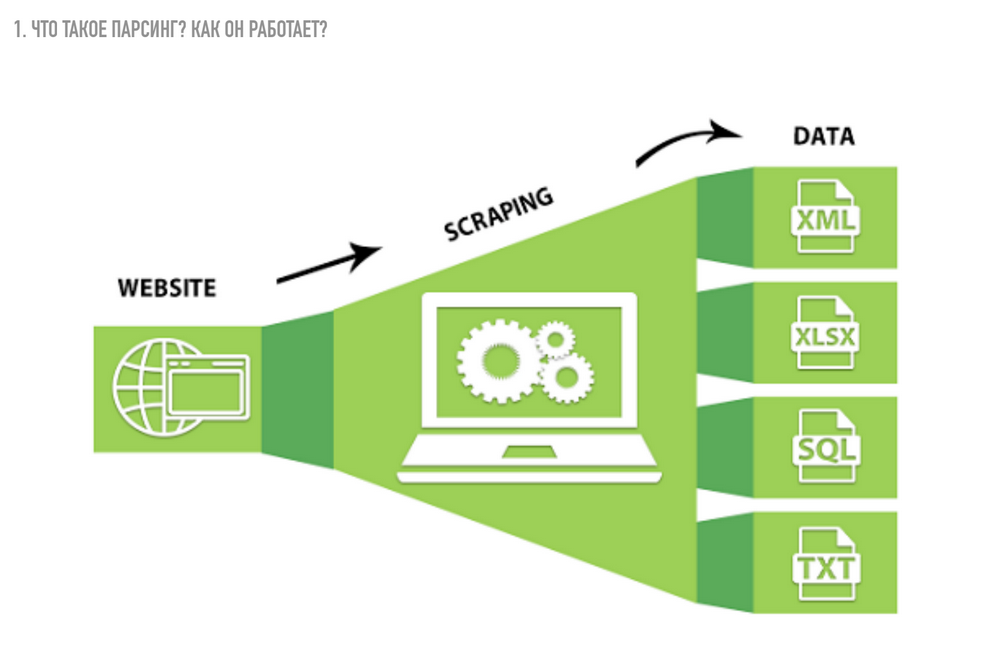
Основа работы парсера
Конечно же, парсеры не читают текста, они всего лишь сравнивают предложенный набор слов с тем, что обнаружили в интернете и действуют по заданной программе. То, как поисковый робот должен поступить с найденным контентом, написано в командной строке, содержащей набор букв, слов, выражений и знаков программного синтаксиса. Такая командная строка называется «регулярное выражение». Русские программисты используют жаргонные слова «маска» и «шаблон».
Чтобы парсер понимал регулярные выражения, он должен быть написан на языке, поддерживающем их в работе со строками. Такая возможность есть в РНР, Perl. Регулярные выражения описываются синтаксисом Unix, который хотя и считается устаревшим, но широко применяется благодаря свойству обратной совместимости.
Синтаксис Unix позволяет регулировать активность парсинга, делая его «ленивым», «жадным» и даже «сверхжадным». От этого параметра зависит длина строки, которую парсер копирует с веб-ресурса. Сверхжадный парсинг получает весь контент страницы, её HTML-код и внешнюю таблицу CSS.
Виды парсеров по сферам применения
Для организаторов СП (совместных покупок)
Есть специализированные парсеры для организаторов совместных покупок (СП). Их устанавливают на свои сайты производители товаров (например, одежды). И любой желающий может прямо на сайте воспользоваться парсером и выгрузить весь ассортимент.
Чем удобны эти парсеры:
- интуитивно понятный интерфейс;
- возможность выгружать отдельные товары, разделы или весь каталог;
- можно выгружать данные в удобном формате. Например, в Облачном парсере доступно большое количество форматов выгрузки, кроме стандартных XLSX и CSV: адаптированный прайс для Tiu.ru, выгрузка для Яндекс.Маркета и т. д.
Популярные парсеры для СП:
- SPparser.ru,
- Облачный парсер,
- Турбо.Парсер,
- PARSER.PLUS,
- Q-Parser.
Вот три таких инструмента:
- Marketparser,
- Xmldatafeed,
- ALL RIVAL.
Парсеры для быстрого наполнения сайтов
Такие сервисы собирают названия товаров, описания, цены, изображения и другие данные с сайтов-доноров. Затем выгружают их в файл или сразу загружают на ваш сайт. Это существенно ускоряет работу по наполнению сайта и экономят массу времени, которое вы потратили бы на ручное наполнение.
