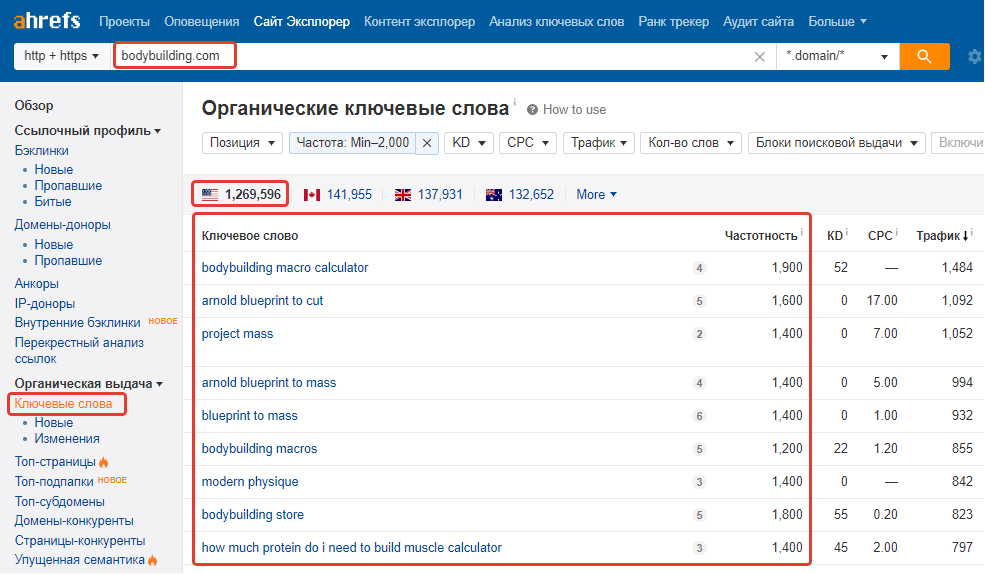
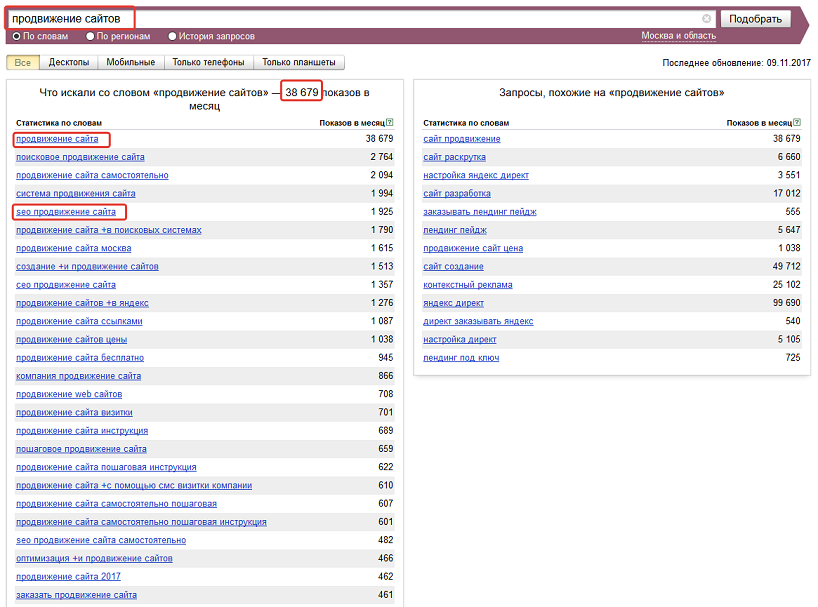
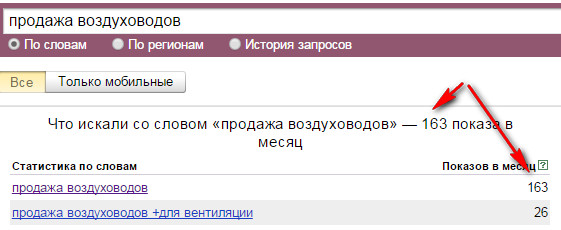
Текст страницы
Сегодня поисковые системы ценят структурированность и полноту контента на странице — читабельность текста, изображения, видео
Причем при распределении «веса» конкретных элементов страницы поисковики стараются имитировать человеческое поведение — уделяют большее внимание контенту в центральной части страницы (по сравнению боковыми блоками).. Именно там следует расположить заголовки и основной текст, в которых можно и нужно использовать ключевые слова
Вот несколько советов, как это делать правильно.
Именно там следует расположить заголовки и основной текст, в которых можно и нужно использовать ключевые слова. Вот несколько советов, как это делать правильно.
Заголовки
Важно соблюдать последовательность заголовков h (h1 — основной заголовок, h2 и h3 − подзаголовки). H1 должен быть только один
Пишите короткие информационные заголовки.
Заголовок h1 должен передавать основную тему страницы: прочитав его, пользователь должен понимать, куда он попал. Чаще всего основная часть заголовка h1 содержит высокочастотный запрос, продвигающийся на данной странице, например категорию товаров/услуг, название модели и т. п.
Заголовки h2, h3 и т. д
помогают раскрыть тему страницы, структурировать информацию и обратить внимание читателя на особенности товаров или услуг, которые вы предлагаете. Они также важны для продвижения, поэтому их желательно наполнять не только смыслом, но и по возможности ключевыми словами.
Основной текст
Текст должен быть уникальным, за исключением случаев, когда сделать это сложно или невозможно (например, трудно сделать уникальными описания технических характеристик товаров, вставки из законодательных актов или медицинских исследований и т. п.) Проверить тексты можно на сервисах антиплагиата, например, Etxt.
Не должно быть неестественных с точки зрения русского языка вхождений и частых повторов слов. Используйте в описании товаров и услуг не только ключевые фразы, но и синонимы. За счет них можно «зацепить» больше людей из поиска, т. к. пользователи формулируют запросы по-разному.
Если вы предоставляете услуги в конкретном городе, не стоит об этом многократно упоминать в тексте. Региональность сайту нужно присваивать в сервисах для веб-мастеров Google и «Яндекс». Этого вполне достаточно для правильного ранжирования.
Сколько раз упоминать ключевые слова в тексте
Если вы продвигаетесь по позициям, это определяется индивидуально, на основе анализа конкурентов и с помощью экспериментов. Если после оптимизации текста ваша страница вылетела за 100-ю позицию в поиске, возможно, следует удалить часть вхождений.
При трафиковом продвижении бывает достаточно одного упоминания каждого слова (а точнее, его исходной формы — леммы), причем морфологическая форма запросов может быть любая. За счет этого текст выглядит естественно и обладает всеми необходимыми характеристиками, которые учитывают поисковики при ранжировании.
Важно: у некоторых конкурентов может быть переспамленный текст, но они будут находиться в ТОПе за счет высоких показателей по другим факторам ранжирования, таким как возраст сайта, количество страниц, трафик и др. Это также следует учитывать при определении необходимого количества ключевых слов на странице и не равняться на старые домены.
Регион
Первое, про что все часто забывают, – это выбор региона при съеме частотности. Ни один коммерческий сайт не может продвигаться сразу по всем регионам, если он, конечно, не имеет офисы в каждом из них. Поэтому частотность снимается именно по тому региону, где находится офис компании. Если регионов несколько – отмечаем их все.
Например, компания, которая специализируется на поставках металлоконструкций и металлопроката, имеет офис в Москве, который добавлен в Яндекс.Справочник. Таким образом, ни по каким другим регионам данный сайт ранжироваться не будет, поэтому и ориентироваться надо в первую очередь на посетителей из Москвы. Значит, в wordstat нужно выставить соответствующий регион: Москва.Ключевой момент – наличие организации в Яндекс.Справочнике, так как именно по нему происходит привязка региона сайту.

