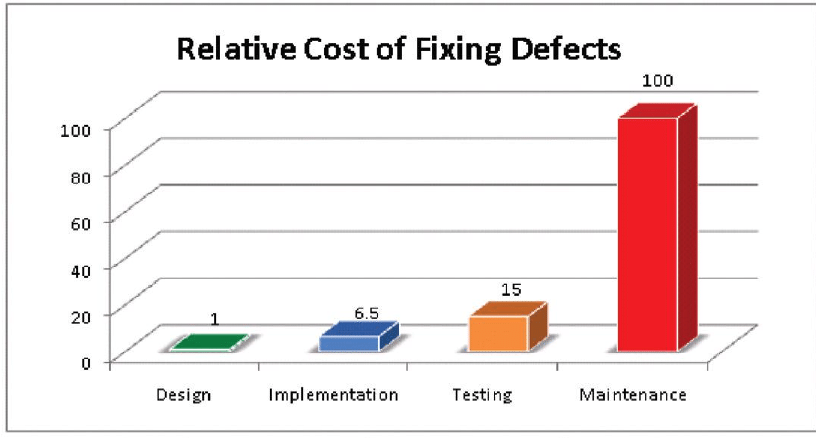
Введение
В эпоху data-intensive приложений рядовым разработчикам всё чаще приходится сталкиваться с задачами по обработке и анализу данных. Ещё десять лет назад данные большинства проектов могли уместиться на жестком диске одного компьютера в какой-нибудь реляционной базе данных типа MySQL. А задачи по извлечению и обработке хранящихся данных решались за счёт непростых (или простых) SQL запросов. С тех пор мир информационных технологий значительно поменялся. С приходом Internet of Things, мобильных телефонов и дешевого мобильного интернета, объем генерируемых данных вырос в десятки тысяч раз. Ежедневно в мире генерируются эксабайты данных. Анализировать такой поток информации вручную, а тем более извлекать полезные для бизнеса или науки данные, практически невозможно. Но технологии как и время не стоят на месте, появляются новые инструменты, наука двигает прогресс. Если вы хоть чуточку следите за новостями из мира высоких технологий, то фразы «биг дата», «машинное обучение», «глубокое обучение» вас не испугают. С приходом больших данных появились новые профессии и специализации такие как Data Scientist/Analyst (по-русски аналитик данных), Data Engineer. Задачи этих ребят тесно связаны с обработкой, анализом и хранением «нефти 21 века», т.е. информации. Но насколько эффективно они выполняются?
Пример из практики
Клиент решил полностью переработать мобильное приложение, так как прошлое устарело и морально и технологически. Было решено работать спринтами, постепенно развивая приложение. В конце каждого спринта должна быть полностью готова часть функциональности. Ожидалось, что к размещению в AppStore и Google Play будет готово примерно через 6 месяцев.
В первый же спринт команде была поставлена задача: выполнить полностью две конкретные пользовательские истории. Но была и вторая часть — приложение во время обзора результатов спринта должно быть установлено на мобильные телефоны участников обзора.
Команда справилась великолепно. Быстро реализовали функционал и подготовили скелет delivery pipeline от коммита до публикации с рассылкой ссылки на скачивание и установку всем заинтересованным сторонам. Плюс в том, что в первые две недели проверили pipeline на реальном приложении (те самые две пользовательские истории), собрали проблем, пока кода было не много и проблемы было легче решить, довели скелет до стабильного состояния.
Начиная со следующего спринта начали писать автотесты, точно так же, небольшими порциями. На обзоре спринта показывали не только основной функционал, но и ускоренную видеозапись прохождения автотестов. Тем самым зарабатывали политический капитал, улучшая процесс и повышая стабильность сборки одновременно.
Pipeline развивался. Спустя примерно полтора месяца стало ясно, что, не отвлекаясь на процесс поставки и развертывания, не отвлекаясь на незапланированную работу в виде дефектов (они были, но их было не много) то, что планировалось выпустить через 6 месяцев будет готово уже через четыре. Было принято решение добавить немного новой функциональности в изначальный скоуп, чтобы приложение выгодно выделялось среди остальных подобных. Что и было выполнено. Эти задачи не были обязательными, так что давления бизнеса не было и команда могла заниматься разработкой в обычном режиме и с предсказуемым уровнем качества.
