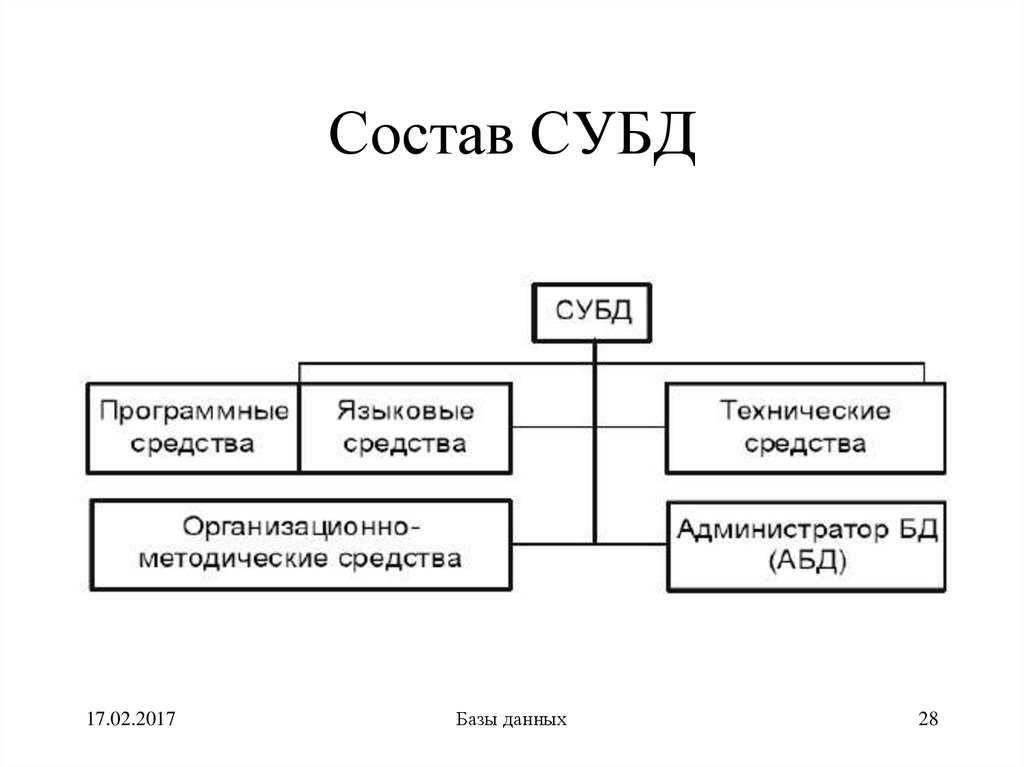
Oracle
Эта СУБД относится к объектно-реляционному типу. Название произошло от названия разработавшей эту систему фирмы Oracle. Наравне с SQL СУБД использует процедурное расширение под названием PL/SQL, а также язык Java.
Oracle – это система, отличающаяся стабильностью уже не один десяток лет, поэтому ее выбирают крупные корпорации, для которых важна надежность восстановления после сбоев, отлаженная процедура бэкапа, возможность масштабирования и другие ценные возможности. К тому же эта СУБД обеспечивает отличную безопасность и эффектную защиту данных.
В отличие от других СУБД, стоимость покупки и использования Oracle достаточно высока, и именно это зачастую является значимым препятствием к ее использованию в небольших фирмах. Вероятно, именно это также является причиной того, что в рейтинге СУБД на 2016 год в России Oracle находится лишь на 6-м месте.
Виды баз данных
Существует огромное количество разновидностей баз данных, отличающихся по различным критериям. Например, в «Энциклопедии технологий баз данных», по материалам которой написан данный раздел, определяются свыше 50 видов БД.
Основные классификации приведены ниже.
Классификация по модели данных
Примеры:
- Иерархическая
- Объектная и объектно-ориентированная
- Объектно-реляционная
- Реляционная
- Сетевая
- Функциональная.