В подобных парсерах можно автоматически добавлять свою наценку (например, если вы парсите данные с сайта поставщика с оптовыми ценами). Также можно настраивать автоматический сбор или обновление данных по расписания.
Примеры таких парсеров:
- Catalogloader,
- Xmldatafeed,
- Диггернаут.
Особенности парсинга веб-сайтов
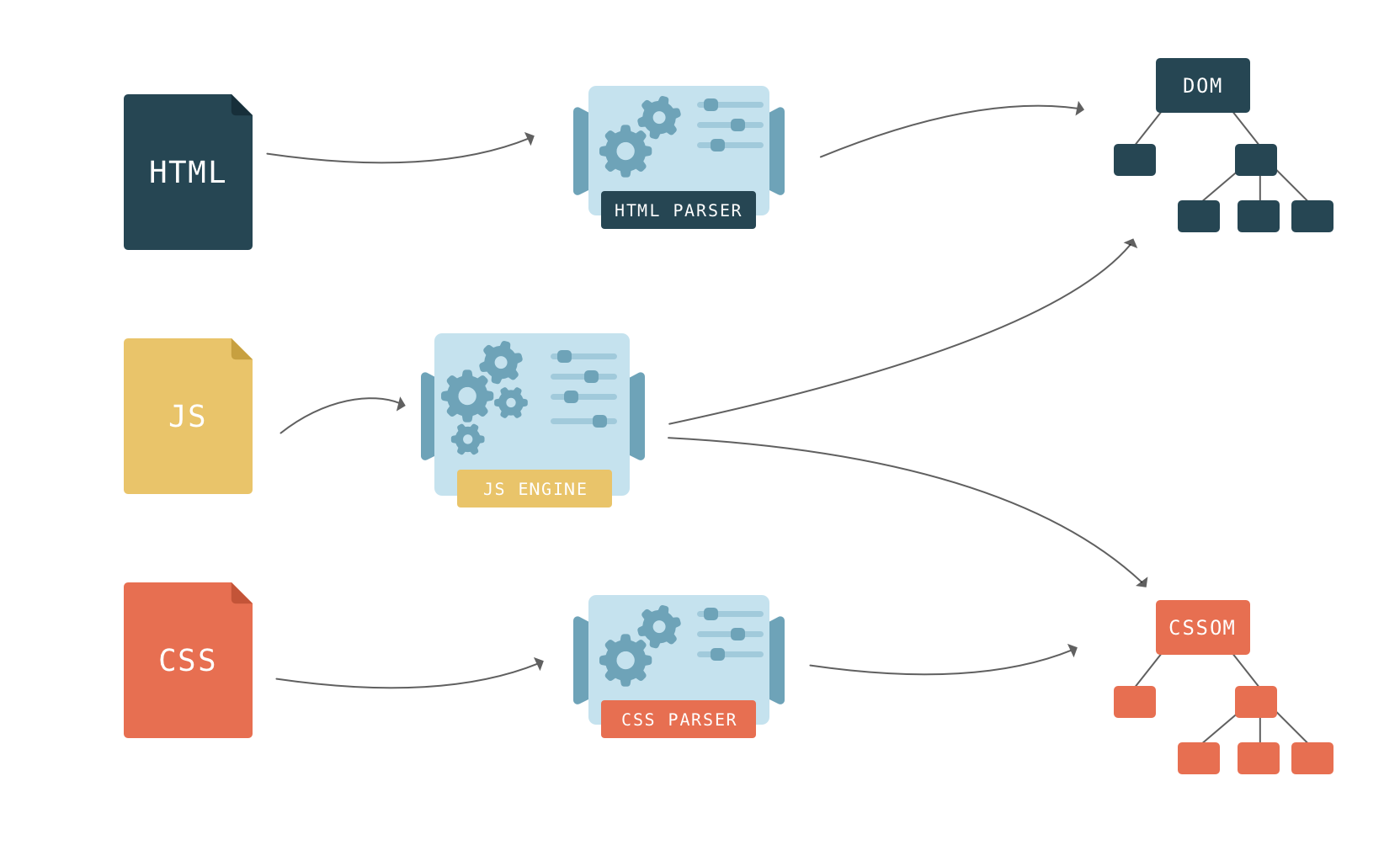
Одной из особенностей парсинга веб-сайтов является то, что как правило мы работаем с исходным кодом страницы, т.е. HTML кодом, а не тем текстом, который показывается пользователю. Т.е. при создании регулярного выражения grep нужно основываться на исходном коде, а не на результатах рендеринга. Хотя имеются инструменты и для работы с текстом, получающимся в результате рендеринга веб-страницы – об этом также будет рассказано ниже.