Иногда клиенты нам говорят:
Как проверить частотность запроса
Частотность ключевых слов можно узнать с помощью соответствующих сервисов поисковых систем, а также специальных программ по составлению семантического ядра. Поисковики предоставляют свои сервисы с расчетом подбора запросов для контекстной рекламы.
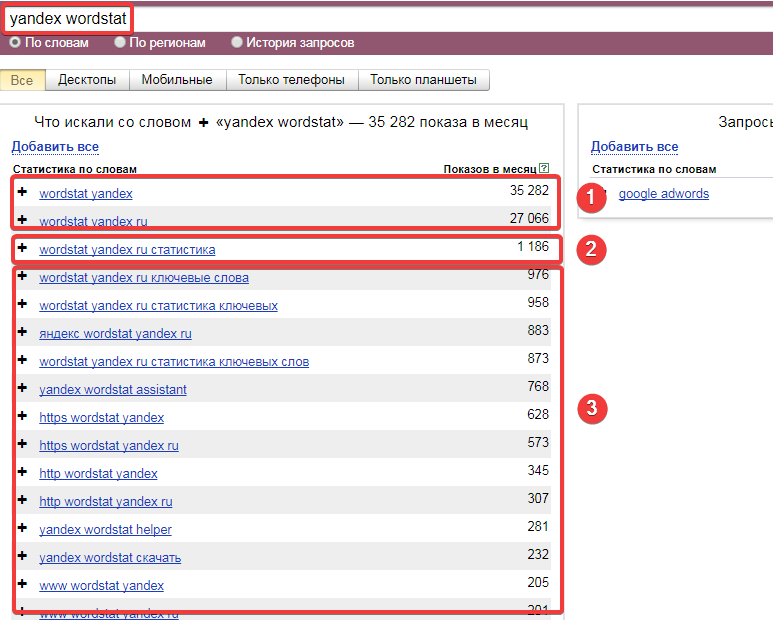
Wordstat (Яндекс)
Wordstat — cервис Яндекса по определению статистики ключевых запросов. Вордстат использует большинство оптимизаторов не только в целях составления коммерческих запросов под рекламу, но и для добычи ключевых слов в рамках обычной текстовой оптимизации. У Вордстата выделяют три вида частотностей:
- Частотность WS — базовая частотность запроса в Вордстате.
- Частотность «» WS — частотность по точному вводу запроса. Например, статистика по запросу будет соответствовать запросу без добавлений других слов.
- Частотность «!» WS — частотность по точному вводу каждого слова в запросе, исключая склонения и т.п. Запрос означает, что будет выдана статистика по слову без возможных склонений (китайская, китайское).
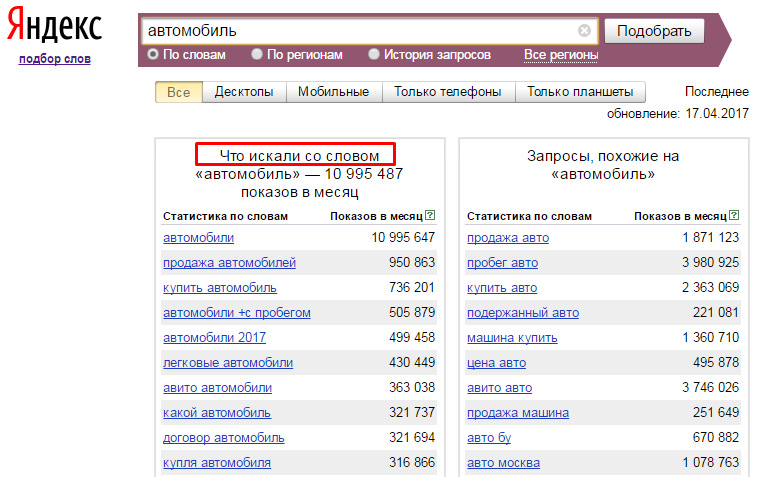
По запросу текущая частотность превышает десять миллионов показов. Однако базовый показатель предполагает добавление всевозможных слов к ключевому слову, по которым будет ранжироваться статья.

Сервис Google AdWords сам по себе более заточен под контекстную рекламу, нежели Вордстат. В разделе «Инструменты» можно подобрать необходимые ключи под нужный запрос. В колонке «Таргетинг» задается нужный регион показов и язык. Также можно указывать минус-слова.





- Ключевые слова — аналог частотности «» Вордстата;
- Ключевые слова (по релевантности) — аналог базовой частотности и похожих запросов WS.
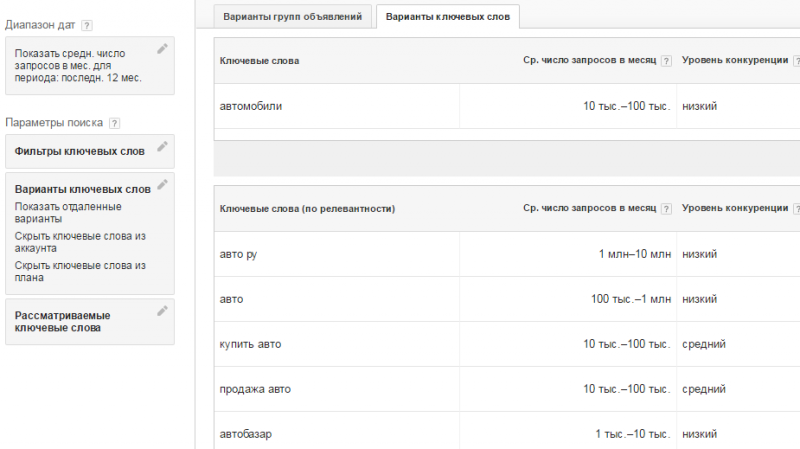
Плюсами являются присутствие уровня конкурентности, а также возможность скачать подобранные слова в CSV-файл или на Гугл Диск.
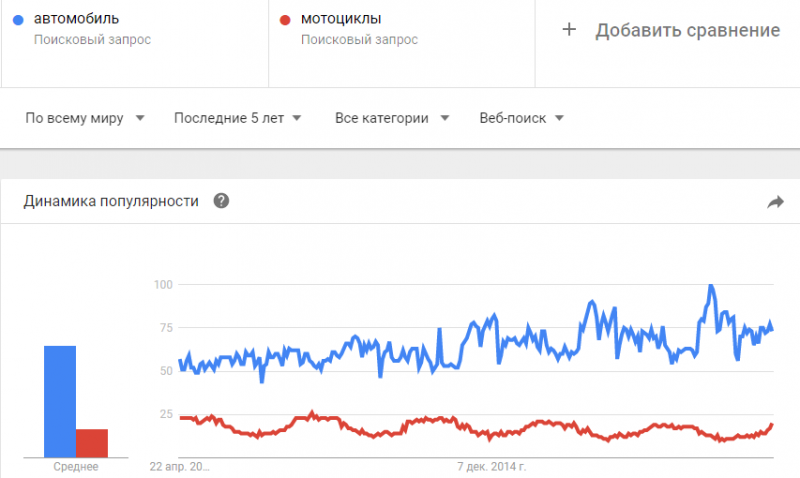
Помимо AdWords, Гугл имеет еще один инструмент по анализу запросов под названием Google Trends. Данный сервис оценивает популярность введенного запроса на определенный период времени и представляет статистику в виде графика. Можно сравнивать несколько ключевых запросов между собой. Также отображается статистика по регионам.
Mail.ru
Mail.ru также имеет в сервисе для вебмастеров инструмент по статистике поисковых запросов. Помимо общих показов, в таблице представлены распределение запросов по полу и возрасту пользователей.