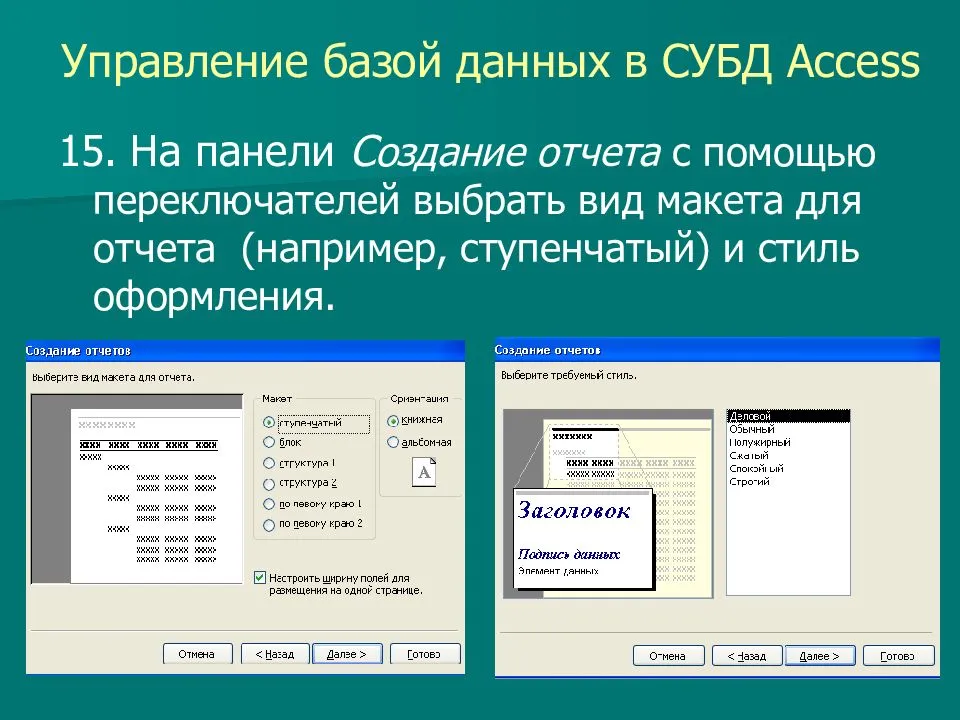
Классификация по среде постоянного хранения
- Во вторичной памяти, или традиционная (англ. conventional database): средой постоянного хранения является периферийная энергонезависимая память (вторичная память) — как правило жёсткий диск.В оперативную память СУБД помещает лишь кэш и данные для текущей обработки.
- В оперативной памяти (англ. in-memory database, memory-resident database, main memory database): все данные на стадии исполнения находятся в оперативной памяти.
- В третичной памяти (англ. tertiary database): средой постоянного хранения является отсоединяемое от сервера устройство массового хранения (третичная память), как правило на основе магнитных лент или оптических дисков.Во вторичной памяти сервера хранится лишь каталог данных третичной памяти, файловый кэш и данные для текущей обработки; загрузка же самих данных требует специальной процедуры.
Примеры:
- Географическая
- Историческая
- Научная
- Мультимедийная
- Клиентская.
Классификация по степени распределённости
- Централизованная, или сосредоточенная (англ. centralized database): БД, полностью поддерживаемая на одном компьютере.
-
Распределённая БД (англ. distributed database) — составные части которой размещаются в различных узлах компьютерной сети в соответствии с каким-либо критерием.
- Неоднородная (англ. heterogeneous distributed database): фрагменты распределённой БД в разных узлах сети поддерживаются средствами более одной СУБД.
- Однородная (англ. homogeneous distributed database): фрагменты распределённой БД в разных узлах сети поддерживаются средствами одной и той же СУБД.
- Фрагментированная, или секционированная (англ. partitioned database): методом распределения данных является фрагментирование (партиционирование, секционирование), вертикальное или горизонтальное.
- Тиражированная (англ. replicated database): методом распределения данных является тиражирование (репликация).
Другие виды БД
- Пространственная (англ. spatial database): БД, в которой поддерживаются пространственные свойства сущностей предметной области. Такие БД широко используются в геоинформационных системах.
- Временная, или темпоральная (англ. temporal database): БД, в которой поддерживается какой-либо аспект времени, не считая времени, определяемого пользователем.