Установка и настройка Jenkins
Установка
Существует несколько способов установить Jenkins:
- Из war-архива
- Напрямую из Docker-образа
- Развернуть в Kubernetes
War-архив с программой можно запустить из командной строки или же в контейнере сервлетов (№ Apache Tomcat). Этот вариант мы не будем рассматривать, так как он не обеспечивает достаточной изолированности системы.
Устранить этот недостаток можно, установив Jenkins в Docker. Из коробки Jenkins поддерживает использование докера в пайплайнах, что позволяет дополнительно изолировать билды друг от друга. Запуск докера в докере — плохая идея (здесь можно почитать почему), поэтому необходимо установить дополнительный контейнер ‘docker:dind’, который будет запускать новые контейнеры параллельно контейнеру Jenkins’а.
Также возможно развернуть Jenkins в кластере Kubernetes. В этом случае и Jenkins, и дочерние контейнеры будет работать как отдельные поды. Любой билд будет полностью выполняться в собственном контейнере, что максимально изолирует выполнения друг от друга. Из недостатков этот способ имеет довольно специфичную конфигурацию. Из приятных бонусов Jenkins в Google Kubernetes Engine может быть развернут одним кликом.
Хоть третий способ и кажется наиболее продвинутым, мы выберем прямолинейный путь и развернем Jenkins в Docker напрямую. Это упростит настройку, а также избавит нас от нюансов работы со stateful приложениями в Kubernetes. Хорошая статья для любопытствующих про Jenkins в Kubernetes.
Так как проект учебный, то мы установим Jenkins на локальной машине. В реальной обстановке можно посмотреть в сторону, например, Google Compute Engine. В дополнение замечу, что изначально я пробовал использовать Jenkins на Raspberry Pi, но из-за разной архитектуры «малинки» и машин кластера они не могут использовать одни и те же Docker-образы. Это делает невозможным применение Raspberry Pi для подобных вещей.
Плагины
Меню работы плагинов доступно из настроек (Manage Jenkins -> Manage Plugins). Многие полезные плагины уже установлены. Особо среди них выделю ‘Blue Ocean’, предоставляющий удобный интерфейс для работы с вашими пайплайнами.
Для нашего проекта нам понадобится установить два плагина: Remote File Plugin и Kubernetes CLI. Remote File Plugin позволяет хранить Jenkinsfile в отдельном репозитории, а Kubernetes CLI предоставит доступ к kubectl внутри нашего пайплайна.
Глобальные переменные среды
Так как у нас два сервиса, то мы создадим два пайплайна. Некоторые данные у них будут совпадать, поэтому логично вынести их в одно место. Это можно сделать, задав глобальные переменные среды, которые будут установлены перед выполнением любого билда на сервере Jenkins. Отмечу, что не стоит с помощью этого механизма передавать пароли — для этого существуют секреты.





![Результаты поиска по запросу «[pipeline]» / хабр](https://rusinfo.info/wp-content/uploads/7/c/3/7c35cff00382c2ff815287a4170279e6.png)

Установим следующие глобальные переменные среды (Manage Jenkins -> Configure System -> Global properties -> Environment Variables):
- CLUSTER_URL — адрес мастер-ноды Kubernetes. Можно получить командой
- CLUSTER_NAMESPACE — неймспейс нашего кластера
- HELM_PROJECT — имя инсталляции Helm
- HELM_CHART — имя Helm-чарта. В нашем случае это ‘msvc-repo/msvc-chart’
Секреты
В Jenkins для хранения конфиденциальной информации существуют секреты нескольких типов, например, связка логин-пароль, секретный текст, секретный файл и др. Установим следующие секреты через меню Credentials -> System -> Global credentials -> Add Credentials:
| Имя секрета | Тип | Описание |
|---|---|---|
| github-creds | username with password | Логин/пароль от git-репозиториев |
| dockerhub-creds | username with password | Логин/пароль от реестра Docker-образов |
| kubernetes-creds | secret text | Токен сервисного аккаунта нашего кластера |
В предыдущей части в файле NOTES.txt нашего чарта мы описали последовательность команд для получения токена сервисного аккаунта. Вывести эти команды для кластера можно, запросив статус Helm-инсталляции ().