В этом разделе основной упор сделан на парсинг из командной строки Linux, поскольку это самая обычная (и привычная) среда работы для тестера на проникновение веб-приложений. Будут показаны примеры использования разных инструментов, доступных из консоли Linux. Тем не менее, описанные здесь приёмы можно использовать в других операционных системах (например, cURL доступна и в Windows), а также в качестве библиотеки для использования в разных языках программирования.
Подразумевается, что вы понимаете принципы работы командной строки Linux. Если это не так, то рекомендуется ознакомиться с циклом:
- Азы работы в командной строке Linux (часть 1)
- Азы работы в командной строке Linux (часть 2)
- Азы работы в командной строке Linux (часть 3)
Зачем нужны парсеры
Парсер — это программа, сервис или скрипт, который собирает данные с указанных веб-ресурсов, анализирует их и выдает в нужном формате.
С помощью парсеров можно делать много полезных задач:
Для справки. Есть еще серый парсинг. Сюда относится скачивание контента конкурентов или сайтов целиком. Или сбор контактных данных с агрегаторов и сервисов по типу Яндекс.Карт или 2Гис (для спам-рассылок и звонков). Но мы будем говорить только о белом парсинге, из-за которого у вас не будет проблем.
Где взять парсер под свои задачи
Есть несколько вариантов:
- Оптимальный — если в штате есть программист (а еще лучше — несколько программистов). Поставьте задачу, опишите требования и получите готовый инструмент, заточенный конкретно под ваши задачи. Инструмент можно будет донастраивать и улучшать при необходимости.
- Воспользоваться готовыми облачными парсерами (есть как бесплатные, так и платные сервисы).
- Десктопные парсеры — как правило, программы с мощным функционалом и возможностью гибкой настройки. Но почти все — платные.
- Заказать разработку парсера «под себя» у компаний, специализирующихся на разработке (этот вариант явно не для желающих сэкономить).
Первый вариант подойдет далеко не всем, а последний вариант может оказаться слишком дорогим.
Что касается готовых решений, их достаточно много, и если вы раньше не сталкивались с парсингом, может быть сложно выбрать. Чтобы упростить выбор, мы сделали подборку самых популярных и удобных парсеров.
Законно ли парсить данные?
В законодательстве РФ нет запрета на сбор открытой информации в интернете. Право свободно искать и распространять информацию любым законным способом закреплено в четвертом пункте 29 статьи Конституции.





![Результаты поиска по запросу «[парсинг сайтов]» / хабр](https://rusinfo.info/wp-content/uploads/8/c/2/8c2e14b854898c56d318ed52c32a41b9.jpg)


Допустим, вам нужно спарсить цены с сайта конкурента. Эта информация есть в открытом доступе, вы можете сами зайти на сайт, посмотреть и вручную записать цену каждого товара. А с помощью парсинга вы делаете фактически то же самое, только автоматизированно.
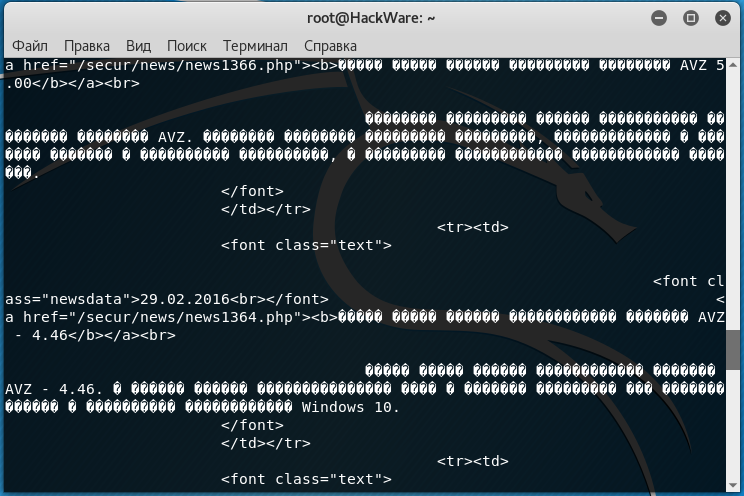
Неправильная кодировка при использовании cURL
В настоящее время на большинстве сайтов используется кодировка UTF-8, с которой cURL прекрасно работает.