- Пространственно-временная (англ. spatial-temporal database) БД: БД, в которой одновременно поддерживается одно или более измерений в аспектах как пространства, так и времени.
- Циклическая (англ. round-robin database): БД, объём хранимых данных которой не меняется со временем, поскольку в процессе сохранения новых данных они заменяют более старые данные. Одни и те же ячейки для данных используются циклически.
SQL и NoSQL
abДва варианта представления данных
уплотнения
Масштабируемость
Тип хранилища данных
Сценарий использования
Пример
Рекомендации
Хранилище типа ключ-значение
Подходит для простых приложений, с одним типом объектов, в ситуациях, когда поиск объектов выполняют лишь по одному атрибуту.
Интерактивное обновление домашней страницы пользователя в Facebook.
Рекомендовано знакомство с технологией memcached.
Если приходится искать объекты по нескольким атрибутам, рассмотрите вариант перехода к хранилищу, ориентированному на документы.
Хранилище, ориентированное на документы
Подходит для хранения объектов различных типов.
Транспортное приложение, оперирующее данными о водителях и автомобилях, работая с которым надо искать объекты по разным полям, например — имя или дата рождения водителя, номер прав, транспортное средство, которым он владеет.
Подходит для приложений, в ходе работы с которыми допускается реализация принципа «согласованность в конечном счёте» с ограниченными атомарностью и изоляцией. Рекомендуется применять механизм кворумного чтения для обеспечения своевременной атомарной непротиворечивости.
Система хранения данных с расширяемыми записями
Более высокая пропускная способность и лучшие возможности параллельной обработки данных ценой слегка более высокой сложности, нежели у хранилищ, ориентированных на документы.
Приложения, похожие на eBay
Вертикальное и горизонтальное разделение данных для хранения информации клиентов.
Для упрощения разделения данных используются HBase или Hypertable.
Масштабируемая RDBMS
Использование семантики ACID освобождает программистов от необходимости работать на достаточно низком уровне, а именно, отвечать за блокировки и непротиворечивость данных, обрабатывать устаревшие данные, коллизии.
Приложения, которым не требуются обновления или слияния данных, охватывающие множество узлов.
Стоит обратить внимание на такие системы, как MySQL Cluster, VoltDB, Clustrix, ориентированные на улучшенное масштабирование.
этом
О выборе SQL-баз данных
- Необходимость соответствия базы данных требованиям ACID (Atomicity, Consistency, Isolation, Durability — атомарность, непротиворечивость, изолированность, долговечность). Это позволяет уменьшить вероятность неожиданного поведения системы и обеспечить целостность базы данных. Достигается подобное путём жёсткого определения того, как именно транзакции взаимодействуют с базой данных. Это отличается от подхода, используемого в NoSQL-базах, которые ставят во главу угла гибкость и скорость, а не 100% целостность данных.
- Данные, с которыми вы работаете, структурированы, при этом структура не подвержена частым изменением. Если ваша организация не находится в стадии экспоненциального роста, вероятно, не найдётся убедительных причин использовать БД, которая позволяет достаточно вольно обращаться с типами данных и нацелена на обработку огромных объёмов информации.
Как правильно выбрать базу данных NoSQL: ключевые факторы
Имея более двух десятков свободно распространяемых и коммерческих баз данных NoSQL на рынке, как вы выбрать нужный продукт или облачный сервис?
Один из важных факторов – четко сформулировать цель, которую вы хотите достичь поместить данные в такую БД.
Базы данных NoSQL различаются по архитектуре и функциям, поэтому вам нужно выбрать тот тип БД, который лучше всего подходит для желаемой задачи:
- В целом, хранилища типа «ключ-значение» (key-value stores) лучше всего подходят для постоянного совместного использования данных несколькими процессами или микросервисами в приложении.
- Если вы планируете провести глубокий анализ отношений для расчета взаимосвязей, обнаружения мошенничества или оценки ассоциативной структуры, лучше всего будет использовать графовую базу данных графа.
- Если вам нужно собирать данные очень быстро и на больших объемах для аналитики, посмотрите в сторону широкий колоночных баз данных или, как их еще называют), базы данных с широким значением столбца (wide column store). Такие базы данных NoSQL также предлагают поддержку документов и графов.