Luigi
Luigi это один из немногих инструментов в экосистеме Python для построения т.н. pipeline’ов или, по-простому, выполнения пакетных задач (batch jobs). Разработан был инженерами из Spotify. Мне он понравился за свою простоту и широкий спектр возможностей, а именно:
-
управление зависимостями между задачами
-
failover recovery, т.е. если в одной из задач произошла ошибка, не нужно перезапускать цепочку снова
-
центральный планировщик задач с веб-интерфейсом, статусом выполнения задач и трекингом ошибок
-
“батарейки” для работы с HDFS, S3, MySQL, PostgreSQL, Redis, MongoDB, Redshift и т.д.
-
удобное построение CLI (Command Line Interface), в нём очень удобно построена передача параметров из командной строки
Основными строительными блоками Luigi являются 3 объекта: Task, Target и Parameter. Последний используется для взаимодействия с командной строкой и поэтому опционален. Чтобы установить Luigi достаточно выполнить:
Task
Класс Task это основной блок, где происходит выполнение конкретного таска. Чтобы определить свою собственную задачу, необходимо создать класс, унаследованный от Task, и реализовать несколько методов. Зачастую переопределять нужно только 3 метода: run(), output(), requires().
На сайте с документацией к Luigi есть хорошая иллюстрация что из себя представляет каждый метод и класс в целом:

Task.run
Здесь выполняется вся логика вашей будущей задачи, например, скачивание или парсинг данных с внешнего источника, запрос в базу данных для извлечения информации и т.д. Если задача объёмная, то лучше разбить её на функции и вызывать их внутри метода run(), это поможет избежать путанницы в будущем.
Task.requires
Помните я говорил об управлении зависимостями? В методе requires() необходимо их перечислить. Зависимостями выступают другие luigi.Task классы. Чуть позже я покажу реальный пример задачи с зависимостями.





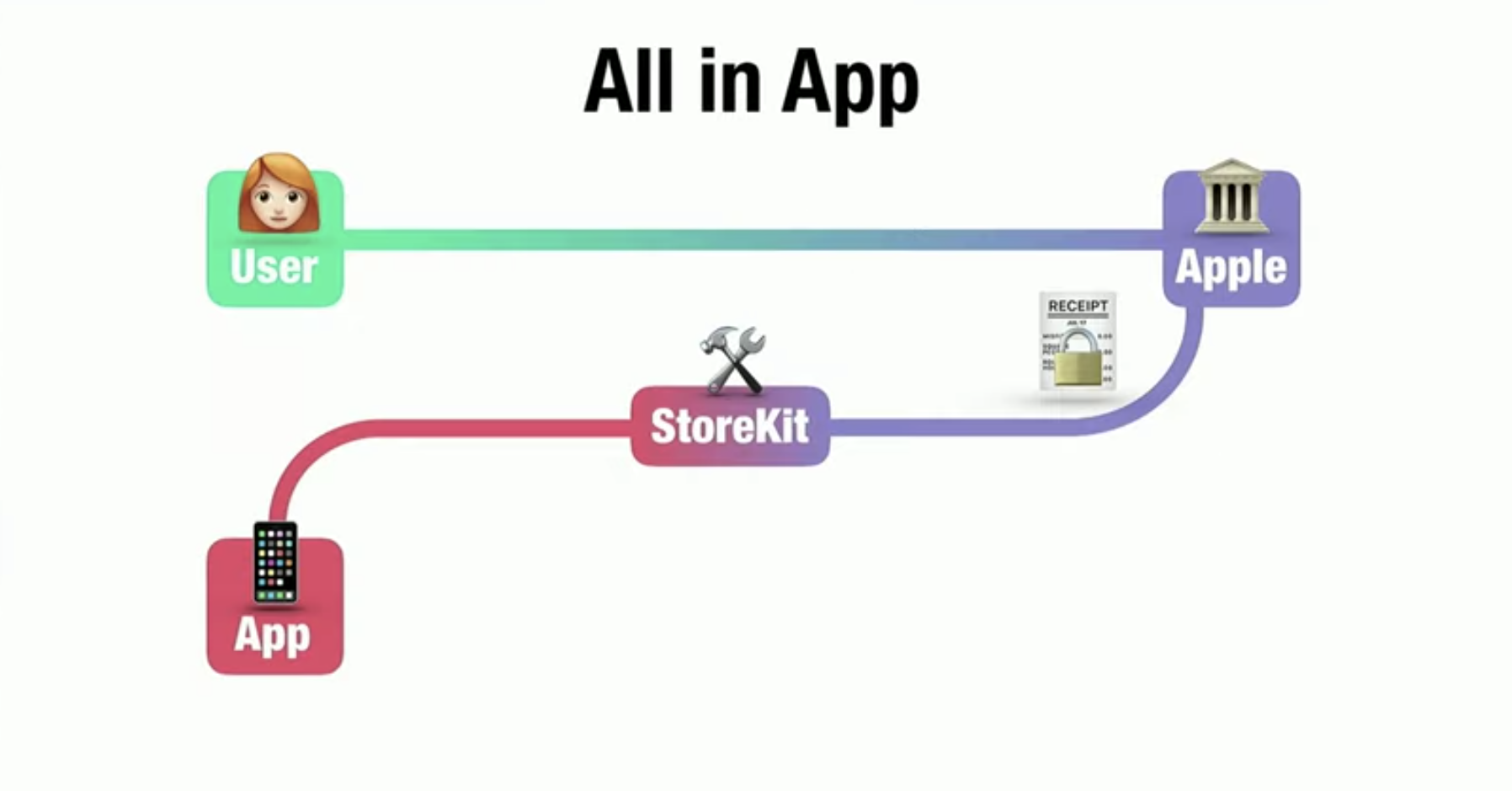
Task.output