Но, например, при открытии некоторых сайтов:
curl http://z-oleg.com/
Вместо кириллицы мы увидим крякозяблы:
Кодировку можно преобразовать «на лету» с помощью команды iconv. Но нужно знать, какая кодировка используется на сайте. Для этого обычно достаточно заглянуть в исходный код веб-страницы и найти там строку, содержащую слово charset, например:
<meta http-equiv="Content-Type" content="text/html; charset=utf-8">
Эта строка означает, что используется кодировка windows-1251.
Для преобразования из кодировки windows-1251 в кодировку UTF-8 с помощью iconv команда выглядит так:
iconv -f windows-1251 -t UTF-8
Совместим её с командой curl:
curl http://z-oleg.com/ | iconv -f windows-1251 -t UTF-8
После этого вместо крякозяблов вы увидите русские буквы.
Как парсить данные
Для парсинга данных можно выбрать один из двух форматов:
- воспользоваться специальными программами, которых на рынке существует немало;
- написать их самостоятельно. Для этого может применяться практически любой язык программирования, например, PHP, C++, Python/
Если требуется не вся информация по странице, а только что-то определенное (наименования товаров, характеристики, цена), используется XPath.
XPath – это язык, на котором формируются запросы к XML-документам и их отдельным элементам.
С помощью его команд необходимо определить границы будущего парсинга, то есть задать как парсить данные с сайта — полностью или выборочно.
Чтобы определить XPath конкретного элемента необходимо:
- Перейти на страницу любого товара на анализируемом сайте.
- Выделить цену и щелкнуть по выделению правой кнопкой мыши.
- В открывшемся окне выбрать пункт «Посмотреть код».
- После появления с правой стороны экрана кода, нажать на три точки с левой стороны от выделенной строки.
- В меню выбрать пункт “Copy”, затем “Copy XPath”.
Как спарсить цену
Задаваясь вопросом «Парсинг товаров — что это?», многие подразумевают именно возможность провести ценовую разведку на сайтах конкурентов. Цены парсят чаще всего и действовать необходимо следующим образом. Скопированный в примере выше код ввести в программу-парсер, которая подтянет остальные данные на сайте, соответствующие ему.
Чтобы парсер не ходил по всем страницам и не пытался найти цены в статьях блога, лучше задать диапазон страниц. Для этого необходимо открыть карту XML (добавить “/sitemap.xml” в адресную строку сайта после названия). Здесь можно найти отсылки к разделам с ценами — обычно это товары (products) и категории (categories), хотя называться они могут и по-другому.
Как спарсить характеристики товаров
Здесь всё достаточно просто. Определяются коды XPath для каждого элемента, после чего они вносятся в программу. Так как технические характеристики у одинаковых товаров будут совпадать, можно настроить автозаполнение своего сайта на основе полученной информации.
Процесс сбора отзывов на других сайтах с целью переноса их к себе вначале выглядит похожим образом. Необходимо определить XPath для элемента. Однако далее возникают сложности. Часто дизайн выполнен так, что отзывы появляются на странице именно в тот момент, когда пользователь прокручивает её до нужного места.
В этом случае необходимо изменить настройки программы в пункте Rendering и выбрать JavaScript. Так парсер будет полностью воспроизводить сценарий движения по странице обычного пользователя, а отзывы получит путём выполнения скриншота.










Как парсить структуру сайта
Парсинг структуры — полезное занятие, поскольку помогает узнать, как устроен сайт конкурентов. Для этого необходимо проанализировать хлебные крошки (breadcrumbs):
- Навести курсор на любой элемент breadcrumbs;
- Нажать правую кнопку мыши и повторить действия по копированию XPath.
Далее действие необходимо выполнить для других элементов структуры.
Что делает парсер?
Ответить на вопрос, что делает парсер довольно просто. Механизм в соответствии с программой сверяет конкретный набор слов с тем, что нашлось в интернете. Дальнейшее действие касательно полученной информации будет задано в командной строке.

Стоит отметить, что программное обеспечение может иметь разные форматы представления, стилистику оформления, варианты доступности, языки и многое другое. Здесь, как и в тарифах контекстной рекламы имеет место быть большое количество возможных вариаций.
Работа всегда происходит в несколько этапов. Сначала происходит поиск сведений, загрузка и скачивание. Далее значения извлекаются из кода вэб-страницы так, что материал отделяется от программного кода страницы. В итоге формируется отчет в соответствии с заданными требованиями напрямую в базу данных или сохраняется в текстовой файл.
Парсер сайта дает много преимуществ при работе с массивами данных. Например, высокую скорость обработки материалов и их анализ даже в огромном объеме. Также автоматизируется процесс отбора сведений. Однако отсутствие своего контента негативно сказывается на SEO.