Rambler
Rambler с каждым годом теряет свою популярность, однако их Wordstat может оказаться весьма полезным. Дело в том, что статистика запросов в Яндексе и Гугле не всегда может отображать реальное положение вещей. Многие компании могут вводить «в холостую» коммерческие запросы в целях слежки за конкурентами, т.е. для анализа ТОПа, тайтлов и т.д.
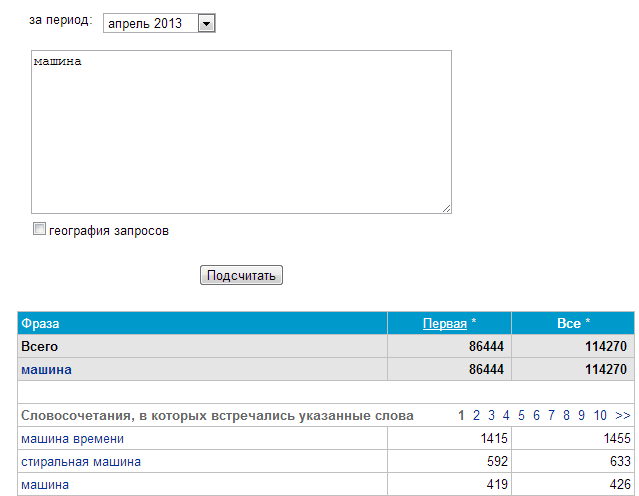
По причине низкой популярности Рамблера, статистика их Вордстата обладает меньшей заспамленностью и может внести некоторую ясность для оптимизаторов. В общем, в качестве дополнительного инструмента вполне сгодится.
Определения
Отметим, что не стоит путать термины “частота“ и “частотность“! Частота – это характеристика периодического процесса, измеряемая в количестве единиц за определенный промежуток времени. Частотность является характеристикой встречаемости заданного объекта (слова) среди определенного набора и измеряется в процентах. Грубо говоря, для нашего случая, частота запроса – это сколько раз в месяц искали заданную ключевую фразу в поисковой системе, а частотность запроса (допустим на странице) – это процент содержания запроса (слова) на рассматриваемой странице. В данной статье будет рассматриваться только понятие частоты поиска определенной ключевой фразы.
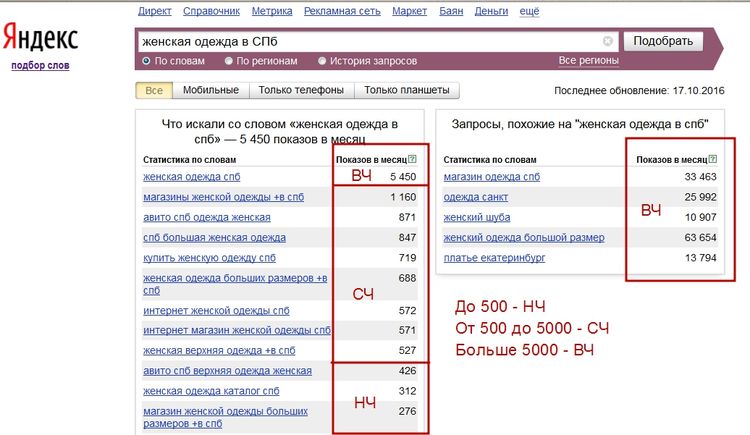
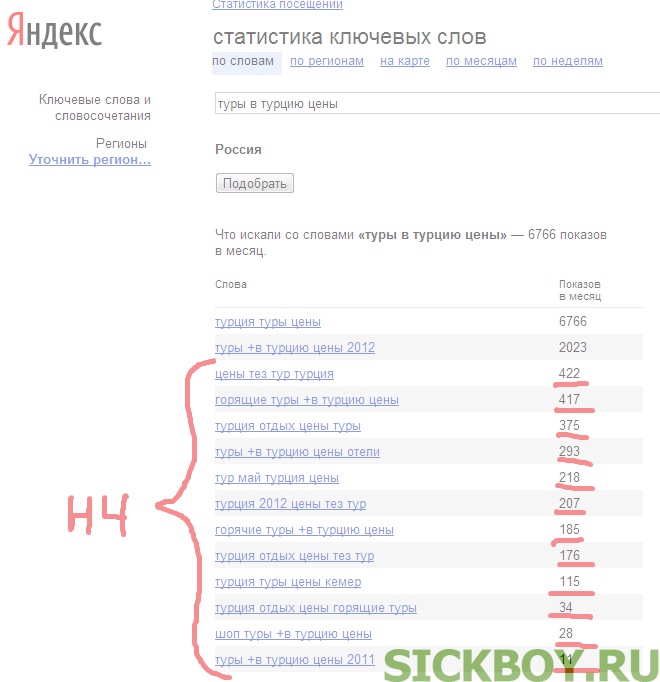
ВЧ (высокочастотные) запросы – наиболее запрашиваемое слово (слова, фразы) в вашей тематике (самые популярные запросы).НЧ (низкочастотные) запросы – слова и фразы, которые запрашиваются с малой частотой в поисковых системах и относятся к вашей тематике.СЧ (среднечастотный) запрос – что-то среднее между НЧ и ВЧ (далее будет точное количественное определение).
Конкурентный запрос – это запрос, по которому сложно вылезти в топ серпа (первые результаты выдачи в поисковой системе) из-за конкуренции сайтов, релевантных данному запросу.Высококонкурентный запрос – запрос, при котором в серпе присутствует очень много конкурентов для данной ключевой фразы.Низкоконкурентный запрос – запрос, при котором внутренних факторов оптимизации достаточно для того, чтобы сайт находился на первой странице серпа по данной ключевой фразе (слову).
Значимость запроса – понятие субъективное и определяется вебмастером (оптимизатором, владельцем сайта) самостоятельно в зависимости от тематики и целей сайта (более подробно о значимости см. тут ). Частота, ниже которой запросы не попадают в выборку значимых и не просматриваются для анализа, называется минимальной значимой частотой выборки.
Операторы поиска
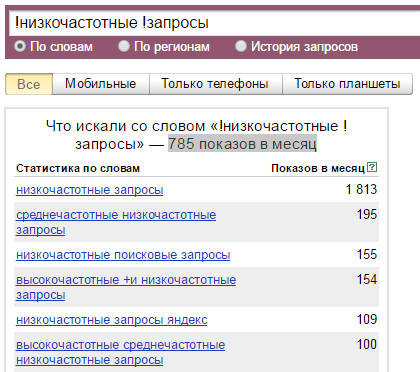
«» — оператор выбирает данные по числу показов фразы в кавычках со всеми возможными окончаниями и порядком слов. То есть полученная цифра будет складываться из частот поиска всех словоформ.

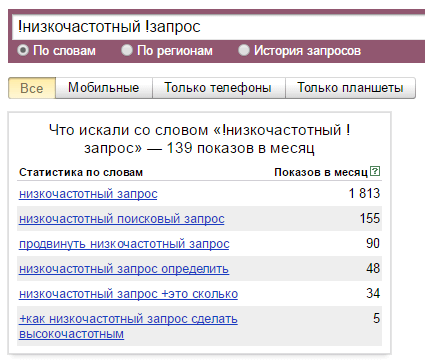
! — фиксирует окончание, мы получим число показов фразы со словами только в той словоформе, что указана. При этом набор слов во фразе не ограничивается.

[] — не так давно добавленный Яндексом оператор, который определяет порядок слов во фразе.

+ — оператор позволяет находить запросы с определенными союзами, предлогами и нужными словами.

— — подходит для минусовки слов, данные по фразам с которыми нам не нужны. Минусовать нужно каждое слово.
![Как использовать яндекс.вордстат для контекстной рекламы [подробный гайд] / блог компании click.ru / хабр](https://rusinfo.info/wp-content/uploads/4/6/f/46f87b8fb5f9883f20595a69cbfc8726.jpg)





| и () — операторы позволяют получить данные по нескольким фразам с условием ИЛИ, объединенных в группировку.