Этот метод должен возвращать 1 или более Target объектов. Target объектом может быть файл на диске, файл внутри HDFS, S3 или файл, лежащий на удалённом FTP сервере и т.д.. В Luigi уже встроено множество полезных Target классов, поэтому ситуация, когда вам понадобится создавать свой, маловероятна. Полный список доступных Target классов смотрите на сайте.
Task.input
Этот метод не нужно переопределять. Он выступает «оберткой» над Task.requires и возвращает Target объекты, полученные от выполнения задач, определенных в Task.requires. Таким образом строится граф зависимостей, когда одна задача зависит от результата выполнения другой. Продемонстрирую на примере кода:
Здесь таск B зависит от выполнения таска A, поэтому перед началом выполнения B выполнится A, результат которого вернётся при вызове метода B.input (объекта файла result.txt).
Target
Ранее я вкратце описал что из себя представляет объект Target и зачем он нужен. Здесь отмечу, что благодаря этому классу Luigi реализует механизм fault tolerance и свойство идемпотентности. Проще говоря, если ваш pipeline аварийно завершается где-то в середине выполнения задач, повторный запуск не приведёт к повторному запуску успешно завершившихся задач, выполнение начнется в месте аварийной остановки скрипта. Это достигается за счёт вызова метода exists() у Target класса.
Parameter
При создании ETL скриптов часто приходится писать код для работы с командной строкой, а именно уметь принимать и обрабатывать аргументы. Даже наличие в стандартной библиотеке Python модулей для работы с консолью не уменьшает количество boilerplate кода. Luigi решил эту проблему по-своему.
Чтобы принимать аргументы из командной строки достаточно присвоить переменной объект класса Parameter или его наследников на уровне класса.
Пример запуска такого скрипта:
Если в названии вашего параметра присутствует знак ‘_’, то в командной строке его необходимо заменить на ‘-’. То есть передача значения в переменную file_name из командной строки будет выглядеть как —file-name. Параметр —local-scheduler необходим для запуска Luigi без центрального планировщика, в режиме тестирования и разработки.