Зачем нужен парсинг?
Сбор информации в интернете – трудоемкая, рутинная, отнимающая много времени работа. Парсеры, способные в течение суток перебрать большую часть веб-ресурсов в поисках нужной информации, автоматизируют ее.
Наиболее активно «парсят» всемирную сеть роботы поисковых систем. Но информация собирается парсерами и в частных интересах. На ее основе, например, можно написать диссертацию. Парсинг используют программы автоматической проверки уникальности текстовой информации, быстро сравнивая содержимое сотен веб-страниц с предложенным текстом.
Возможностью «спарсить» чужой контент для наполнения своего сайта пользуются многие веб-мастера и администраторы сайтов. Это оправдано, если требуется часто изменять контент для представления текущих новостей или другой, быстро меняющейся информации.
Парсинг – «палочка-выручалочка» для организаторов спам-рассылок по электронной почте или каналам мобильной связи. Для этого им надо запустить «бота» путешествовать по социальным сетям и собирать «телефоны, адреса, явки».
Ну и хозяева некоторых, особенно недавно организованных веб-ресурсов, любят наполнить свой сайт чужим контентом. Правда, они рискуют, поскольку поисковые системы быстро находят и банят любителей копипаста.
Быстрый парсинг всех ключевых слов и объявлений для указанных доменов
Создайте аккаунт в системе PromoPult (или авторизуйтесь, если у вас уже есть аккаунт). Откройте инструмент «Слова и объявления конкурентов». В блоке «Добавить задачу» укажите домены конкурентов или загрузите их с помощью XLSX-файла.
Блок профессиональных настроек пока не трогаем (мы еще разберем его).
В блоке «Поисковые системы» можно выбрать, в какой поисковой системе проверять домены. По умолчанию это Яндекс и Google. Также по умолчанию стоит галочка на пункте «Результаты на едином листе XLS» — в таблице с результатами данные по всем доменам будут сведены на одном листе.
Если вы проверяете небольшое количество доменов (до 5), можете ничего не менять здесь. Если же доменов больше, уберите галочку с этого пункта. В результатах парсинга под каждый домен будет создан отдельный лист — это удобнее для анализа большого количества данных.
Жмем «Запустить проверку». Система начнет парсинг доменов (в нашем случае на это ушло 5 минут). Если у вас нет времени ждать, вы можете закрыть страницу с инструментом — все работы проводятся в фоновом режиме.








После окончания проверки вам на почту придет уведомление:
Раскройте блок «Список задач» и кликните по пиктограмме Excel-таблицы, чтобы скачать отчет. Также здесь можно удалить отчет или запустить повторный парсинг.
В настройках парсинга есть возможность выбрать отображение отчета: отдельный лист для каждого домена или все на одном листе.
В зависимости от этой настройки отчет будет выглядеть по-разному.
Отчет по каждому домену на разных листах
В нашем примере мы получили именно такой отчет. При скачивании загружается архив с файлами в формате CSV:
Что содержит архив:
Обратите внимание! При парсинге объявления собираются из результатов поисковой выдачи в таком виде, в котором они отображаются. Кроме основного текста и заголовка могут собираться уточнения, быстрые ссылки и другие расширения (если они есть в объявлении)
Данные по доменам на одном листе
При таком способе отображения отчета загружается один XLSX-файл с четырьмя листами. Даже если вы парсите 50 доменов, листов в файле все равно будет четыре. Какие это листы:
- «Слова и объявления». На этом листе собрана семантика по всем конкурентам и тексты объявлений. Данные указаны по каждому региону и поисковой системе. Если доменов много, работать с такой таблицей будет неудобно.
- «Слова». Собраны уникальные ключевики по всем доменам.
- «Исх. настройки». Указаны настройки парсинга.
Процесс парсинга
Чтобы понять, как развивался Хабр, нужно было обойти по все его статьи и выделить из них метаинформацию (например, даты). Обход дался легко, потому что ссылки на все статьи имеют вид «habrahabr.ru/post/337722/», причём номера задаются строго по порядку. Зная, что последний пост имеет номер чуть меньше 350 тысяч, я просто прошёлся по всем возможным id документов циклом (код на Python):
Функция пытается загружает страницу с соответствующим id и пытается вытащить из структуры html содержательную информацию.
В процессе парсинга открыл для себя несколько новых моментов.