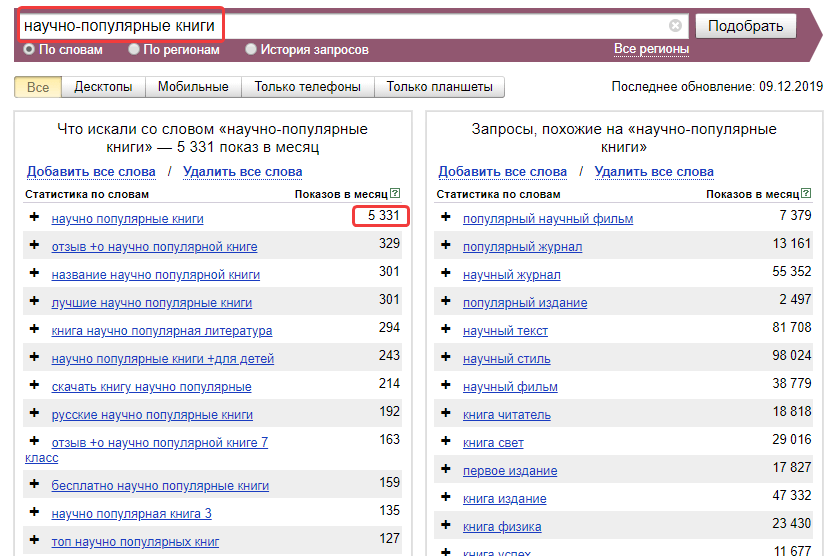
Как правильно составить семантическое ядро по НЧ запросам
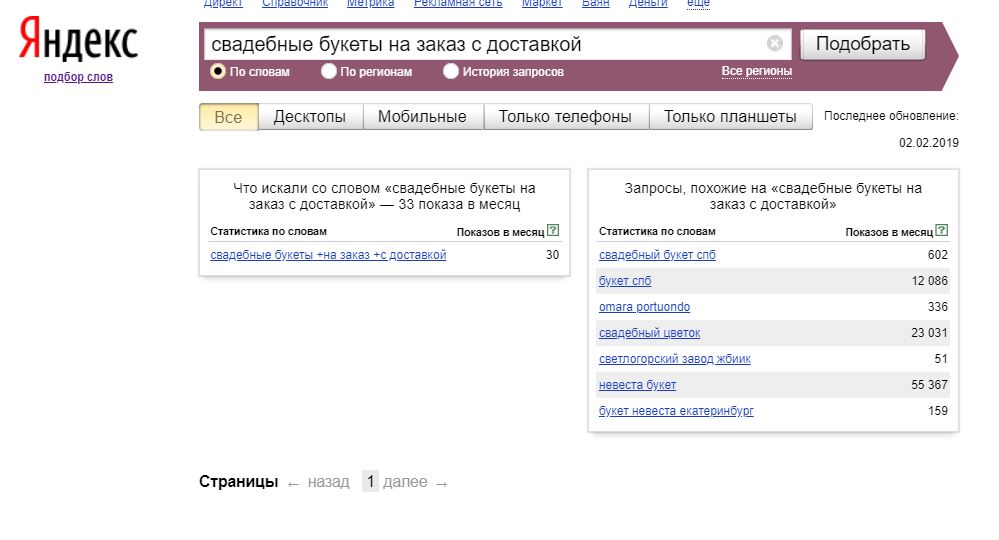
Создание семантического ядра – это подборка ключевых слов, по которым будет продвигаться сайт. Основным рабочим инструментом в этом вопросе является сервис Вордстат. На нём можно проанализировать любую фразу. Например, вас интересует поисковая выдача по фразе «свадебные букеты на заказ с доставкой». Вводим эту фразу в поисковую строку и практически мгновенно получаем результат.
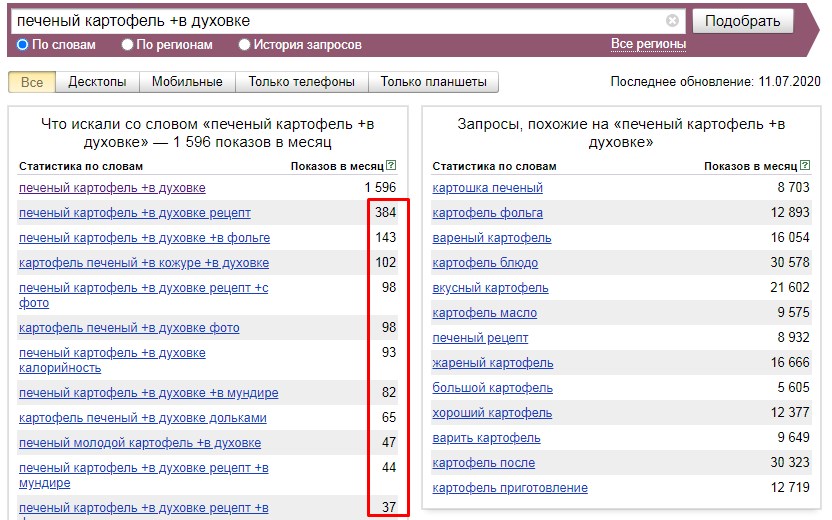
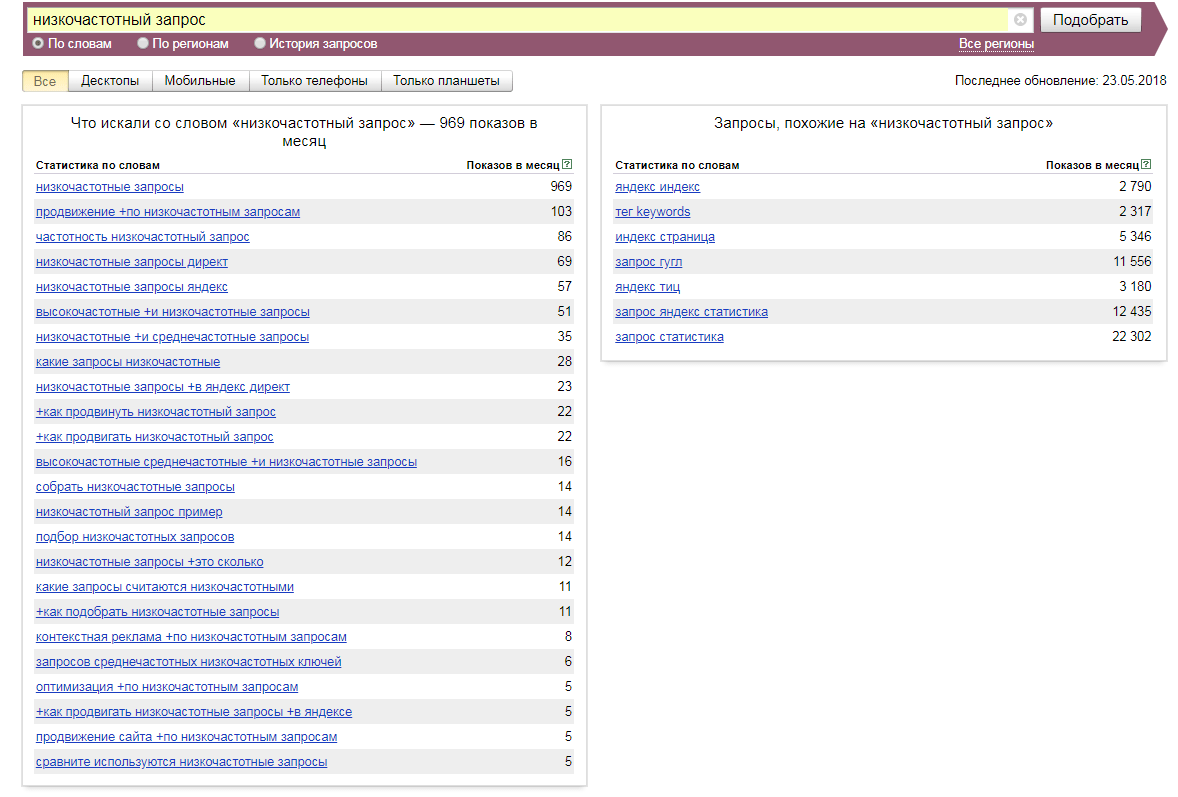
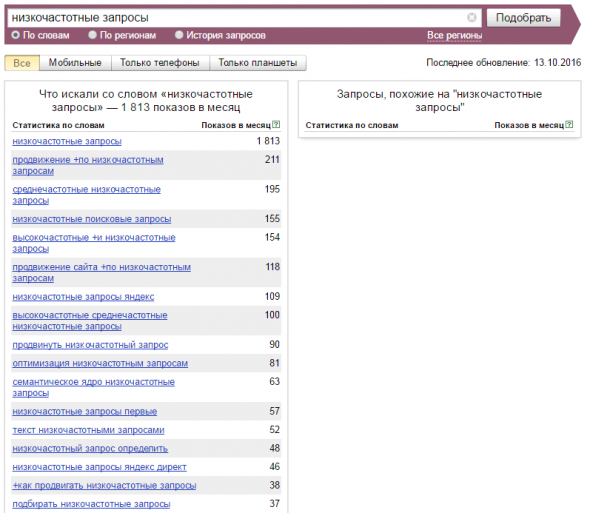
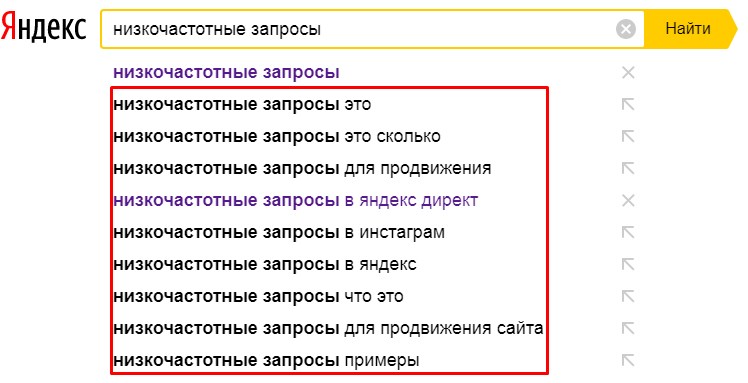
Низкочастотные запросы в Вордстате
Как видите, тестируемая фраза имеет достаточно низкую частоту, и по ней можно начать продвижение
Обратите внимание, что самые низкочастотные запросы могут иметь показатели не более 300 раз в месяц
Подходящую фразу нужно проверить на степень конкурентности. Для этого можно воспользоваться сервисами Мутаген (он платный) или Websiteprofit (бесплатно). С целью оптимизации расходов рассмотрим второй вариант.
Заходим на сайт и вводим в специальной форме интересующий запрос. Отмечаем галочкой пункт Title, если вам интересна статистика по заголовкам. Далее жмем проверить.
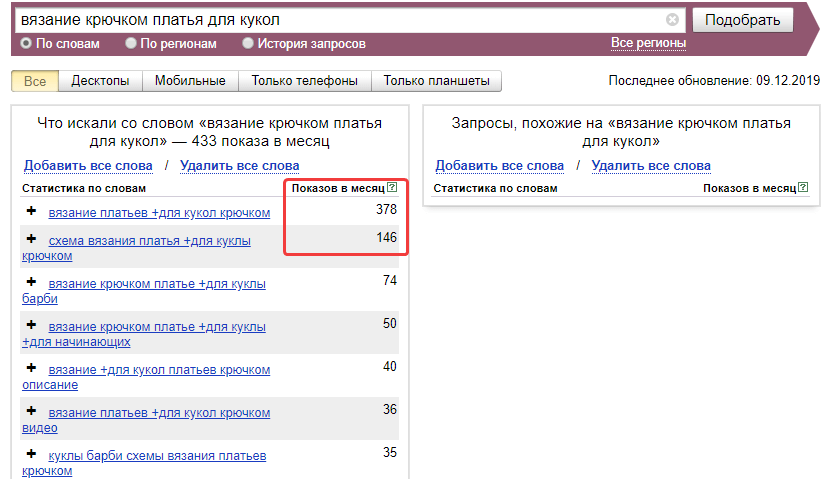
Статистика Яндекс по заголовкам
По результатам выдачи становится ясно, что тестируемый запрос является полностью низкочастотным, так как в заголовках такая фраза встречается всего 387 раз, а это ничтожно мало.
Поисковая выдача по низкочастотному запросу
Теперь можно создавать под этот запрос страницу. Количество ключевых слов, вставляемых в текст, зависит от размера статьи. Чем больше символов, тем комфортнее будут размещаться ключевики
При работе с контентом уделите внимание заголовку и Description. Основной запрос старайтесь размещать в первом абзаце
Помимо описанных сервисов также можно использовать:
- Кей Коллектор,
- СловоЁб,
- Базу Пастухова,
- MOAB,
- Google AdWords.
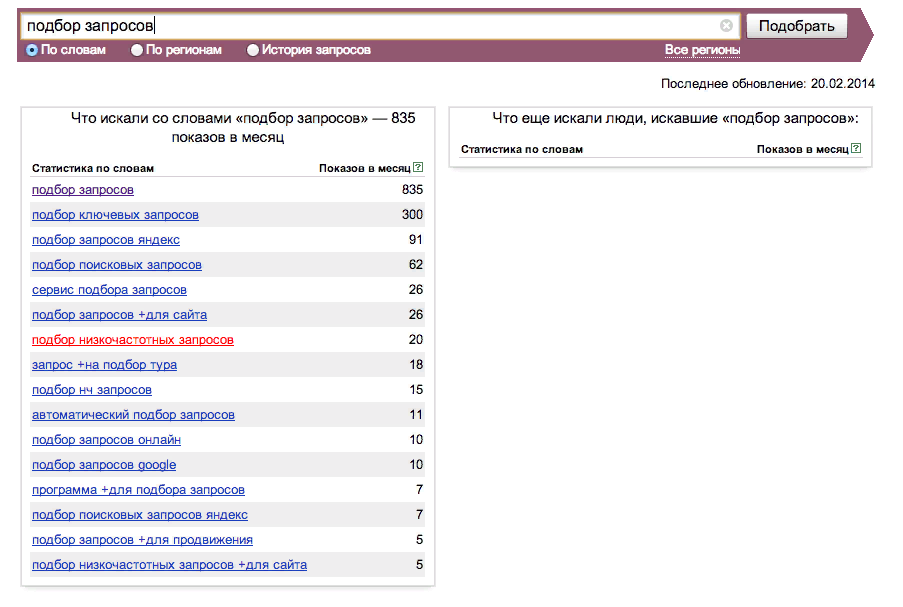
Но учтите, что не все эти сервисы бесплатные. Первые два сервиса решают практически одну и ту же задачу, а именно занимаются подборкой и сортировкой ключевых фраз. Кей Коллектор имеет более широкий функционал, однако таким ресурсом можно воспользоваться только на платной основе. СловоЁб является хорошим бесплатным аналогом, который вполне справляется с поставленной задачей. Такие сервисы очень полезны для более точной проработки семантического ядра.