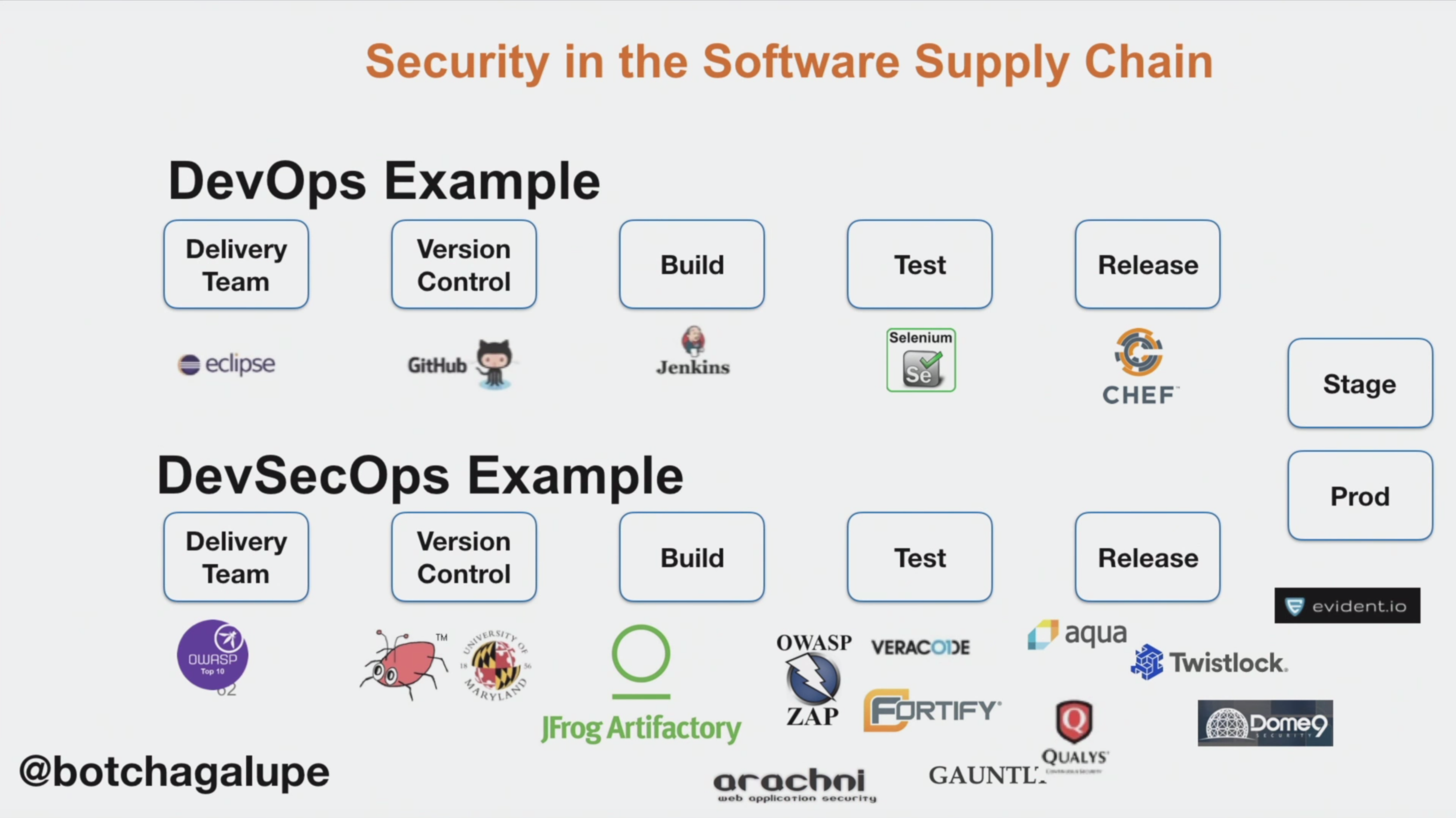
5 основных этапов построения конвейерной архитектуры DevOps
Теперь, когда мы разобрались «что такое конвейер DevOps?», отложим этот вопрос в сторону. Давайте узнаем о пяти основных последовательных шагах по реализации самого конвейера.
 Источник изображения: devclass.com
Источник изображения: devclass.com
Установка CI/CD Framework для создания идеального конвейера DevOps
Конвейер DevOps с Jenkins демонстрирует максимальную эффективность в настройке непрерывной интеграции программного обеспечения (путем постоянного подключения рабочих копий к общей линии разработки, а также реализации непрерывных автоматизированных сборок проекта). Благодаря этому ошибки обнаруживаются на ранних стадиях, и их становится намного легче устранять.
Кроме того, вы можете использовать платные, но более многофункциональные продукты, например, DevOps конвейер Azure или DevOps конвейер AWS. Их использование довольно дорого, но эти сервисы демонстрируют максимальную эффективность в крупных и масштабируемых проектах, когда существует потребность в облачном хостинге существующего программного решения.