Во-первых, говорят, что создавать больше процессов, чем ядер в процессоре, бесполезно. Но в моём случае оказалось, что лимитирующий ресурс — не процессор, а сеть, и 100 процессов отрабатывают быстрее, чем 4 или, скажем, 20.
Во-вторых, в некоторых постах встречались сочетания спецсимволов — например, эвфемизмы типа «%&#@». Оказалось, что , который я использовал сначала, реагирует на комбинацию болезненно, считая её началом html-сущности. Я уж было собирался творить чёрную магию, но на форуме подсказали, что можно просто поменять парсер.








«Живых» статей оказалась только половина от потенциального максимума — 166307 штук. Про остальные Хабр даёт варианты «страница устарела, была удалена или не существовала вовсе». Что ж, всякое бывает.
За выгрузкой статей последовала техническая работа: например, даты публикации нужно было перевести из формата «’21 декабря 2006 в 10:47» в стандартный , а «12,8k» просмотров — в 12800. На этом этапе вылезло ещё несколько казусов. Самый весёлый связан с подсчётом голосов и типами данных: в некоторых старых постах произошло переполнение инта, и они получили по 65535 голосов.
В результате тексты статей (без картинок) заняли у меня 1.5 гигабайта, комментарии с метаинформацией — ещё 3, и около сотни мегабайт — метаинформация о статьях. Такое можно полностью держать в оперативной памяти, что было для меня приятной неожиданностью.
Начал анализ статей я не с самих текстов, а с метаинформации: дат, тегов, хабов, просмотров и «лайков». Оказалось, что и она может многое поведать.
Что такое парсинг сайтов: польза и вред
Открыто говорить о том, что «парсят» конкурентов, люди обычно стесняются. При том, что далеко не каждый имеет четкое представление о том, что такое парсинг, в обществе он считается занятием несколько стыдным, и публично порицается. И однако, парсингом занимаются все.
А если и не все поголовно, то все крупные акулы рынка точно.
В веб-программировании процесс обработки и представления данных зовется красивым словом – парсинг. Что это такое простыми словами? По сути – автоматизированный сбор разрозненной информации с сайтов, ее сортировка и выдача в форме структуры (например, таблицы). Сбор данных с сайтов ведет специальная программа – парсер.
Создание программы
Чтобы создать программу парсинга не нужно быть гуру программирования – достаточно усвоить моменты:
При создании алгоритма действий для программы важно внимательно изучить код web-страницы, которая числится донором. Да, здесь нужны хотя бы средние знания о том, что такое верстка и с чем ее едят
Знакомы слова CSS, HTML, JavaScript? Отлично, двигаемся дальше. Для тех, кому этого мало есть вариант глубокого изучения – DOM. Фишка технологии в возможности работы с иерархией web-страниц. Ну и конечно, само написание парсера. Здесь нужны владения навыком обработки текста.

CSS, HTML, JavaScript
Предположим, что программа уже есть и самое время начать работу.
Защита от парсинга
Нормальным желанием любого владельца интернет-ресурса станет защита информации, размещенной на сайте. При наполнении сайта контентом, разработанным собственными силами, его заимствование может быть крайне неприятным. Существует несколько способов борьбы с нежелательным парсингом.
Разграничение прав доступа. Информация о структуре сайта скрывается от роботов и остается доступной только для администрации. Это наиболее простой способ защиты информации.
Черные и белые списки. Пользователи, которые пытаются украсть контент, отправляются в списки нежелательных, в соответствии с чем к ним применяются установленные санкции.
Временная задержка между запросами. Парсинг отличается направлением постоянных хаотических запросов. Установка временной задержки для обращений, отправляемых с одного компьютера, позволит ограничить доступ к информации.
Различные методы защиты от роботов. Установка на сайте авторизации, которую может пройти только человек (ввод капчи, подтверждение регистрации и другие способы).



![Результаты поиска по запросу «[парсинг сайтов]» / хабр](https://rusinfo.info/wp-content/uploads/1/1/d/11d896755498192ee1e1c9881eb1b679.png)






Получение в cURL страниц со сжатием
Иногда при использовании cURL появляется предупреждение:
Warning: Binary output can mess up your terminal. Use "--output -" to tell Warning: curl to output it to your terminal anyway, or consider "--output Warning: <FILE>" to save to a file.
Его можно увидеть, например при попытке получить страницу с kali.org,
curl https://www.kali.org/
Суть сообщения в том, что команда curl выведет бинарные данные, которые могут навести бардак в терминале
Нам предлагают использовать опцию «—output -» (обратите внимание на дефис после слова output – он означает стандартный вывод, т.е. показ бинарных данных в терминале), либо сохранить вывод в файл следующим образом: «—output «.
