является ИИ-полной (требующей мышления) на уровне человека. В этой статье приведу некоторые примеры того, что может сделать с языковой моделью, обученной на медицинских данных.
Видеоаналитика в нефтехимии
Привет! Меня зовут Вадим Щемелинин, я владелец продукта по видеоаналитике в СИБУРе.
Как мы уже неоднократно писали, наши объекты — это довольно большие производства, как с точки зрения занимаемой площади, так и количества различных установок и узлов. Чтобы всё это работало и не возникало каких-то ситуаций, способных вызвать остановку производственного процесса, за каждым узлом нужно следить. Поэтому у нас есть и специальные люди, которые этим занимаются, и приложение для мобильных обходов, которое существенно упрощает этим людям жизнь.
Отдельно здесь стоит рассказать про видеоаналитику. Она может решать разные задачи — повышать качество продукции благодаря автоматическому контролю и отбраковке, помогать исключить внезапные остановы производственных линий, своевременно предупреждая оператора о необходимости вмешаться, контролировать соблюдение правил промышленной безопасности, что для промышленного объекта является задачей номер один. Что в принципе можно анализировать, просматривая видео с объектов (и нужно ли его просматривать), как видеоаналитика помогает экономить время и средства, на чем у нас все работает — об этом под катом.
Introducing One Ring — an open-source pipeline for all your Spark applications
If you utilize Apache Spark, you probably have a few applications that consume some data from external sources and produce some intermediate result, that is about to be consumed by some applications further down the processing chain, and so on until you get a final result.
We suspect that because we have a similar pipeline with lots of processes like this one:
Click here for a bit larger version
Each rectangle is a Spark application with a set of their own execution parameters, and each arrow is an equally parametrized dataset (externally stored highlighted with a color; note the number of intermediate ones). This example is not the most complex of our processes, it’s fairly a simple one. And we don’t assemble such workflows manually, we generate them from Process Templates (outlined as groups on this flowchart).
So here comes the One Ring, a Spark pipelining framework with very robust configuration abilities, which makes it easier to compose and execute a most complex Process as a single large Spark job.
And we just made it open source. Perhaps, you’re interested in the details.