Сервис СловоЁб подбор ключевых фраз
Частотность запросов в ПС Яндекс
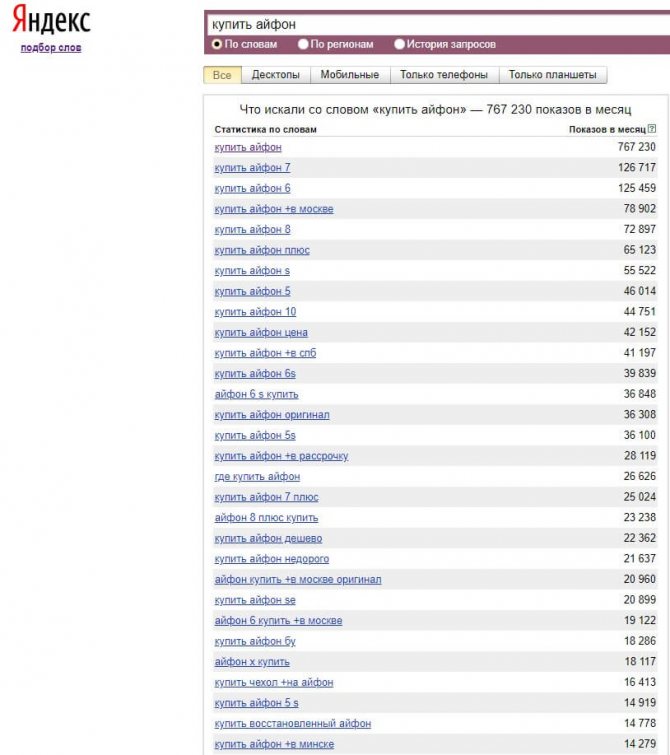
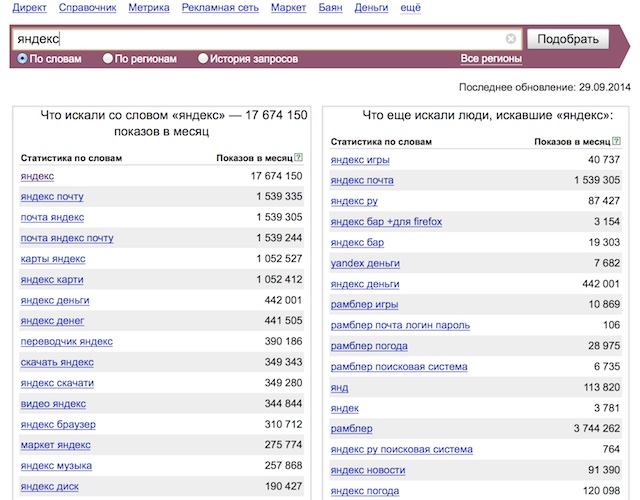
Поисковая система Яндекс, помимо своих основных функций для пользователей – поиск сайтов для ответа на поставленные вопросы, имеет отличный сервис для владельцев сайтов, который позволяет узнать, насколько популярен тот или иной запрос, то есть определить его частотность.
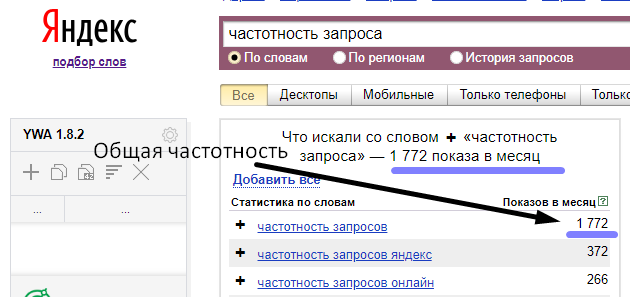
Частотность поисковых запросов – это число раз вводимых пользователем определенного запроса в поисковой системе за промежуток времени (в Яндексе за 1 месяц). То есть при проверке запроса «Квартиры в Москве» на его частотность, мы узнаем, сколько раз в месяц пользователи вбивали это словосочетание в поисковую строку.
Сервис был создан для рекламодателей, который планируют размещать свои объявления в Яндексе. Поэтому Вордстат выдает приблизительно число показов объявления по данному запросу.
Расшифровка
Прежде чем делиться с вами информацией о смысле упомянутых терминов и их пользе в , давайте познакомимся с трактовкой запросов:
-
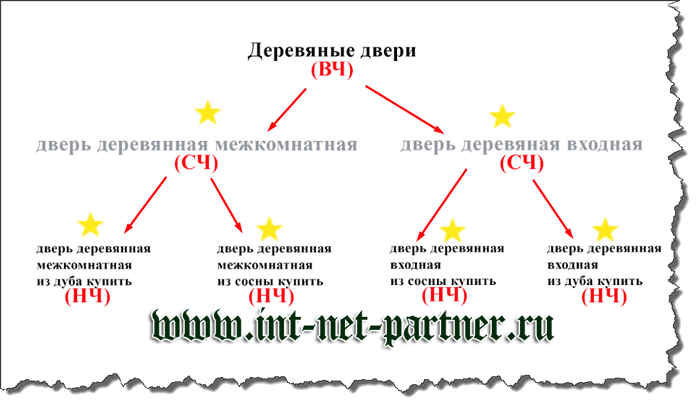
ВЧ
– высокочастотные, характеризующие отрасль, которые задают в поиске более 10000 раз, например – «деревянные двери»; такие запросы общие, не несут никакой конкретики; -
СЧ
– среднечастотный, более конкретный чем предыдущий, обычно состоит из двух или трех слов с частотой запросов в месяц от тысячи до десяти тысяч, например – «дверь деревянная межкомнатная
»; -
НЧ
– низкочастотный, состоящий обычно от трех и более слов с частотой до тысячи запросов в месяц, например — «дверь межкомнатная лиственница купить выгодно
».
Очень важно правильно внедрять ключевики, чтобы пользователи находили ответы на свои вопросы, попадая на ваш информативный источник. В противном случае, поисковые системы заметят, что гости ресурса остаются не на долго на сайте, а это приведет к понижению ваших позиций к выдаче в топе
Различия между ключевиками с различной частотностью, заключаются вот в чем:
Чем меньше частотность, тем меньше конкурентов и больше вероятность того, что ваша статья отобразится первой или одной из первых, к выдаче в результате поиска.
Определенно, рекомендую писать статьи, на начальном этапе развития сайта, под низкочастотные запросы. Разделы сайтов формируют исходя из среднечастотных запросов, а высокочастотные для индекс-страницы сайта, то есть главной.