Причина в том, что веб-страница передаётся с использованием компрессии (сжатия), чтобы увидеть данные достаточно использовать опцию —compressed:
curl --compressed https://www.kali.org/
В результате будет выведен обычный HTML код запрашиваемой страницы.
Парсеры сайтов по способу доступа к интерфейсу
Облачные парсеры
Облачные сервисы не требуют установки на ПК. Все данные хранятся на серверах разработчиков, вы скачиваете только результат парсинга. Доступ к программному обеспечению осуществляется через веб-интерфейс или по API.
Примеры облачных парсеров с англоязычным интерфейсом:
- http://import.io/,
- Mozenda (есть также ПО для установки на компьютер),
- Octoparce,
- ParseHub.
Примеры облачных парсеров с русскоязычным интерфейсом:
- Xmldatafeed,
- Диггернаут,
- Catalogloader.
У всех сервисов есть бесплатная версия, которая ограничена или периодом использования, или количеством страниц для сканирования.
Программы-парсеры
ПO для парсинга устанавливается на компьютер. В подавляющем большинстве случаев такие парсеры совместимы с ОС Windows. Обладателям mac OS можно запускать их с виртуальных машин. Некоторые программы могут работать со съемных носителей.
Примеры парсеров-программ:
- ParserOK,
- Datacol,
- SEO-парсеры — Screaming Frog, ComparseR, Netpeak Spider и другие.
Варианты разбора
- Решать задачу в лоб, то есть анализировать посимвольно входящий поток и используя правила грамматики, строить АСД или сразу выполнять нужные нам операции над нужными нам компонентами. Из плюсов — этот вариант наиболее прост, если говорить об алгоритмике и наличии математической базы. Минусы — вероятность случайной ошибки близка к максимальной, поскольку у вас нет никаких формальных критериев того, все ли правила грамматики вы учли при построении парсера. Очень трудоёмкий. В общем случае, не слишком легко модифицируемый и не очень гибкий, особенно, если вы не имплементировали построение АСД. Даже при длительной работе парсера вы не можете быть уверены, что он работает абсолютно корректно. Из плюс-минусов. В этом варианте все зависит от прямоты ваших рук. Рассказывать об этом варианте подробно мы не будем.
- Используем регулярные выражения! Я не буду сейчас шутить на тему количества проблем и регулярных выражений, но в целом, способ хотя и доступный, но не слишком хороший. В случае сложной грамматики работа с регулярками превратится в ад кромешный, особенно если вы попытаетесь оптимизировать правила для увеличения скорости работы. В общем, если вы выбрали этот способ, мне остается только пожелать вам удачи. Регулярные выражения не для парсинга! И пусть меня не уверяют в обратном. Они предназначены для поиска и замены. Попытка использовать их для других вещей неизбежно оборачивается потерями. С ними мы либо существенно замедляем разбор, проходя по строке много раз, либо теряем мозговые клеточки, пытаясь измыслить способ удалить гланды через задний проход. Возможно, ситуацию чуть улучшит попытка скрестить этот способ с предыдущим. Возможно, нет. В общем, плюсы почти аналогичны прошлому варианту. Только еще нужно знание регулярных выражений, причем желательно не только знать как ими пользоваться, но и иметь представление, насколько быстро работает вариант, который вы используете. Из минусов тоже примерно то же, что и в предыдущем варианте, разве что менее трудоёмко.
- Воспользуемся кучей инструментов для парсинга BNF! Вот этот вариант уже более интересный. Во-первых, нам предлагается вариант типа lex-yacc или flex-bison, во вторых во многих языках можно найти нативные библиотеки для парсинга BNF. Ключевыми словами для поиска можно взять LL, LR, BNF. Смысл в том, что все они в какой-то форме принимают на вход вариацию BNF, а LL, LR, SLR и прочее — это конкретные алгоритмы, по которым работает парсер. Чаще всего конечному пользователю не особенно интересно, какой именно алгоритм использован, хотя они имеют определенные ограничения разбора грамматики (остановимся подробнее ниже) и могут иметь разное время работы (хотя большинство заявляют O(L), где L — длина потока символов). Из плюсов — стабильный инструментарий, внятная форма записи (БНФ), адекватные оценки времени работы и наличие записи БНФ для большинства современных языков (при желании можно найти для sql, python, json, cfg, yaml, html, csv и многих других). Из минусов — не всегда очевидный и удобный интерфейс инструментов, возможно, придется что-то написать на незнакомом вам ЯП, особенности понимания грамматики разными инструментами.