Задумывайтесь сразу и немного на перспективу. Обычно ваш первоначальный проект не будет является единственной моделью использования базы данных. Вы можете начать просто со ввода данных в рамках отельных сессий, затем посмотреть в сторону обработки транзакций, а еще позже можете захотеть выполнять и анализ данных.







В ближайшей перспективе основное внимание должно быть сосредоточено на производительности, масштабируемости, безопасности, поддержке различных рабочих нагрузок (включая транзакционные, операционные и аналитические), интеграции с существующими экосистемами, усилиях по администрированию, поддержке облачных вычислений и типах поддерживаемых вариантов использования БД. Из всех этих факторов очень важна безопасность
Базы данных NoSQL, имеющие сертификаты безопасности, должны быть рассмотрены в первую очередь. Ищите такие функции, как шифрование данных в состоянии покоя (data at rest) и шифрования данных на лету (data in motion) для защиты конфиденциальной информации.
Кроме того, не все базы данных NoSQL могут масштабироваться хорошо. Не считайте само собой разумеющимся, что только потому, что продукт находится в категории NoSQL, он будет масштабироваться и работать лучше, чем реляционные базы данных.
NoSQL предлагает различные уровни согласованности в модели масштабирования, поэтому рассмотрите решения, соответствующие вашим конкретным требованиям. Например, если вы хотите поддерживать чрезвычайно важные банковские транзакции, реляционные базы данных по-прежнему являются лучшим решением.
5. MongoDB

Эта СУБД отличается тем, что она предназначена для хранения иерархических структур данных, и поэтому ее называют документоориентированной (она представляет собой документное хранилище без использования таблиц или схем). MongoDB имеет открытый исходный код.
Используя идентификатор, вы можете производить быстрые операции над объектом; эта СУБД хорошо показывает себя и при сложных взаимодействиях. В первую очередь речь идет о быстродействии – в некоторых случаях приложение, написанное на MongoDB, будет работать быстрее, чем такое же приложение, использующее SQL, т.к. MongoDB относится к классу СУБД NoSQL и вместо SQL пользуется объектным языком запросов, который значительно легче SQL.
Однако этот язык имеет и свои ограничения, а поэтому MongoDB следует использовать в случаях, когда нет необходимости в сложных и нетривиальных выборках.
Выбор СУБД – это важный момент при создании своего ресурса. Отталкивайтесь от своих задач и возможностей, пробуйте и экспериментируйте, чтобы найти именно тот вариант, который будет наиболее подходящим.
Примечания
«Следует отметить, что термин база данных часто используется даже тогда, когда на самом деле подразумевается СУБД. Такое обращение с терминами предосудительно». — К. Дж. Дейт. Введение в системы баз данных. — 8-е изд. — М.: «Вильямс», 2006, стр. 50.«Этот термин (база данных) часто ошибочно используется вместо термина ‘система управления базами данных’». — Когаловский М. Р. Энциклопедия технологий баз данных. — М.: Финансы и статистика, 2002., стр. 460.«Среди непрофессионалов путаница возникает при использовании терминов „база данных“ и „система управления базами данных“. Мы будем строго разделять эти термины». —
Кузнецов С. Д. Основы баз данных: учебное пособие. — 2-е издание, испр. — М.: Интернет-Университет Информационных Технологий; БИНОМ. Лаборатория знаний, 2007, стр. 19.
↑ ГОСТ Р ИСО МЭК ТО 10032-2007: Эталонная модель управления данными (идентичен ISO/IEC TR 10032:2003 Information technology — Reference model of data management)
ГОСТ 33707-2016 (ISO/IEC 2382:2015) Информационные технологии (ИТ). Словарь
(англ.). www.iso.org. Дата обращения 9 июля 2018.
(англ.). www.iso.org
Дата обращения 9 июля 2018.
↑
.
.
.
Важно понимать, что структурированность базы данных оценивается не на уровне физического хранения (на котором все данные представлены совокупностями битов или байтов), а на уровне некоторой логической модели данных.