Система управления версиями — это то, что формирует монолитное решение из отдельных битов кода. Такие системы являются своего рода ответом на одну из главных проблем в конвейере DevOps — проблемы с совместной работой нескольких команд над проектом и путаницу с ветвями кода и примечаниями к ним. Вместо этого эти решения предоставляют центральное хранилище с хорошо отслеживаемой структурой.
Кстати, Git изначально был создан для работы с Linux, поэтому именно в такой среде он работает быстрее всего. В настоящее время Git совместим со всеми Unix-подобными системами и требует предварительной установки пакета mSysGit для работы на платформе Windows.
Наконец, работая с Git, вы получаете доступ к полной истории разработки в автономном режиме, что является очень полезной функцией в полевых условиях работы над проектом.
Подключение инструмента автоматизации здания для оптимизации конвейера доставки DevOps
Такие инструменты позволяют конвейерному процессу DevOps автоматизировать компиляцию исходного кода компьютера в двоичный код, а также тестирование и развертывание в различных средах. Необходимость использовать их «исключительно для компиляции» не всегда присутствует, поскольку не все языки программирования нуждаются в компиляции.







Сервер веб-приложений отвечает за обеспечение доступа клиентов к бизнес-логике программных решений, повышая безопасность конвейера DevOps. Сервер веб-приложений обычно выделяется в качестве среднего звена в 3-уровневой клиент-серверной архитектуре, в которой первый уровень — это пользовательский интерфейс (обычно GUI), средний уровень — это исполняемый программный код, расположенный на выделенном сервере, и третий уровень — базы данных.
В сетевой среде сервер приложений является посредником между клиентским интерфейсом и серверами баз данных
Обратите внимание, что бизнес-логика может быть реализована на стороне сервера либо полностью (удаленный код), либо частично (распределенный код)
Тестирование кода для завершения конвейера DevOps
Это последний базовый компонент конвейера в DevOps, который помогает исправлять ошибки на ранних стадиях проекта и изначально повышать качество кода.
Более того, специализированные инструменты для автоматического тестирования в конвейере доставки в DevOps позволяют решать ряд задач, таких как:
- увеличенные затраты времени (тестовые случаи могут выполняться намного быстрее без непосредственного участия человека);
- человеческий фактор (который особенно актуален, когда необходимо обработать кучу идентичных тестовых случаев) и отсутствие графического пользовательского интерфейса (часто на ранних этапах разработки программного обеспечения отсутствует пользовательский интерфейс, и все выглядит как набор модулей и элементы для программирования);
- многопользовательский ввод для нагрузочного тестирования (невозможно эмулировать ввод нескольких тысяч пользователей, одновременно обращающихся к вашему решению для нагрузочного тестирования трафика).
Наконец, почти все инструменты AT имеют встроенные функции для регистрации ошибок и результатов, что позволяет имитировать различные ситуации с ошибками. Это может быть очень удобно в условиях ограниченного времени тестирования.
Технический блок
Движок (game engine) — фреймворк для создания игр. Я попросила друга-программиста объяснить мне доступным языком, цитирую: «Игровой движок — это куча-куча кода, в котором специально оставили «дырочки». В эти дырочки прикладные программисты вставляют свои куски кода по правилам, определенным разработчиком движка. В движке реализована куча-куча разных возможностей, это как погружной блендер — меняешь насадки(то, что в дырочках), меняется поведение. Движок — это кусок игры. То, что скомпилируется в бинарные файлы, скопируется на устройство и запустится».
Юнити (Unity) — один из наиболее популярных движков. На нем сделаны такие игры как Ori and the Blind Forest, Monument Valley и Cuphead.
Анрил (Unreal Engine) — так же популярный движок. От Unity отличается языками программирования.
Системы контроля версий (SVN, Git, etc.) — программы, позволяющие нескольким людям работать параллельно над проектом, добавляя изменения на сервер по мере разработки. С этим термином напрямую связаны «коммит», «пуш-пул», «работать в ветке», «репозиторий», но если вам ничего не говорят эти слова, лучшее решение — почитать документацию о работе с конкретной программой.