- Воспользуемся инструментами для парсинга PEG! Это тоже интересный вариант, плюс, здесь несколько побогаче с библиотеками, хотя они, как правило, уже несколько другой эпохи (PEG предложен Брайаном Фордом в 2004, в то время как корни BNF тянутся в 1980-е), то есть заметно моложе и хуже выглажены и проживают в основном на github. Из плюсов — быстро, просто, часто — нативно. Из минусов — сильно зависите от реализации. Пессимистичная оценка для PEG по спецификации вроде бы O(exp(L)) (другое дело, для создания такой грамматики придется сильно постараться). Сильно зависите от наличия/отсутствия библиотеки. Почему-то многие создатели библиотек PEG считают достаточными операции токенизации и поиска/замены, и никакого вам AST и даже привязки функций к элементам грамматики. Но в целом, тема перспективная.
Синтаксический анализатор
- Легкость расширения при изменении грамматики
- Возможность описывать подробные сообщения об ошибках
- Возможность заглядывать вперед на неограниченное количество позиций
- Автоматическое отслеживание положения в исходном коде
- Лаконичность, близость к исходной грамматике
- Описание — один конкретный узел:
- Повторение — один конкретный узел повторяется многократно, возможно с разделителем:
- Альтернатива — выбор из нескольких узлов
— Как это, просто вызываются по порядку? А как же опережающие проверки? Например, так:
- Первой вызывается альтернатива .
- Идентификатор успешно совпадает.
- Дальше идет точка, а ожидается знак «равно». Однако с идентификатора могут начинаться и другие правила, поэтому ошибка не выбрасывается.
- Правило assign откатывает состояние назад и пробует дальше.
- Вызывается альтернатива .
- Идентификатор и точка успешно совпадают. В грамматике нет других правил, которые начинаются с идентификатора и точки, поэтому дальнейшие ошибки не имеет смысл пытаться обработать откатыванием состояния.
- Число не является идентификатором, поэтому выкидывается ошибка.
- Откат состояния — очень дешевая операция
- Легко управлять тем, до куда можно откатываться
- Легко отображать детальные сообщения об ошибках
- Не требуются никакие внешние библиотеки
- Небольшой объем генерируемого кода
- Реализация парсера вручную занимает время
- Сложность написания и оптимальность работы зависят от качества грамматики
- Леворекурсивные грамматики следует разруливать самостоятельно
Для чего нужен парсинг
Парсинг позволяет в кротчайшие сроки обработать большие объемы информации. Так обозначают структурированную синтаксическую оценку данных, выложенных на интернет-страницах. Таким образом парсинг существенно эффективнее ручного труда, требующего много времени и сил.
Парсеры имеют следующие возможности:
- Обновление данных, позволяющих иметь самую свежую информацию (курс валют, новости, прогноз погоды).
- Сбор и моментальное дублирование материала с других сайтов, для выкладки на своем интернет-проекте. Материал, полученный посредством парсинга, как правило подвергается рерайтингу.
- Соединение потоков данных. Происходит получение огромного количества сведений с разных ресурсов, что очень удобно при наполнении новостных сайтов.
- Парсинг существенно ускоряет работу с ключевыми словами или фразами. Благодаря этому становится возможным быстро выбирать необходимые запросы для раскрутки проекта.
Выбираем модель
- Скорость работы. Наш парсер должен работать достаточно быстро. Синтаксис, разумеется, далеко не единственный модуль «под капотом» real-time системы, поэтому тратить на него больше десятка миллисекунд не стоит.
- Качество работы. Как минимум, самого парсера именно на данных русского языка. Требование очевидное. Для русского языка у нас есть достаточно хорошие морфологические анализаторы, которые могут встроиться в нашу пирамиду. Если мы сможем убедиться, что сам парсер без морфологии круто работает, то это нас устроит — морфологию подсунем потом.
- Наличие кода обучения и желательно модели в открытом доступе. При наличии кода обучения мы будем способны повторить результаты автора модели. Для этого они должны быть открыты. И, кроме того, нужно внимательно следить за условиями распространения корпусов и модели — придется ли нам, если мы будем их использовать в рамках своих алгоритмов, покупать лицензию на их использование?
- Запуск без сверхусилий. Этот пункт очень субъективный, но важный. Что это значит? Это значит, что если мы три дня сидим и что-то запускаем, а оно не запускается, то выбрать этот парсер мы не сможем, даже если там будет идеальное качество.