↑
Riedewald M., Agrawal D., Abbadi A. Dynamic Multidimensional Data Cubes for Interactive Analysis of Massive Datasets // In: Encyclopedia of Information Science and Technology, First Edition, Idea Group Inc., 2005
ISBN 9781591405535
↑
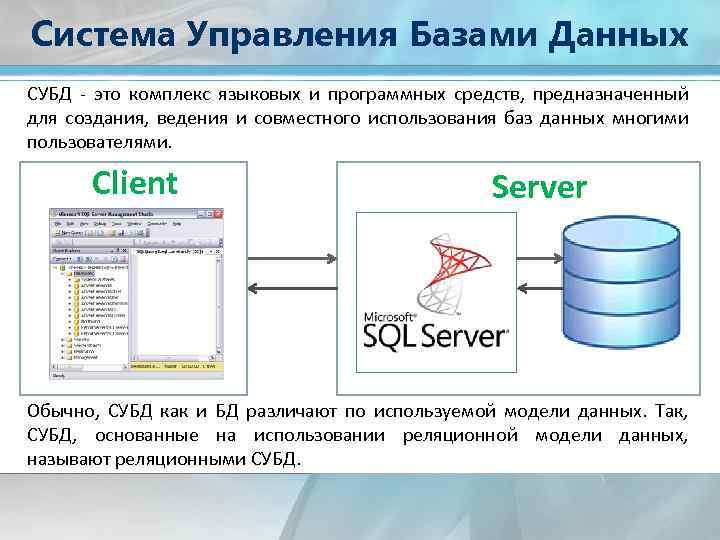
Установка ПО для работы
В данном разделе рассказывается как установить и настроить SQL Server на примере SQL Server 2016 Enterprise – самой новой версии.
Для начала скачайте установочный пакет SQL Server 2016 Enterprise с официальной страницы: https://www.microsoft.com/en-us/sql-server/sql-server-editions-express. Версия, которую вы скачали будет работать .





Вместо нее можно использовать SQL Server 2016 Developer Edition, если у вас есть подписка MSDN. Станица для скачивания: https://www.microsoft.com/en-us/sql-server/sql-server-editions-developers.
Прежде чем запускать скаченный установщик, создайте учетную запись. Она потребуется чтобы авторизовываться вас на сервере с клиентского компьютера. Поскольку у вас это один и тот же компьютер, то авторизовываться будет SQL Server через Management Studio, его мы скачаем позже.
Создание учетной записи
Выполните следующие инструкции чтобы создать учетную запись в Windows. Способ работает во всех ОС этого семейства начиная с 2000 и заканчивая 10.
Инструкции:
- Кликните правой кнопкой мышки по значку «Мой компьютер» на рабочем столе и выберите из списка пункт «Управление». Откроется оснастка «Управление компьютером».
- В окне оснастке выберите пункт меню «локальные пользователи», затем выделите пункт «пользователи». Окно приобретёт вот такой вид:
- Кликните правой кнопкой мыши по пустому пространству папки или по названию папки и выберите пункт «новый пользователь». Откроется такое окно:
- Придумайте имя пользователя и пароль заполните их в формы и нажмите кнопку создать. Рекомендуем использовать латинские символы.
Установка SQL Server
- Запустите скачанный ранее пакет установки. Установщик проверит подходит ли ваш компьютер по производительности и есть ли на нем все необходимое для установки программное обеспечение. Если последнего не окажется, он его скачает. После этого откроется SQL Server Installation Server:
- Выберите пункт «Установка».
- После изменения экраны кликните на пункте «Новая установка изолированного экземпляра SQL Server». Запустится установка и установщик попытается обновиться до последней версии. Щелкните кнопку «Далее», чтобы перейти к следующему шагу:
- На этапе «правил установки» проследите чтобы в окне не было красных крестиков. Если они появились, то щелкайте по выделенным строкам предупреждений и следуйте инструкциям по устранениям. Затем, щелкните кнопку «Далее». Окно установки снова изменится:
- В появившемся окне выберите «Выполнить новую установку SQL Server 2016» и нажмите «Далее». Откроется окно регистрации продукта:
- Введите лицензионный ключ продукта, если он у вас есть. Либо выберите Evaluation для активации 180 дневной копии.