![Как использовать яндекс.вордстат для контекстной рекламы [подробный гайд]](https://rusinfo.info/wp-content/uploads/8/6/6/86669d362a1bcdea3321993cf445bf8e.png)
Строение поисковых запросов
Каждый ключевой запрос имеет свою семантику строения. Все фразы состоят из тела, спецификатора и хвоста. Разберем анатомию поисковой фразы на примере.
Возьмем для примера запрос «юбка». Данный запрос состоит только из тела, он общий, высокочастотный, и конкуренция по нему слишком высокая. Использование данного запроса нежелательно для продвижения, так как приводит большое количество нецелевого трафика на сайт.
Чтобы определить транзакционную принадлежность, добавляется спецификатор. Именно спецификатор определяет цель поиска. К примеру:
Купить юбку – транзакционный запрос
Раскрой юбки – информационный запрос
Чтобы детализировать запрос, добавляем к нему хвост:
Купить юбку с завышенной талией
Купить юбку для девочки
Купить юбку в Иркутске
Каждый хвост придает запросу определенную деталь для поиска.
Сейчас, зная строение поисковых запросов, вы сможете составить список ключевых слов для своего семантического ядра по формуле «спецификатор + тело + хвост».
Попробуем сделать это на примере для сайта 1PS.RU. Определяем тело – «продвижение сайтов». Далее добавляем спецификатор «заказать продвижение сайта», «купить продвижение сайта» и добавляем хвост «заказать продвижение сайта в поисковых системах», «заказать продвижение сайтов в 1PS», «заказать продвижение сайтов недорого».
С помощью фраз, содержащих хвосты, вы расширите охват аудитории и уменьшите конкурентность семантического ядра.
При составлении семантического ядра мы рекомендуем пользоваться сервисом по подбору фраз Яндекс.Вордстат.
Вы сможете отслеживать статистику поисковых запросов, подбирать подходящие ключевые запросы для сайта, спрогнозировать трафик на сайт и не только. О том, как работать с Яндексом.Вордстат, мы уже рассказывали в одной из статей.
Теперь, зная какие ключевые слова лучше использовать для продвижения, вы можете самостоятельно разработать семантическое ядро. Для каждой страницы сайта оптимально брать по 3–5 ключевых запросов, важных для продвижения (один запрос с высокой частотой, два средне- и низкочастотных запроса).
После того как вы грамотно разработаете семантическое ядро для сайта, следует оптимизировать контент на его основе. Используйте ключевые фразы из СЯ для написания оптимизированных текстов, составления заголовков, тегов и т.д.
А если не уверены в своих знаниях, доверьте эту работу нашим специалистам. Для этого обратитесь в Службу поддержки.
Какие параметры определяет инструмент?
Функционал инструмента не ограничивается анализом частотности запросов онлайн. Перечень определяемых критериев при анализе ключевых слов довольно объемен:
Геозависимость. Бинарный параметр, определяет зависимость результатов выдачи от региона пользователя.
Степень локализации. Количественный параметр, отражающий долю результатов в ТОП-50 выдачи с ярко выраженной географической принадлежностью.
Слова из подсветки (без СПЕКТРа). Слова, которые подсвечиваются в выдаче поисковой системы, исключая те слова, которые были подсвечены по технологии СПЕКТР.
Слова СПЕКТРа. Следует из названия — слова, которые подсвечены благодаря технологии СПЕКТР, например, «отзывы», «самостоятельно» и так далее.
Слова, задающие тематику. Слова, которые встречаются чаще других в сниппетах результатов выдачи, исключая запрос и его синонимы. То есть, наш сервис анализа ключевых слов можно использовать таким образом для расширения семантики.
Общая и точная частоты по WordStat. Онлайн проверка частотности запросов в Яндекс показывает две частоты по системе статистики Яндекс.Вордстат общую и точную, с учётом указанного пользователем региона. Общая — без операторов, точная — с операторами «кавычки» и «восклицательный знак», например, .
Число главных страниц в ТОП. Параметр определяет число главных страниц в поисковой выдаче, чтобы пользователь мог определить, какой тип документа на сайте является приоритетным для продвижения по интересующему ключу.
Наличие витального ответа. Позволяет оценить наличие витального результата, которое чаще всего характерно при поиске бренда или имени сайта. Например, для сайта pixelplus.ru запрос будет являться витальным.
Число найденных результатов. Отражает общее число релевантных документов в индексе поисковой системы.
Бюджет по MegaIndex. Численное значение, которое отражает уровень конкуренции в Яндексе по фразе. Как правило, чем выше число – тем конкурентней запрос.
Число объявлений в Яндекс.Директ. Отражает, какое число игроков на рынке дает контекстную рекламу по данной фразе.
Число точных вхождений в Title и сниппеты из ТОП-50. Позволяет оценить корректность фразы. Этот параметр также является одним из косвенных способов проверки конкурентности запросов.
Средний возраст документов. Название параметра говорит само за себя. Чем выше средний возраст документов в ТОП, тем, как правило, выше уровень конкуренции по нему
Для молодых сайтов рекомендуется уделять внимание оценке данного показателя при анализе поисковых фраз составлении семантического ядра.
Как видите, наш инструмент намного полезнее обычного сервиса проверки запросов на частотность.
Проверка частотности: 80 lvl
Переходим к более сложным тонкостям сбора статистики по запросам из Яндекса .
Пример #1
Начнем с оператора » » и сформулируем одно правило его использования: если во фразе, заключенной в кавычки, присутствуют одинаковые предлоги или слова, то одно из них заменяется на существующее слово во вложенном запросе
. Для примера рассмотрим запрос «автомобиль в кредит москва».
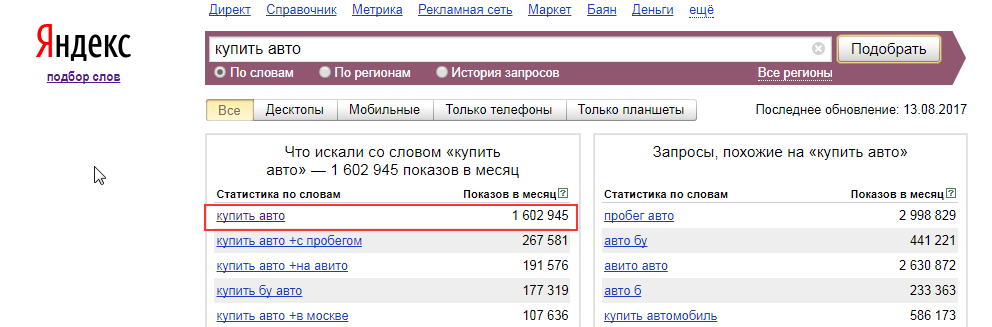
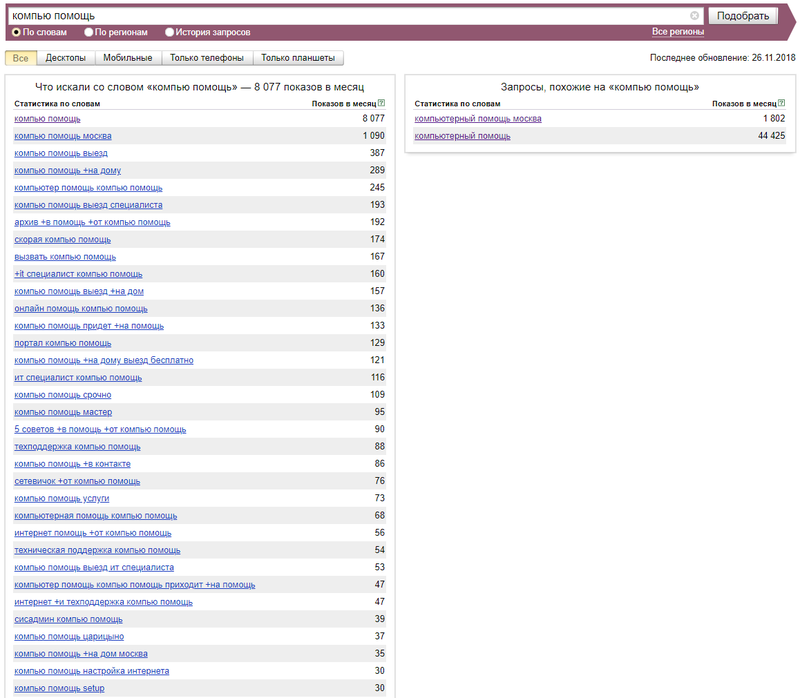
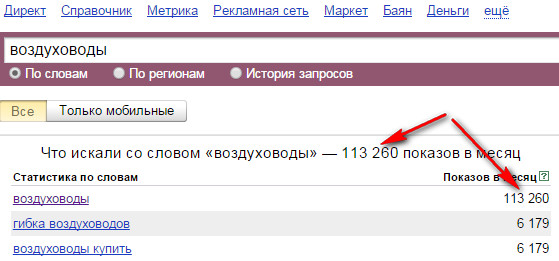
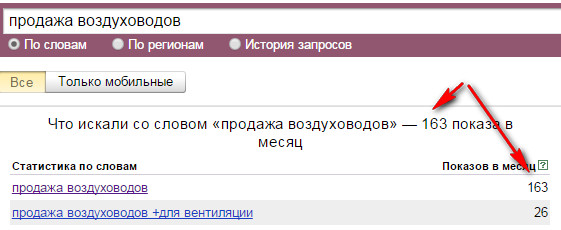