ETL
Аббревиатура ETL в последнее время часто мелькает в материалах, посвященных data-driven приложениям. Но не пугайтесь, это всего лишь набор из 3-х простых слов: Extract, Transform, Load. Ничего не напоминает? Тот, кто сталкивался с задачами по обработке данных не раз замечал паттерн в своих действиях, а именно:
-
сначала данные выгружаются (Extract) из какого-нибудь источника типа базы данных, внешнего сервиса (Facebook Ads, Google Analytics, Yandex Metrics) или, на худой конец, это могут быть логи вашего приложения (например, веб-сервера).
-
потом они преобразуются (Transform), скажем, необходимо сформировать сводную таблицу или провести сложный когортный анализ ваших пользователей.
-
и наконец загружаются (Load) для просмотра и дальнейшего анализа в базу данных или на какое-нибудь облако Amazon S3, не суть.
И как ни крути от этого не уйти. Чтобы данные проанализировать, их необходимо подготовить, иначе «мусор на входе — мусор на выходе». Процесс подготовки занимает львиную долю времени, отведенного на работу с данными. До 80% рабочего времени аналитик тратит на сбор и очистку. Поэтому от эффективности ETL-процесса зависит скорость и качество выполненной работы.








Перед тем как перейти к основной идеи этой статьи, я предлагаю кратко рассмотреть самый популярный на сегодняшний день метод построения ETL процесса в компании.
Есть и другие преимущества шаблона PipeReader
- Некоторые базовые системы поддерживают «ожидание без буферизации»: буфер не нужно выделять то тех пор, пока в базовой системе не появятся доступные данные. Так, в Linux с epoll можно не предоставлять буфер для считывания до тех пор, пока данные не будут подготовлены. Это позволяет избежать ситуации, когда имеется множество потоков, ожидающих данные, и требуется сразу же резервировать огромный объем памяти.
- Конвейер по умолчанию упрощает запись модульных тестов сетевого кода: логика синтаксического анализа отделена от сетевого кода, и модульные тесты запускают эту логику только в буферах в памяти, а не потребляют ее непосредственно из сети. Он также упрощает тестирование сложных шаблонов с отправкой частичных данных. ASP.NET Core использует его для проверки различных аспектов http-средств синтаксического анализа Kestrel.
- Системы, позволяющие пользовательскому коду задействовать основные буферы ОС (например, зарегистрированные API ввода-вывода Windows), изначально подходят для использования конвейеров, поскольку реализация PipeReader всегда предоставляет буферы.
Другие связанные типы
- MemoryPoolT, IMemoryOwnerT, MemoryManagerT. В .NET Core 1.0 был добавлен ArrayPoolT, а в .NET Core 2.1 теперь имеется более общее абстрактное представление для пула, который работает с любыми MemoryT. Мы получаем точку расширяемости, позволяющую осуществлять более продвинутые стратегии распределения, а также контролировать управление буферами (например, использовать предустановленные буферы вместо исключительно управляемых массивов).
- IBufferWriterT представляет собой приемник для записи синхронных буферизованных данных (реализуется PipeWriter).
- IValueTaskSource — ValueTaskT существует со времени выпуска .NET Core 1.1, но в .NET Core 2.1 приобрел чрезвычайно эффективные инструменты, обеспечивающие бесперебойные асинхронные операции без распределения. Дополнительную информацию см. здесь.
Классы игр

AAA-проект. Произносят как «трипл эй». Проект(игра) с высоким бюджетом именно на производство. Как правило ААА-игры выходят на PC и консолях, их графика — на острие технологий. Примеры игр: Uncharted, Detroit и God of War.

Alan Wake
AA-проект. Дабл эй проект. Игры, которые мимикрируют под высокобюджетные, но не дотягивают до титула трипл эй по качеству/бюджету/масштабности. Посмотрите вот эту и вот эту статью для большей информации.

Night in the Woods
Инди (indie games). Игры от независимых разработчиков. Т.е. ребята сначала сделали игру своими силами, а уже потом стали думать над изданием, тогда как обычно издатель спонсирует команду разработчиков. Или же игры, созданные с помощью краудфайндинга. В бытовом плане, когда говорят инди, скорее всего имеют в виду короткую игру с необычным артстилем и/или механикой. Примеры игр: Undertale, Witness, Night in the Woods.
Мидкор (mid-core) — игры средней сложности для искушенных игроков. Характерны довольно высоким порогом вхождения — ваша бабушка вряд ли осилит, ориентированы на мужчин от 25 до 45 лет. Отличный пример такой игры на мобилках — Clash Royale.