- В следующем окне прочтите лицензионное соглашение, и примите его, установив флажок в поле «Я принимаю…». И нажмите «Далее»
- Откроется окно компонентов. Выберите пункты, установив галочки напротив:
• Службы ядра СУБД;
• Соединение с клиентскими средствами;
• Компоненты документации.
Нажмите «Далее» - В следующем окне выберите «экземпляр по умолчанию» если уже есть установленная копия SQL Server или именованный экземпляр, если устанавливаете первый раз. Введите в поле имя Экземпляра и нажмите «Далее».
- В следующем окне проверьте, хватает ли места на диске. Если нет, освободите его и нажмите «Далее».
- На этапе «Настройка Ядра СУБД» убедитесь, что выбрана строка «Проверка подлинности Windows». Если нет, выберите его. Затем добавьте в поле внизу пользователя, которого создавали перед установкой, либо добавьте текущего с помощью соответствующей кнопки Нажмите «Далее»
- На следующем окне перепроверьте все настройки установки и нажмите «далее»
- Понаблюдайте за установкой и нажмите «Закрыть», когда появится сообщение о завершении установки.
Виды моделей данных
Организация данных рассматривается с позиций той или иной модели данных. Модель данных является ядром любой базы данных. С помощью модели данных могут быть представлены объекты предметной области и взаимосвязи между ними.
Модель данных – совокупность структур данных, ограничений целостности и операций манипулирования данными. Модели используются для представления данных в информационных системах.
Различают три типа моделей данных, которые имеют множества допустимых информационных конструкций:
- иерархическая;
- сетевая;
- реляционная.
Иерархическая модель данных
Иерархическая структура представляет совокупность элементов, связанных между собой по определенным правилам. Объекты, связанные иерархическими отношениями, образуют ориентированный граф (перевернутое дерево), вид которого представлен на рисунке:
Основные понятия иерархической структуры
Это – узел, уровень и связь.
Узел – это совокупность атрибутов данных, описывающих некоторый объект. На схеме иерархического дерева узлы представляются вершинами графа. Каждый узел на более низком уровне связан только с одним узлом, находящимся на более высоком уровне.
Иерархическое дерево имеет только одну вершину (корень дерева), не подчиненную никакой другой вершине и находящуюся на самом верхнем (первом) уровне. Зависимые (подчиненные) узлы находятся на втором, третьем и т.д. уровнях. К каждой записи базы данных существует только один (иерархический) путь от корневой записи. Например, как видно из рисунке, для записи С4 путь проходит через записи ВЗ к А.
Пример иерархической структуры:
Сетевая модель данных
В сетевой структуре при тех же основных понятиях (уровень, узел, связь) каждый элемент может быть связан с любым другим элементом.
На рисунке изображена сетевая структура базы данных в виде графа.
Пример сетевой структуры:
Примером сложной сетевой структуры может служить структура базы данных, содержащей сведения о студентах, участвующих в научно-исследовательских работах (НИРС). Возможно участие одного студента в нескольких НИРС, а также участие нескольких студентов в разработке одной НИРС. Графическое изображение описанной в примере сетевой структуры состоит только из двух типов записей.






Реляционная модель данных
Понятие реляционный (англ. relation – отношение) связано с разработками известного американского специалиста в области систем баз данных Е.Кодда.
Реляционная модель ориентирована на организацию данных в виде двумерных таблиц. Каждая реляционная таблица представляет собой двумерный массив и обладает следующими свойствами:
- каждый элемент таблицы – один элемент данных;
- все столбцы в таблице однородные, т.е. все элементы в столбце имеют одинаковый тип (числовой, символьный и т.д.) и длину;
- каждый столбец имеет уникальное имя (заголовки столбцов являются названиями полей в записях);
- одинаковые строки в таблице отсутствуют;
- порядок следования строк и столбцов может быть произвольным.
Отношение – это плоская таблица, содержащая N столбцов, среди которых нет одинаковых. N – это степень отношения, или арность отношения. Столбец отношения соответствует атрибуту сущности. Кортеж – строка отношения (соответствует записи в таблице).