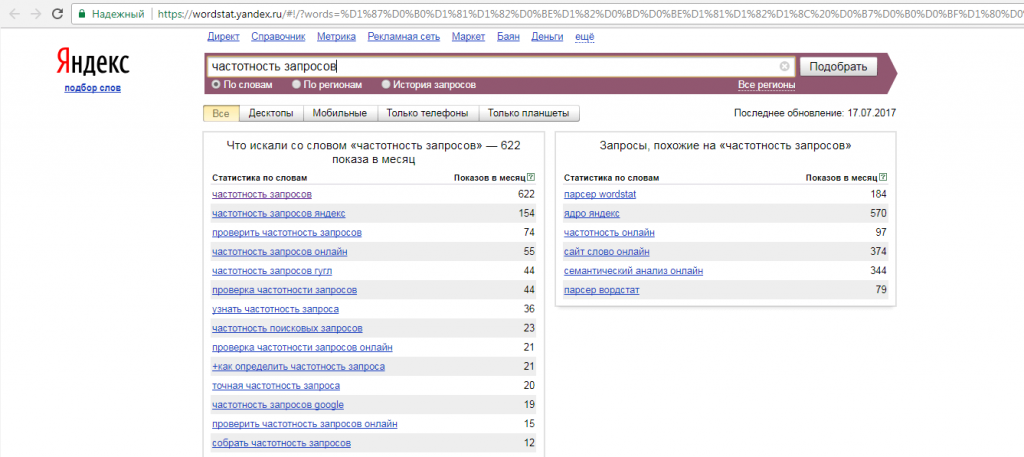

Если добавить в данное ключевое слово еще один предлог «в» перед словом «москва», то получим следующие данные.

Таким образом повторяющиеся предлоги «в» были объединены, и к запросам добавилось еще одно слово. Для разных запросов это слова «купить», «бу», «новый», «залог», подержанные». «оформить».
Этот прием — невероятный инструмент для информационный сайтов, основной целью которых является рост трафика. Он позволяет выбрать из тематики весь диапазон запросов, которые включают в себя заданное количество слов, например, все запросы по тематике из 5 слов. Как правило, очень расширенные запросы из 5-7 слов бывают менее конкурентными, соответственно привлечь трафик и занять высокие позиции по ним легче. А если эти запросы не уступают в показах высокочастотным запросам? Выборка наиболее высокочастотных и наименее конкурентных запросов позволит вам быстро добиться результата. Давайте рассмотрим пример.