Казуалки (casual games) — игры с низким порогом вхождения. Приятная, чистая графика. В большинстве случаев нет насилия, все вокруг сверкает и ми-ми-ми. Это не значит, что игра «простая», на 2х тысячном уровне Candy Crush вы никогда не побьете вашу бабулю. Кривая сложности построена так, что она плавно нарастает, достигая заоблачных высот. Примеры: Homescapes, Township, Bubble Witch Saga.
Ещё статический анализ
Конечно, есть много инструментов статического анализа, предназначенных не конкретно для Android, а в целом для Java и Kotlin: PMD, FindBugs (заброшен, используйте SpotBugs), Checkstyle, Ktlink, Detekt и другие. Выберите себе по душе, интегрируйте его в свой пайплайн и обеспечьте его реальное использование (как именно? читайте дальше).
Пример отчёта от FindBugs
Но недостаточно наличия инструмента, предоставляющего данные о том, что надо поправить. Вам также пригодится следующая информация:
- Как изменяется со временем покрытие кода тестами?
- Сколько времени мне потребуется для исправления всех найденных проблем?
- Сколько в проекте дублирующегося кода?
- Как мне распространить свои правила на несколько команд?
И многие другие
Мы в EPAM Systems уделяем внимание качеству, поэтому выбрали SonarQube как инструмент для ответов на эти вопросы. О других преимуществах SonarQube можно узнать здесь
На сцену выходит Babel
Как только все три предложения были конкретизированы, мы пришли к выводу, что такие обсуждения не приведут к разрешению глубоких противоречий между предложениями. Мы решили, что лучший способ — собрать отзывы разработчиков, использующих предложения в реальном коде. С учётом роли Babel в сообществе разработчиков, мы решили добавить все три варианта в плагин оператора .



![Результаты поиска по запросу «[pipeline]» / хабр](https://rusinfo.info/wp-content/uploads/9/3/c/93cae2ebaf187a0fed0ac706870aacc8.jpeg)





Поскольку парсинг для всех трёх предложений незначительно, но отличается, их поддержка должна быть сначала добавлена в (который ), причём парсер должен знать, какое предложение нужно сейчас поддерживать. Таким образом плагин оператора требует опции , как для конфигурирования babylon для парсинга, так и для последующей трансформации.
Мы работали над этим в оперативном режиме, потому что нам надо сделать все изменения, ломающие обратную совместимость, до того, как babel@7 перестанет быть бетой. Мы бы хотели в итоге сделать один из вариантов пайплайнов дефолтным для плагина, чтобы избавиться от необходимости в конфигурационной опции.
Учитывая эти ограничения, мы решили добавить опцию в конфигурацию плагина и сделать её обязательной, принуждая пользователей решать, какое из предложений они хотят использовать в своём проекте. Как только конкретное предложение будет выбрано как каноническое поведение оператора, мы пометим опцию как устаревшую, а канонический вариант станет работать по-умолчанию. Поддержка отменённых предложений будет работать до следующей мажорной версии.
Итого о кросс-проектном пайплайне
Файл определяет порядок этапов CI/CD, какие задания выполнять и при каких условиях запускать или пропускать выполнение задания. Добавление ‘bridge job’ с ключевым словом в этот файл можно использовать для запуска кросс-проектных пайплайнов. Мы можем передавать параметры заданиям в нисходящих пайплайнах и даже определять ветку, которую будет использовать нисходящий пайплайн.
Пайплайны могут быть сложными структурами с множеством последовательных и параллельных задач, и, как мы только что узнали, иногда они могут запускать нисходящие пайплайны. Чтобы упростить понимание потока пайплайна, включая нисходящие пайплайны, в GitLab есть графики пайплайнов для просмотра пайплайнов и их статусов.
Также читайте другие статьи в нашем блоге:
- /etc/resolv.conf для Kubernetes pods, опция ndots:5, как это может негативно сказаться на производительности приложения
- Разбираемся с пакетом Context в Golang
- Три простых приема для уменьшения Docker-образов
- Бэкапы Stateful в Kubernetes
- Резервное копирование большого количества разнородных web-проектов
- Telegram-бот для Redmine. Как упростить жизнь себе и людям