Пример реляционной модели
| № личного дела | Фамилия | Имя | Отчество | Дата рождения | Группа |
| 16493 | Сергеев | Петр | Михайлович | 01.01.90 | 112 |
| 16593 | Петрова | Анна | Владимировна | 15.03.89 | 111 |
| 16693 | Антохин | Андрей | Борисович | 14.04.90 | 112 |
Отношения представлены в виде таблиц, строки которых соответствуют кортежам или записям, а столбцы – атрибутам отношений, доменам, полям.
Поле, каждое значение которого однозначно определяет соответствующую запись, называется простым ключом (ключевым полем).
Если записи однозначно определяются значениями нескольких полей, то такая таблица базы данных имеет составной ключ. В примере ключевым полем таблицы является «№ личного дела».
Мультимодельные СУБД «без основной модели»
На рынке также представлены СУБД, позиционирующие себя как изначально мультимодельные, не имеющие никакой унаследованной основной модели. К их числу относятся ArangoDB, OrientDB (c 2018 года компания-разработчик принадлежит SAP) и CosmosDB (сервис в составе облачной платформы Microsoft Azure).
На самом деле «основные» модели в ArangoDB и OrientDB есть. Это в том и в другом случае собственные модели данных, являющиеся обобщениями документной. Обобщения заключаются в основном в облегчении возможности производить запросы графового и реляционного характера.
Эти модели являются в указанных СУБД единственно доступными для использования, для работы с ними предназначены собственные языки запросов. Безусловно, такие модели и СУБД перспективны, однако отсутствие совместимости со стандартными моделями и языками делает невозможным использование этих СУБД в унаследованных системах — замену ими уже используемых там СУБД.
Про ArangoDB и OrientDB на Хабре уже была замечательная статья: JOIN в NoSQL базах данных.
ArangoDB
ArangoDB заявляет поддержку графовой модели данных.
Узлы графа в ArangoDB — это обычные документы, а ребра — документы специального вида, имеющие наряду с обычными системными полями (, , ) системные поля и . Документы в документных СУБД традиционно объединяются в коллекции. Коллекции документов, представляющих ребра, в ArangoDB называются edge-коллекциями. К слову, документы edge-коллекций — это тоже документы, поэтому ребра в ArangoDB могут выступать также и узлами.
OrientDB
В основе реализации графовой модели поверх документной в OrientDB лежит возможность полей документов иметь помимо более-менее стандартных скалярных значений еще и значения таких типов, как , , , и . Значения этих типов — ссылки или коллекции ссылок на системные идентификаторы документов.







Присваиваемый системой идентификатор документа имеет «физический смысл», указывая позицию записи в базе, и выглядит примерно так: . Тем самым значения ссылочных свойств — действительно скорее указатели (как в графовой модели), а не условия отбора (как в реляционной).
Как и в ArangoDB, в OrientDB ребра представляются отдельными документами (хотя если у ребра нет своих свойств, его можно сделать легковесным, и ему не будет соответствовать отдельный документ).
Azure CosmosDB
В меньшей степени сказанное выше об ArangoDB и OrientDB относится к Azure CosmosDB. CosmosDB предоставляет следующие API доступа к данным: SQL, MongoDB, Gremlin и Cassandra.
SQL API и MongoDB API используются для доступа к данным в документной модели. Gremlin API и Cassandra API — для доступа к данным соответственно в графовой и колоночной. Данные во всех моделях сохраняются в формате внутренней модели CosmosDB: ARS («atom-record-sequence»), которая также близка к документной.
Но выбранная пользователем модель данных и используемый API фиксируются в момент создания аккаунта в сервисе. Невозможно получить доступ к данным, загруженным в одной модели, в формате другой модели, что иллюстрировалось бы примерно таким рисунком:
Тем самым мультимодельность в Azure CosmosDB на сегодняшний день представляет собой лишь возможность использовать несколько баз данных, поддерживающих различные модели, от одного производителя, что не решает всех проблем многовариантного хранения.