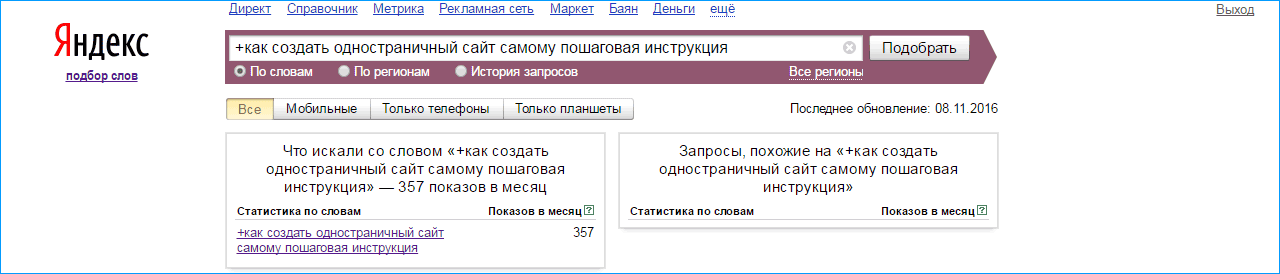
В данном запросе мы просим WordStat показать диапазон запросов, который включает в себя 7 слов, обязательно содержащих слова «инструкция по применения». 5 слов «инструкция» объединяются, остается одно, 4 слова заменяются на новые вложенные запросы. Смотрим один из сотен вложенных запросов, частотность запроса из 7 слов — 8090 показов в месяц. Для сравнению запрос «купить автомобиль в москве» имеет 647 показов в месяц. Разрыв шаблона еще не произошел? Тогда идем дальше.

Пример #2
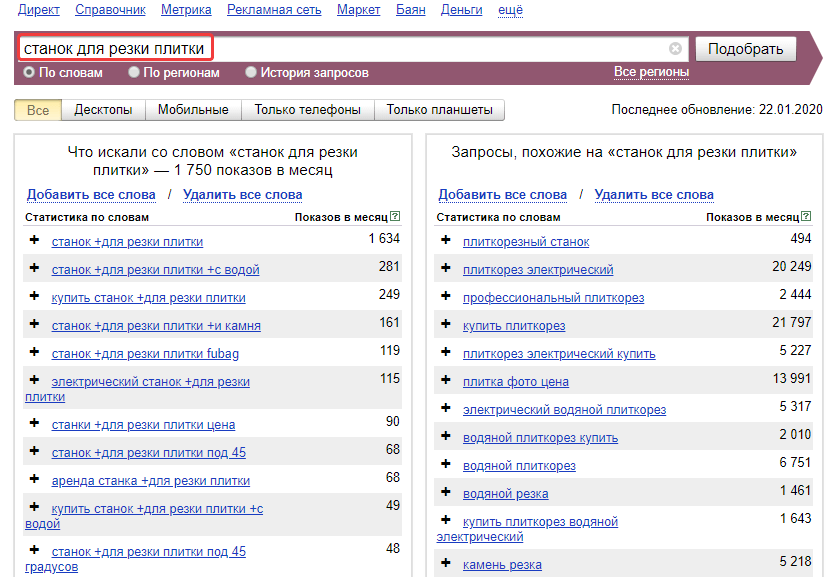
Сейчас пойдет в бой более сложный оператор () и |, с его помощью мы соберем пул запросов, из которого в дальнейшем сможем сделать теговые страницы. Возьмем для примера запрос «купить автомобиль bmw». Данную марку авто, ее серии могут искать по самым разным запросам: «купить машину бмв», «купить bmw икс 6», «купить автомобиль бмв 5» и т.п. Для того чтобы получить пул запросов без повторений, используем регулярное выражение:
Купить (автомобиль|машина) (бмв|bmw) -пробегом -фото -не -заводится -скачать -бу -какая
Добавим в него сразу ряд нерелевантных минус-слов, которые не подходят для нашего бизнеса. Получаем следующие данные, которые впоследствие проще структурировать.

Данная выборка поможет вам проще собрать данные для теговых страниц и кластеризации данных.
Обратите внимание
, нельзя в одном выражении использовать операторы » » и () |. Логика работы одного оператора нарушает логику работы другого
Пример #3
Рыбалка (+с|+на) -игра -бесплатная -скачать -русские -охота
Минус-слова, конечно же, нужно добавить, но в данном случае это просто пример. Получаем вот такой результат:

Пример #4
Совместное использование операторов поможет вам разграничить похожие по написанию, но разные по смыслу запросы. Например, запрос «купить тур в москвУ» подразумевает экскурсионную поезду в
Москву.

Запрос «купить тур в москвЕ» подразумевает учет геопозиции пользователя для покупки тура из
Москвы.

Пример #5
Еще один пример регулярного выражения, которое поможет вам собрать запросы для теговых страниц или фильтров каталога в нише купальников.

Даже если данные примеры не относятся к вашей нише, надеемся они помогут вам улучшить свои навыки работы с WordStat. Если у вас возникли вопросы, вы нашли ошибки, либо хотите дополнить статью, пожалуйста, пишите в комментарии, мы с радостью ответим вам!
Перед тем, как что-то делать в интернете: создавать сайт, настраивать рекламную компанию, писать статью или книгу, надо посмотреть, что вообще ищут люди, чем интересуются, что вводят в поисковой строке.
Поисковые запросы (ключевые фразы и слова) чаще всего собирают в двух случаях:
Если вы собираетесь настраивать контекстную рекламу, то .
А ниже мы рассмотрим, как собрать статистику поисковых запросов в популярных поисковых системах, а так же небольшие секреты, как это сделать лучше.
Сразу добавлю, что сам я пользуюсь платными сервисами, потому-что бесплатно можно очень долго собирать тот объем данных, который мне обычно нужен для продвижения и настройки рекламы. Но когда нужно быстро глянуть запрос, то подойдут и эти методы.
![Как использовать яндекс.вордстат для контекстной рекламы [подробный гайд] / блог компании click.ru / хабр](https://rusinfo.info/wp-content/uploads/e/5/0/e500098857e665350a961c173441f8cf.png)




Заключение
В данной статье мы рассказали о том, что такое частота запросов «Яндекс», как узнать ее для конкретных слов и фраз, а также как получить наиболее точные и полезные данные по ним. Правильный подбор ключевых слов очень важен для продвижения в Интернете и привлечения посетителей на свой ресурс. Именно поэтому такие сервисы, как «Яндекс.Вордстат» пользуются большой популярностью у сео-оптимизаторов, копирайтеров, рекламодателей и владельцев сайтов.
Один из наиболее популярных модулей в Rush Analytics – парсер Яндекс Вордстат, и это не случайно. При
сборе семантического ядра необходимо точно знать частотность собранных запросов, чтобы правильно
расставить приоритеты по продвижению и избавится от «мусорных» и нулевых запросов. Часто стоит
задача пробить несколько десятков тысяч запросов на частотность в Яндексе, но это не совсем простая
задача для самописных парсеров Вордстата и десктопных программ, и вот почему:
- Yandex Wordstat имеет хорошую защиту от парсинга, например бан IP-адресов с которых
осуществляется парсинг и выбрасывание капчи в ответ на запросы от ботов. Чтобы эффективно
собирать данные с Wordstat, нужен эффективный алгоритм подключения IP-адресов и другие хитрости - Для парсинга большого количества данных с помощью десктопных программ понадобится много
IP-адресов (прокси), которые Яндекс с легкостью банит при неоптимальном алгоритме подключения, а
прокси – удовольствие недешевое - Так же для парсинга понадобится автоматическое введение большого количества капчи (например
подключение Antigate для этой задачи). Данный фактор, при неоптимальном алгоритме парсинга,
может сделать сам парсинг нерентабельным, так как стоимость капчи будет чрезмерно высока - Большинство десктопных программ не имеют защиты от потери данных при сборе. Так, например,
собрав половину данных и потратив на это деньги, при сбое в парсере, вы рискуете не только не
получить оставшиеся данные, но и потерять уже собранные







